为何 SQLite 性能调优让 Bencher 加速了 1200 倍

Everett Pompeii
上周,我收到了一位用户的反馈,说他们的 Bencher 性能页面加载速度很慢。 所以我决定去看看,哦,天哪,他们说得太客气了。 加载速度慢得尴尬! 尤其是对于领先的持续性能基准测试工具来说。
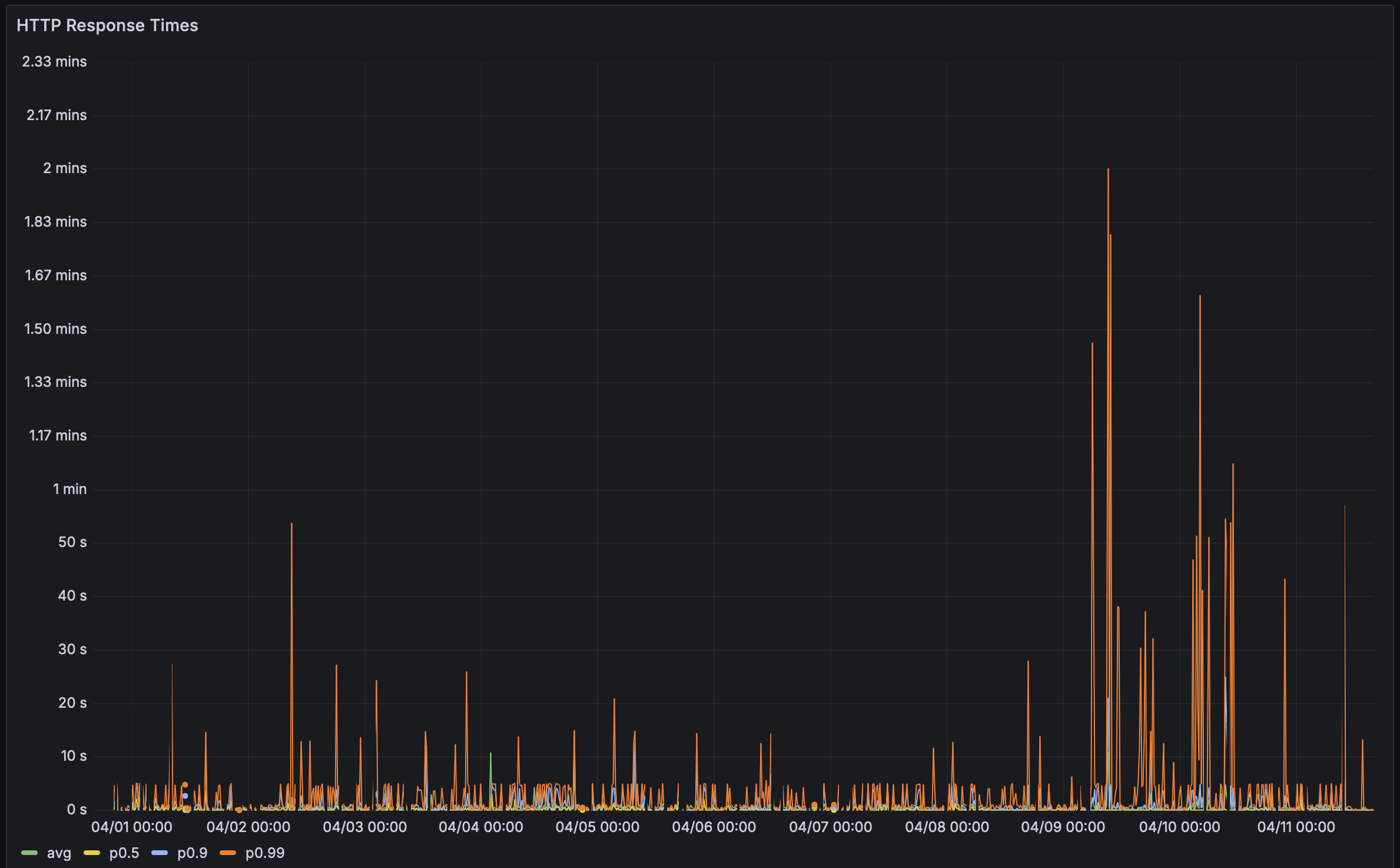
在过去,我常把Rustls 性能页面作为我的试金石。 他们有112个基准测试,并且拥有其中最令人印象深刻的持续性能基准测试设置。 它过去加载大约需要5秒钟。这次却花了… ⏳👀 … 38.8秒! 面对这样的延迟,我不得不深入研究。毕竟,性能问题也是bug!
背景
从一开始,我就知道 Bencher Perf API 将会是性能要求最高的一个端点之一。我认为许多人不得不重新发明基准跟踪轮子的主要原因是,现有的现成工具无法处理所需的高维度。所谓“高维度”,我指的是能够随时间和跨多个维度跟踪性能:分支、测试床、基准测试和度量。这种能力在五个不同维度上进行切分和切块导致了一个非常复杂的模型。
由于这种固有的复杂性和数据的性质,我考虑使用时间序列数据库来实现Bencher。但最终,我决定使用SQLite。我认为,做一些不可扩展的事情比花额外的时间学习一个全新的数据库架构(这个架构可能有帮助,也可能没有)要好。
随着时间的推移,对Bencher Perf API的需求也增加了。最初,你必须手动选择你想绘制的所有维度。这为用户创造了许多摩擦,使他们难以得到一个有用的绘图。为了解决这个问题,我在Perf页面中添加了最新报告的列表,并且默认情况下,最新的报告会被选择和绘制。这意味着,如果最新报告中有112个基准测试,那么所有112个都会被绘制。模型通过能够跟踪和可视化阈值边界变得更加复杂。
考虑到这一点,我进行了一些与性能相关的改进。由于Perf绘图需要最新的报告来开始绘制,我重构了报告API,使得可以通过一次对数据库的调用而不是迭代来获取报告的结果数据。默认报告查询的时间窗口设置为四周,而不是无限制。我还大大限制了所有数据库句柄的范围,减少了锁竞争。为了帮助向用户通信,我为Perf绘图和维度标签页都添加了状态栏旋转器。
去年秋天,我尝试使用一个复合查询来获取所有Perf结果的单个查询,而不是使用四重嵌套循环,但这次尝试失败了。这导致我触及了Rust类型系统递归限制,反复溢出栈,遭受疯狂的(远超38秒的)编译时间,最终因SQLite在复合选择语句中的最大术语数限制而陷入僵局。
经历了这一切后,我知道我真的需要在这里深入挖掘,并穿上我的性能工程师裤子。我之前从未对SQLite数据库进行过性能分析,说实话,我之前实际上从未对任何数据库进行过性能分析。这时候你可能会想,我的LinkedIn资料显示我曾经做了近两年的“数据库管理员”。而我_从未_对数据库进行过分析?是的。我想这是另一个可以讲的故事了。
从 ORM 到 SQL 查询
我遇到的第一个障碍是如何从我的 Rust 代码中获取 SQL 查询。 我使用 Diesel 作为 Bencher 的对象关系映射器(ORM)。
🐰 趣事:Diesel 使用 Bencher 进行相对连续的基准测试。 查看 Diesel 性能页面!
Diesel 创建参数化查询。
它将 SQL 查询及其绑定参数分别发送到数据库。
也就是说,替换由数据库完成。
因此,Diesel 无法向用户提供完整的查询。
我找到的最佳方法是使用 the diesel::debug_query function 来输出参数化查询:
Query { sql: "SELECT `branch`.`id`, `branch`.`uuid`, `branch`.`project_id`, `branch`.`name`, `branch`.`slug`, `branch`.`start_point_id`, `branch`.`created`, `branch`.`modified`, `testbed`.`id`, `testbed`.`uuid`, `testbed`.`project_id`, `testbed`.`name`, `testbed`.`slug`, `testbed`.`created`, `testbed`.`modified`, `benchmark`.`id`, `benchmark`.`uuid`, `benchmark`.`project_id`, `benchmark`.`name`, `benchmark`.`slug`, `benchmark`.`created`, `benchmark`.`modified`, `measure`.`id`, `measure`.`uuid`, `measure`.`project_id`, `measure`.`name`, `measure`.`slug`, `measure`.`units`, `measure`.`created`, `measure`.`modified`, `report`.`uuid`, `report_benchmark`.`iteration`, `report`.`start_time`, `report`.`end_time`, `version`.`number`, `version`.`hash`, `threshold`.`id`, `threshold`.`uuid`, `threshold`.`project_id`, `threshold`.`measure_id`, `threshold`.`branch_id`, `threshold`.`testbed_id`, `threshold`.`model_id`, `threshold`.`created`, `threshold`.`modified`, `model`.`id`, `model`.`uuid`, `model`.`threshold_id`, `model`.`test`, `model`.`min_sample_size`, `model`.`max_sample_size`, `model`.`window`, `model`.`lower_boundary`, `model`.`upper_boundary`, `model`.`created`, `model`.`replaced`, `boundary`.`id`, `boundary`.`uuid`, `boundary`.`threshold_id`, `boundary`.`model_id`, `boundary`.`metric_id`, `boundary`.`baseline`, `boundary`.`lower_limit`, `boundary`.`upper_limit`, `alert`.`id`, `alert`.`uuid`, `alert`.`boundary_id`, `alert`.`boundary_limit`, `alert`.`status`, `alert`.`modified`, `metric`.`id`, `metric`.`uuid`, `metric`.`report_benchmark_id`, `metric`.`measure_id`, `metric`.`value`, `metric`.`lower_value`, `metric`.`upper_value` FROM (((`metric` INNER JOIN ((`report_benchmark` INNER JOIN ((`report` INNER JOIN (`version` INNER JOIN (`branch_version` INNER JOIN `branch` ON (`branch_version`.`branch_id` = `branch`.`id`)) ON (`branch_version`.`version_id` = `version`.`id`)) ON (`report`.`version_id` = `version`.`id`)) INNER JOIN `testbed` ON (`report`.`testbed_id` = `testbed`.`id`)) ON (`report_benchmark`.`report_id` = `report`.`id`)) INNER JOIN `benchmark` ON (`report_benchmark`.`benchmark_id` = `benchmark`.`id`)) ON (`metric`.`report_benchmark_id` = `report_benchmark`.`id`)) INNER JOIN `measure` ON (`metric`.`measure_id` = `measure`.`id`)) LEFT OUTER JOIN (((`boundary` INNER JOIN `threshold` ON (`boundary`.`threshold_id` = `threshold`.`id`)) INNER JOIN `model` ON (`boundary`.`model_id` = `model`.`id`)) LEFT OUTER JOIN `alert` ON (`alert`.`boundary_id` = `boundary`.`id`)) ON (`boundary`.`metric_id` = `metric`.`id`)) WHERE ((((((`branch`.`uuid` = ?) AND (`testbed`.`uuid` = ?)) AND (`benchmark`.`uuid` = ?)) AND (`measure`.`uuid` = ?)) AND (`report`.`start_time` >= ?)) AND (`report`.`end_time` <= ?)) ORDER BY `version`.`number`, `report`.`start_time`, `report_benchmark`.`iteration`", binds: [BranchUuid(a7d8366a-4f9b-452e-987e-2ae56e4bf4a3), TestbedUuid(5b4a6f3e-a27d-4cc3-a2ce-851dc6421e6e), BenchmarkUuid(88375e7c-f1e0-4cbb-bde1-bdb7773022ae), MeasureUuid(b2275bbc-2044-4f8e-aecd-3c739bd861b9), DateTime(2024-03-12T12:23:38Z), DateTime(2024-04-11T12:23:38Z)] }然后手动清理并参数化查询为有效的 SQL:
SELECT branch.id, branch.uuid, branch.project_id, branch.name, branch.slug, branch.start_point_id, branch.created, branch.modified, testbed.id, testbed.uuid, testbed.project_id, testbed.name, testbed.slug, testbed.created, testbed.modified, benchmark.id, benchmark.uuid, benchmark.project_id, benchmark.name, benchmark.slug, benchmark.created, benchmark.modified, measure.id, measure.uuid, measure.project_id, measure.name, measure.slug, measure.units, measure.created, measure.modified, report.uuid, report_benchmark.iteration, report.start_time, report.end_time, version.number, version.hash, threshold.id, threshold.uuid, threshold.project_id, threshold.measure_id, threshold.branch_id, threshold.testbed_id, threshold.model_id, threshold.created, threshold.modified, model.id, model.uuid, model.threshold_id, model.test, model.min_sample_size, model.max_sample_size, model.window, model.lower_boundary, model.upper_boundary, model.created, model.replaced, boundary.id, boundary.uuid, boundary.threshold_id, boundary.model_id, boundary.metric_id, boundary.baseline, boundary.lower_limit, boundary.upper_limit, alert.id, alert.uuid, alert.boundary_id, alert.boundary_limit, alert.status, alert.modified, metric.id, metric.uuid, metric.report_benchmark_id, metric.measure_id, metric.value, metric.lower_value, metric.upper_value FROM (((metric INNER JOIN ((report_benchmark INNER JOIN ((report INNER JOIN (version INNER JOIN (branch_version INNER JOIN branch ON (branch_version.branch_id = branch.id)) ON (branch_version.version_id = version.id)) ON (report.version_id = version.id)) INNER JOIN testbed ON (report.testbed_id = testbed.id)) ON (report_benchmark.report_id = report.id)) INNER JOIN benchmark ON (report_benchmark.benchmark_id = benchmark.id)) ON (metric.report_benchmark_id = report_benchmark.id)) INNER JOIN measure ON (metric.measure_id = measure.id)) LEFT OUTER JOIN (((boundary INNER JOIN threshold ON (boundary.threshold_id = threshold.id)) INNER JOIN model ON (boundary.model_id = model.id)) LEFT OUTER JOIN alert ON (alert.boundary_id = boundary.id)) ON (boundary.metric_id = metric.id)) WHERE ((((((branch.uuid = 'a7d8366a-4f9b-452e-987e-2ae56e4bf4a3') AND (testbed.uuid = '5b4a6f3e-a27d-4cc3-a2ce-851dc6421e6e')) AND (benchmark.uuid = '88375e7c-f1e0-4cbb-bde1-bdb7773022ae')) AND (measure.uuid = 'b2275bbc-2044-4f8e-aecd-3c739bd861b9')) AND (report.start_time >= 0)) AND (report.end_time <= 1712838648197)) ORDER BY version.number, report.start_time, report_benchmark.iteration;如果您知道更好的方法,请告诉我! 这是项目维护者建议的方法, 所以我就采用了这种方法。 现在我已经有了一个 SQL 查询,我终于准备好了…阅读大量的文档。
SQLite 查询规划器
SQLite 官网有一份关于其查询规划器的极佳文档。 它详细解释了 SQLite 是如何执行您的 SQL 查询的, 并教您哪些索引有用,以及需要注意的操作,如全表扫描。
为了看到查询规划器是如何执行我的 Perf 查询的,
我需要向我的工具包中添加一个新工具:EXPLAIN QUERY PLAN
您可以在 SQL 查询前加上 EXPLAIN QUERY PLAN
或在查询前运行 .eqp on 命令。
无论哪种方式,我都得到了这样的结果:
QUERY PLAN|--MATERIALIZE (join-5)| |--SCAN boundary| |--SEARCH threshold USING INTEGER PRIMARY KEY (rowid=?)| |--SEARCH model USING INTEGER PRIMARY KEY (rowid=?)| |--BLOOM FILTER ON alert (boundary_id=?)| `--SEARCH alert USING AUTOMATIC COVERING INDEX (boundary_id=?) LEFT-JOIN|--SEARCH branch USING INDEX sqlite_autoindex_branch_1 (uuid=?)|--SEARCH measure USING INDEX sqlite_autoindex_measure_1 (uuid=?)|--SEARCH benchmark USING INDEX sqlite_autoindex_benchmark_1 (uuid=?)|--SEARCH testbed USING INDEX sqlite_autoindex_testbed_1 (uuid=?)|--SCAN metric|--SEARCH report_benchmark USING INTEGER PRIMARY KEY (rowid=?)|--SEARCH report USING INTEGER PRIMARY KEY (rowid=?)|--SEARCH version USING INTEGER PRIMARY KEY (rowid=?)|--SEARCH branch_version USING COVERING INDEX sqlite_autoindex_branch_version_1 (branch_id=? AND version_id=?)|--BLOOM FILTER ON (join-5) (metric_id=?)|--SEARCH (join-5) USING AUTOMATIC COVERING INDEX (metric_id=?) LEFT-JOIN`--USE TEMP B-TREE FOR ORDER BY噢,天哪! 这里有很多内容。 但有三件大事跃然纸上:
- SQLite 即时创建了一个物化视图,它扫描了整个
boundary表 - SQLite 然后扫描了整个
metric表 - SQLite 即时创建了两个索引
那么 metric 和 boundary 表有多大呢?
它们恰好是两个最大的表,
因为它们存储了所有的指标和边界。
由于这是我第一次进行 SQLite 性能调优, 我想在做出任何改变之前咨询一个专家。
SQLite 专家模式
SQLite 有一个实验性的“专家”模式,可以通过.expert 命令启用。
它会为查询建议索引,因此我决定尝试一下。
这是它的建议:
CREATE INDEX report_benchmark_idx_fc6f3e5b ON report_benchmark(report_id, benchmark_id);CREATE INDEX report_idx_55aae6d8 ON report(testbed_id, end_time);CREATE INDEX alert_idx_e1882f70 ON alert(boundary_id);
MATERIALIZE (join-5)SCAN boundarySEARCH threshold USING INTEGER PRIMARY KEY (rowid=?)SEARCH model USING INTEGER PRIMARY KEY (rowid=?)SEARCH alert USING INDEX alert_idx_e1882f70 (boundary_id=?) LEFT-JOINSEARCH branch USING INDEX sqlite_autoindex_branch_1 (uuid=?)SEARCH benchmark USING INDEX sqlite_autoindex_benchmark_1 (uuid=?)SEARCH testbed USING INDEX sqlite_autoindex_testbed_1 (uuid=?)SEARCH measure USING INDEX sqlite_autoindex_measure_1 (uuid=?)SEARCH report USING INDEX report_idx_55aae6d8 (testbed_id=? AND end_time<?)SEARCH version USING INTEGER PRIMARY KEY (rowid=?)SEARCH branch_version USING COVERING INDEX sqlite_autoindex_branch_version_1 (branch_id=? AND version_id=?)SEARCH report_benchmark USING INDEX report_benchmark_idx_fc6f3e5b (report_id=? AND benchmark_id=?)SEARCH metric USING INDEX sqlite_autoindex_metric_2 (report_benchmark_id=? AND measure_id=?)BLOOM FILTER ON (join-5) (metric_id=?)SEARCH (join-5) USING AUTOMATIC COVERING INDEX (metric_id=?) LEFT-JOINUSE TEMP B-TREE FOR ORDER BY这绝对是一个提升!
它消除了对 metric 表的扫描和两个即时索引。
老实说,我自己不会想到前两个索引。
谢谢你,SQLite 专家!
CREATE INDEX index_report_testbed_end_time ON report(testbed_id, end_time);CREATE INDEX index_report_benchmark ON report_benchmark(report_id, benchmark_id);CREATE INDEX index_alert_boundary ON alert(boundary_id);现在唯一需要解决的就是那个讨厌的即时物化视图了。
物化视图
去年我增加了追踪和可视化阈值边界的能力时,我在数据库模型上面临了一个决定。
度量(Metric)与其相应的边界(Boundary)之间存在 1 至 0/1 的关系。即一个度量可以与零个或一个边界相关联,而一个边界只能与一个度量相关联。
我本可以只扩展 metric 表格来包含所有的 boundary 数据,其中每个与 boundary 相关的字段都可以为空。
或者我可以创建一个单独的 boundary 表格,其中包含指向 metric 表格的 UNIQUE 外键。
对我来说,后一种选项感觉更干净,而且我想我总是可以稍后解决任何性能问题。
以下是用来创建 metric 和 boundary 表格的有效查询:
CREATE TABLE metric ( id INTEGER PRIMARY KEY NOT NULL, uuid TEXT NOT NULL UNIQUE, report_benchmark_id INTEGER NOT NULL, measure_id INTEGER NOT NULL, value DOUBLE NOT NULL, lower_value DOUBLE, upper_value DOUBLE, FOREIGN KEY (report_benchmark_id) REFERENCES report_benchmark (id) ON DELETE CASCADE, FOREIGN KEY (measure_id) REFERENCES measure (id), UNIQUE(report_benchmark_id, measure_id));CREATE TABLE boundary ( id INTEGER PRIMARY KEY NOT NULL, uuid TEXT NOT NULL UNIQUE, threshold_id INTEGER NOT NULL, statistic_id INTEGER NOT NULL, metric_id INTEGER NOT NULL UNIQUE, baseline DOUBLE NOT NULL, lower_limit DOUBLE, upper_limit DOUBLE, FOREIGN KEY (threshold_id) REFERENCES threshold (id), FOREIGN KEY (statistic_id) REFERENCES statistic (id), FOREIGN KEY (metric_id) REFERENCES metric (id) ON DELETE CASCADE);结果证明,“稍后”到了。
我尝试简单地为 boundary(metric_id) 添加一个索引,但这没有帮助。
我相信原因与 Perf 查询是从 metric 表格起始,因为那种关系是 0/1,或换句话说,是可空的,所以它必须被扫描(O(n))
而不能被搜索(O(log(n)))。
这给我留下了一个明确的选项。
我需要创建一个物化视图,将 metric 和 boundary 的关系扁平化,
以防止 SQLite 不得不创建一个即时的物化视图。
以下是我用来创建新的 metric_boundary 物化视图的查询:
CREATE VIEW metric_boundary ASSELECT metric.id AS metric_id, metric.uuid AS metric_uuid, metric.report_benchmark_id, metric.measure_id, metric.value, metric.lower_value, metric.upper_value, boundary.id, boundary.uuid AS boundary_uuid, boundary.threshold_id AS threshold_id, boundary.model_id, boundary.baseline, boundary.lower_limit, boundary.upper_limitFROM metric LEFT OUTER JOIN boundary ON (boundary.metric_id = metric.id);通过这个解决方案,我在运行时性能与空间之间进行了权衡。 需要多少空间? 令人惊讶的是,即使这个视图是数据库中两个最大表的,其空间增量也仅约 4%。 最重要的是,它让我在我的源代码中既得到我的蛋糕,又能吃到它。
使用 Diesel 创建物化视图diesel view出奇地简单。 我只需使用 Diesel 在生成我的正常架构时使用的完全相同的宏。 话虽如此,通过这次经验我对 Diesel 的欣赏更深了。 查看额外的 Bug 获取所有精彩的细节。
总结
在添加了三个新索引和一个物化视图之后,查询规划器现在显示的是这样的:
QUERY PLAN|--SEARCH branch USING INDEX sqlite_autoindex_branch_1 (uuid=?)|--SEARCH testbed USING INDEX sqlite_autoindex_testbed_1 (uuid=?)|--SEARCH benchmark USING INDEX sqlite_autoindex_benchmark_1 (uuid=?)|--SEARCH measure USING INDEX sqlite_autoindex_measure_1 (uuid=?)|--SEARCH report USING INDEX index_report_testbed_end_time (testbed_id=? AND end_time<?)|--SEARCH version USING INTEGER PRIMARY KEY (rowid=?)|--SEARCH branch_version USING COVERING INDEX sqlite_autoindex_branch_version_1 (branch_id=? AND version_id=?)|--SEARCH report_benchmark USING INDEX index_report_benchmark (report_id=? AND benchmark_id=?)|--SEARCH metric USING INDEX sqlite_autoindex_metric_2 (report_benchmark_id=? AND measure_id=?)|--SEARCH boundary USING INDEX sqlite_autoindex_boundary_2 (metric_id=?) LEFT-JOIN|--SEARCH threshold USING INTEGER PRIMARY KEY (rowid=?) LEFT-JOIN|--SEARCH model USING INTEGER PRIMARY KEY (rowid=?) LEFT-JOIN|--SEARCH alert USING INDEX index_alert_boundary (boundary_id=?) LEFT-JOIN`--USE TEMP B-TREE FOR ORDER BY看看这些美丽的SEARCH操作,都用上了现有的索引!🥲
部署我的更改到生产环境后:
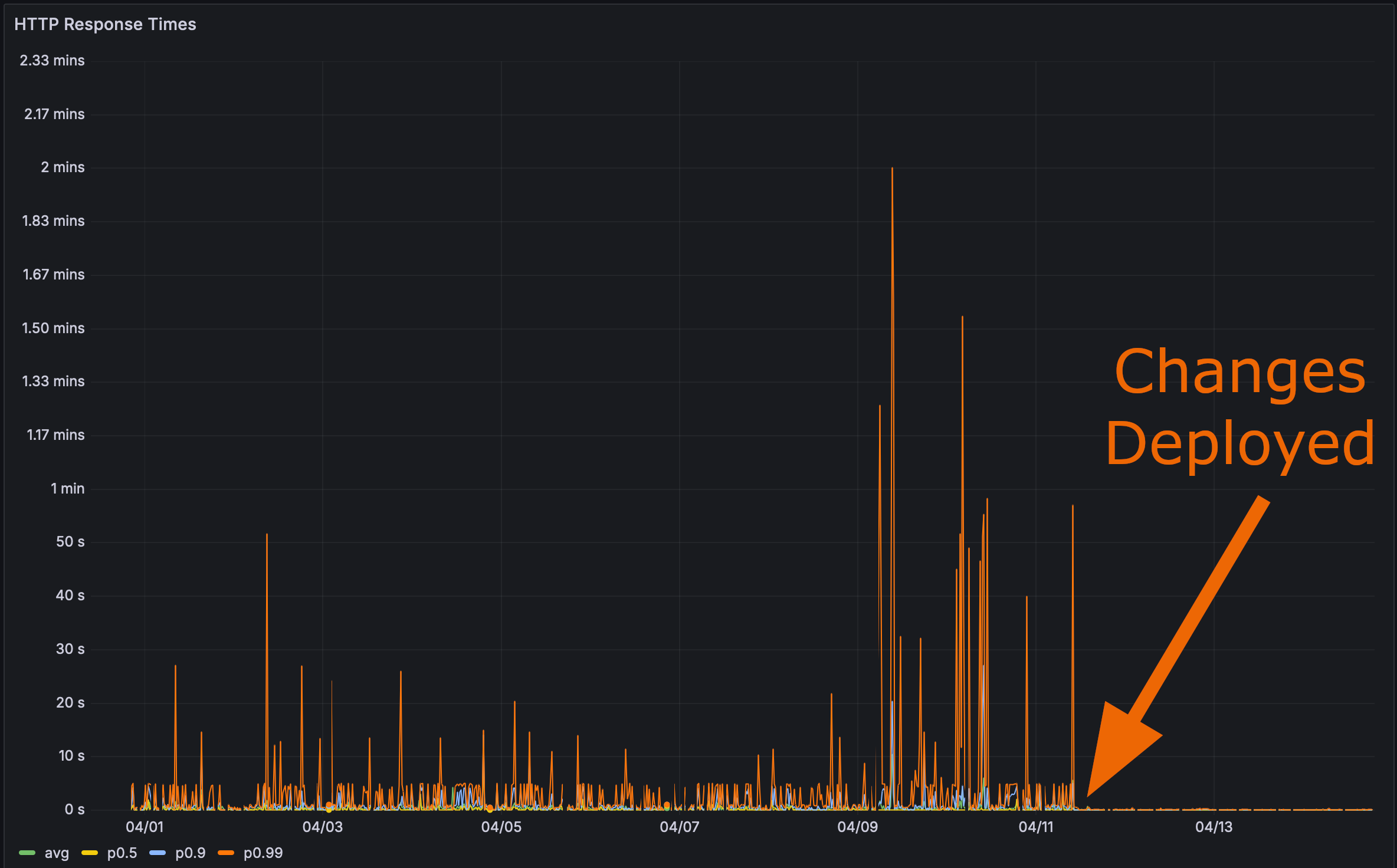
现在是进行最终测试的时候了。 Rustls性能页面加载得有多快?
在这里我甚至给你一个锚点标签。点击它然后刷新页面。
性能很重要
Bencher: 持续性能基准测试

Bencher是一套持续基准测试工具。 你是否曾经因为性能回归影响到了你的用户? Bencher可以防止这种情况的发生。 Bencher让你有能力在性能回归被合并 之前 就进行检测和预防。
- 运行: 使用 完全相同 的裸机运行器和你喜爱的基准测试工具,在本地或CI中执行你的基准测试。
bencherCLI在裸机上编排你的基准测试运行并存储其结果。 - 追踪: 追踪你的基准测试结果的趋势。根据源分支、测试床和度量,使用Bencher web控制台来监视、查询和绘制结果图表。
- 捕获: 使用 完全相同 的裸机硬件,在本地或CI中捕获性能回归。Bencher使用最先进的、可定制的分析技术在它们被合并之前就检测到性能回归。
基于防止功能回归的原因运行单元测试,我们也应该使用Bencher运行基准测试以防止性能回归。性能问题就是错误!
开始捕捉性能回归 — 免费试用Bencher Cloud。
自我使用附录
我已经在使用 Bencher 自测 Bencher, 但所有现有的基准测试适配器都是针对微基准测试适配器。 大多数 HTTP 适配器实际上都是负载测试适配器, 而负载测试与基准测试不同。 更进一步,我暂时不打算将 Bencher 扩展到负载测试。 那是一个非常不同的用例,需要非常不同的设计考虑, 例如,时间序列数据库实例。 即便我实施了负载测试, 为了发现这个问题,我真的需要针对最新抽取的生产数据进行测试。 这些更改对我的测试数据库的性能差异可以忽略不计。
点击查看测试数据库基准测试结果
更改前:
Run Time: real 0.081 user 0.019532 sys 0.005618Run Time: real 0.193 user 0.022192 sys 0.003368Run Time: real 0.070 user 0.021390 sys 0.003369Run Time: real 0.062 user 0.022676 sys 0.002290Run Time: real 0.057 user 0.012053 sys 0.006638Run Time: real 0.052 user 0.018797 sys 0.002016Run Time: real 0.059 user 0.022806 sys 0.002437Run Time: real 0.066 user 0.021869 sys 0.004525Run Time: real 0.060 user 0.021037 sys 0.002864Run Time: real 0.059 user 0.018397 sys 0.003668添加索引和物化视图后:
Run Time: real 0.063 user 0.008671 sys 0.004898Run Time: real 0.053 user 0.010671 sys 0.003334Run Time: real 0.053 user 0.010337 sys 0.002884Run Time: real 0.052 user 0.008087 sys 0.002165Run Time: real 0.045 user 0.007265 sys 0.002123Run Time: real 0.038 user 0.008793 sys 0.002240Run Time: real 0.040 user 0.011022 sys 0.002420Run Time: real 0.049 user 0.010004 sys 0.002831Run Time: real 0.059 user 0.010472 sys 0.003661Run Time: real 0.046 user 0.009968 sys 0.002628这一切让我相信,我应该创建一个针对 Perf API 端点运行的微基准测试,并且使用 Bencher 自测结果。 这将需要一个相当大的测试数据库 来保证这类性能回滚在 CI 中被捕获。 如果您想跟进,我已经为这项工作创建了一个追踪问题。
这一切都让我思考: 如果你能对你的 SQL 数据库查询计划进行快照测试怎么样? 也就是说,你可以比较你当前的与候选的 SQL 数据库查询计划。 SQL 查询计划测试有点像是数据库的基于指令计数的基准测试。 查询计划有助于指出运行性能可能存在的问题, 而无需实际对数据库查询进行基准测试。 我也为此创建了一个追踪问题。 请随时添加评论,分享您的想法或您所知道的任何现有作品!
额外的错误
我最初在我的物化视图代码中遇到了一个错误。 SQL查询看起来像这样:
SELECT branch.id, branch.uuid, branch.project_id, branch.name, branch.slug, branch.start_point_id, branch.created, branch.modified, testbed.id, testbed.uuid, testbed.project_id, testbed.name, testbed.slug, testbed.created, testbed.modified, benchmark.id, benchmark.uuid, benchmark.project_id, benchmark.name, benchmark.slug, benchmark.created, benchmark.modified, measure.id, measure.uuid, measure.project_id, measure.name, measure.slug, measure.units, measure.created, measure.modified, report.uuid, report_benchmark.iteration, report.start_time, report.end_time, version.number, version.hash, threshold.id, threshold.uuid, threshold.project_id, threshold.measure_id, threshold.branch_id, threshold.testbed_id, threshold.model_id, threshold.created, threshold.modified, model.id, model.uuid, model.threshold_id, model.test, model.min_sample_size, model.max_sample_size, model.window, model.lower_boundary, model.upper_boundary, model.created, model.replaced, alert.id, alert.uuid, alert.boundary_id, alert.boundary_limit, alert.status, alert.modified, metric_boundary.metric_id, metric_boundary.metric_uuid, metric_boundary.report_benchmark_id, metric_boundary.measure_id, metric_boundary.value, metric_boundary.lower_value, metric_boundary.upper_value, metric_boundary.boundary_id, metric_boundary.boundary_uuid, metric_boundary.threshold_id, metric_boundary.model_id, metric_boundary.baseline, metric_boundary.lower_limit, metric_boundary.upper_limit FROM (((((metric_boundary INNER JOIN ((report_benchmark INNER JOIN ((report INNER JOIN (version INNER JOIN (branch_version INNER JOIN branch ON (branch_version.branch_id = branch.id)) ON (branch_version.version_id = version.id)) ON (report.version_id = version.id)) INNER JOIN testbed ON (report.testbed_id = testbed.id)) ON (report_benchmark.report_id = report.id)) INNER JOIN benchmark ON (report_benchmark.benchmark_id = benchmark.id)) ON (metric_boundary.report_benchmark_id = report_benchmark.id)) INNER JOIN measure ON (metric_boundary.measure_id = measure.id)) LEFT OUTER JOIN threshold ON (metric_boundary.threshold_id = threshold.id)) LEFT OUTER JOIN model ON (metric_boundary.model_id = model.id)) LEFT OUTER JOIN alert ON (alert.boundary_id = metric_boundary.metric_id)) WHERE ((((((branch.uuid = 'a7d8366a-4f9b-452e-987e-2ae56e4bf4a3') AND (testbed.uuid = '5b4a6f3e-a27d-4cc3-a2ce-851dc6421e6e')) AND (benchmark.uuid = '88375e7c-f1e0-4cbb-bde1-bdb7773022ae')) AND (measure.uuid = 'b2275bbc-2044-4f8e-aecd-3c739bd861b9')) AND (report.start_time >= 0)) AND (report.end_time <= 1712838648197)) ORDER BY version.number, report.start_time, report_benchmark.iteration;你看出问题了吗?没有。我也没有!
问题就出在这里:
LEFT OUTER JOIN alert ON (alert.boundary_id = metric_boundary.metric_id)实际上,它应该是:
LEFT OUTER JOIN alert ON (alert.boundary_id = metric_boundary.boundary_id)我尝试过于聪明, 并且在我的Diesel物化视图架构中允许了这种连接:
diesel::joinable!(alert -> metric_boundary (boundary_id));我假设这个宏在某种程度上足够智能,
能够将alert.boundary_id与metric_boundary.boundary_id关联起来。
但遗憾的是,它并不是。
看来它仅仅选择了metric_boundary的第一列(metric_id)来与alert关联。
一旦我发现了这个错误,修复就变得容易了。 我只需要在Perf查询中使用显式连接:
.left_join(schema::alert::table.on(view::metric_boundary::boundary_id.eq(schema::alert::boundary_id.nullable())))🐰 就是这些了!