Почему настройка производительности SQLite сделала Bencher на 1200x быстрее

Everett Pompeii
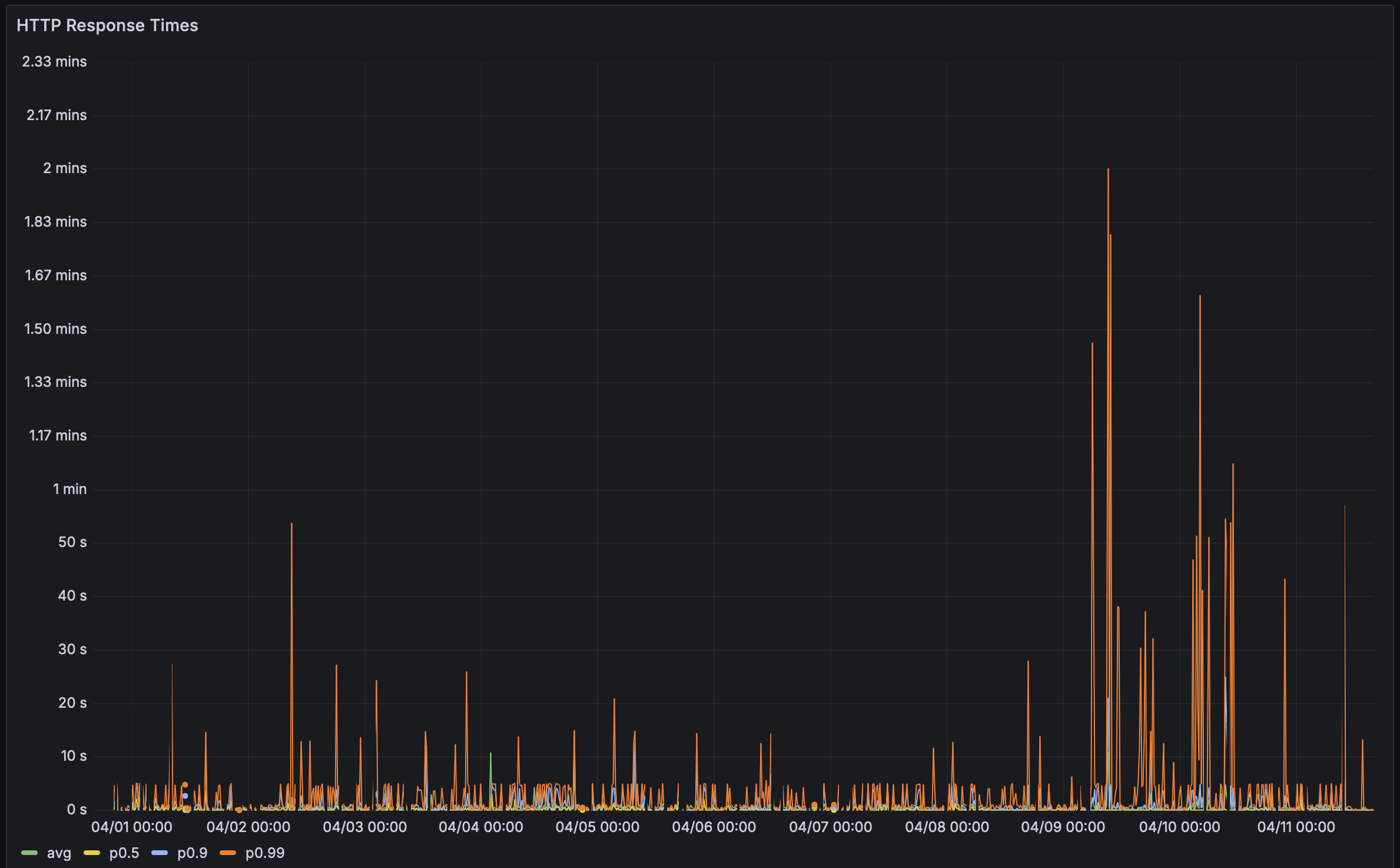
На прошлой неделе я получил отзыв от пользователя, что их страница производительности Bencher загружается довольно долго. Поэтому я решил проверить, и о, боже, они были слишком вежливы. Загрузка занимала уйму времени! Неприлично долго. Особенно для ведущего инструмента Непрерывного Бенчмаркинга.
Ранее я использовал страницу производительности Rustls в качестве лакмусовой бумажки. У них 112 бенчмарков и одна из самых впечатляющих настроек Непрерывного Бенчмаркинга. Раньше она загружалась около 5 секунд. На этот раз заняло… ⏳👀 … 38,8 секунд! С такой задержкой мне пришлось вникнуть в детали. В конце концов, проблемы с производительностью тоже баги!
Фон
С самого начала я знал, что API Bencher Perf будет одним из самых требовательных к производительности конечных точек. Я считаю, что основная причина, по которой многим приходилось изобретать колесо отслеживания бенчмарков заново, заключается в том, что существующие инструменты “из коробки” не справляются с необходимой высокой размерностью. Под “высокой размерностью” я понимаю возможность отслеживания производительности во времени и по нескольким измерениям: Ветвлениям, Тестовым стендам, Бенчмаркам и Метрикам. Эта возможность анализа данных по пяти различным измерениям приводит к очень сложной модели.
Именно из-за этой врожденной сложности и специфики данных я рассматривал возможность использования временной базы данных для Bencher. Однако в итоге я остановил свой выбор на SQLite. Я решил, что лучше делать вещи, которые не масштабируются, чем тратить дополнительное время на изучение совершенно новой архитектуры базы данных, которая может и не помочь.
С течением времени требования к API Bencher Perf также возросли. Изначально вы должны были вручную выбрать все измерения, которые хотели визуализировать. Это создавало много трудностей для пользователей при попытке получить полезный график. Чтобы решить эту проблему, я добавил список самых последних отчетов на страницы Perf, и по умолчанию выбирался и отображался самый последний отчет. Это означало, что если в самом последнем отчете было 112 бенчмарков, то они все были бы визуализированы. Модель стала еще более сложной с возможностью отслеживания и визуализации границ порогов.
Имея это в виду, я внес несколько улучшений, связанных с производительностью. Поскольку для начала визуализации графика Perf требовался самый последний отчет, я рефакторил API отчетов, чтобы получить данные результатов отчета одним вызовом к базе данных, вместо итерации. Временное окно для запроса отчета по умолчанию было установлено в четыре недели, вместо неограниченного. Я также значительно ограничил область всех дескрипторов базы данных, уменьшив конфликт блокировок. Чтобы помочь в общении с пользователями, я добавил индикатор состояния для графика Perf и вкладок измерений.
У меня также была неудачная попытка осенью использовать комбинированный запрос для получения всех результатов Perf одним запросом, вместо использования четырехкратного вложенного цикла. Это привело к тому, что я достиг лимита рекурсии типовой системы Rust, постоянно переполнял стек, страдал из-за безумно долгих (намного более 38 секунд) времен компиляции и, наконец, зашел в тупик из-за максимального количества терминов в составном выражении выборки SQLite.
Со всем этим на своем счету, я знал, что мне действительно нужно здесь копнуть глубже и надеть штаны инженера по производительности. Я никогда раньше не профилировал базу данных SQLite, и, честно говоря, я никогда не профилировал никакую базу данных до этого. Теперь подождите-ка, вы можете подумать. Мой профиль в LinkedIn говорит, что я был “Администратором баз данных” почти два года. И я никогда не профилировал базу данных‽ Да, это история на другой раз, предполагаю.
От ORM к SQL запросу
Первое препятствие, с которым я столкнулся, это извлечение SQL запроса из моего кода на Rust. Я использую Diesel в качестве объектно-реляционного маппера (ORM) для Bencher.
🐰 Интересный факт: Diesel использует Bencher для их Относительного непрерывного бенчмаркинга. Посмотрите страницу производительности Diesel!
Diesel создает параметризованные запросы. Он отправляет SQL запрос и его параметры привязки отдельно в базу данных. То есть, подстановка выполняется базой данных. Поэтому Diesel не может предоставить пользователю полный запрос. Лучший метод, который я нашел, - использование функции diesel::debug_query для вывода параметризованного запроса:
Query { sql: "SELECT `branch`.`id`, `branch`.`uuid`, `branch`.`project_id`, `branch`.`name`, `branch`.`slug`, `branch`.`start_point_id`, `branch`.`created`, `branch`.`modified`, `testbed`.`id`, `testbed`.`uuid`, `testbed`.`project_id`, `testbed`.`name`, `testbed`.`slug`, `testbed`.`created`, `testbed`.`modified`, `benchmark`.`id`, `benchmark`.`uuid`, `benchmark`.`project_id`, `benchmark`.`name`, `benchmark`.`slug`, `benchmark`.`created`, `benchmark`.`modified`, `measure`.`id`, `measure`.`uuid`, `measure`.`project_id`, `measure`.`name`, `measure`.`slug`, `measure`.`units`, `measure`.`created`, `measure`.`modified`, `report`.`uuid`, `report_benchmark`.`iteration`, `report`.`start_time`, `report`.`end_time`, `version`.`number`, `version`.`hash`, `threshold`.`id`, `threshold`.`uuid`, `threshold`.`project_id`, `threshold`.`measure_id`, `threshold`.`branch_id`, `threshold`.`testbed_id`, `threshold`.`model_id`, `threshold`.`created`, `threshold`.`modified`, `model`.`id`, `model`.`uuid`, `model`.`threshold_id`, `model`.`test`, `model`.`min_sample_size`, `model`.`max_sample_size`, `model`.`window`, `model`.`lower_boundary`, `model`.`upper_boundary`, `model`.`created`, `model`.`replaced`, `boundary`.`id`, `boundary`.`uuid`, `boundary`.`threshold_id`, `boundary`.`model_id`, `boundary`.`metric_id`, `boundary`.`baseline`, `boundary`.`lower_limit`, `boundary`.`upper_limit`, `alert`.`id`, `alert`.`uuid`, `alert`.`boundary_id`, `alert`.`boundary_limit`, `alert`.`status`, `alert`.`modified`, `metric`.`id`, `metric`.`uuid`, `metric`.`report_benchmark_id`, `metric`.`measure_id`, `metric`.`value`, `metric`.`lower_value`, `metric`.`upper_value` FROM (((`metric` INNER JOIN ((`report_benchmark` INNER JOIN ((`report` INNER JOIN (`version` INNER JOIN (`branch_version` INNER JOIN `branch` ON (`branch_version`.`branch_id` = `branch`.`id`)) ON (`branch_version`.`version_id` = `version`.`id`)) ON (`report`.`version_id` = `version`.`id`)) INNER JOIN `testbed` ON (`report`.`testbed_id` = `testbed`.`id`)) ON (`report_benchmark`.`report_id` = `report`.`id`)) INNER JOIN `benchmark` ON (`report_benchmark`.`benchmark_id` = `benchmark`.`id`)) ON (`metric`.`report_benchmark_id` = `report_benchmark`.`id`)) INNER JOIN `measure` ON (`metric`.`measure_id` = `measure`.`id`)) LEFT OUTER JOIN (((`boundary` INNER JOIN `threshold` ON (`boundary`.`threshold_id` = `threshold`.`id`)) INNER JOIN `model` ON (`boundary`.`model_id` = `model`.`id`)) LEFT OUTER JOIN `alert` ON (`alert`.`boundary_id` = `boundary`.`id`)) ON (`boundary`.`metric_id` = `metric`.`id`)) WHERE ((((((`branch`.`uuid` = ?) AND (`testbed`.`uuid` = ?)) AND (`benchmark`.`uuid` = ?)) AND (`measure`.`uuid` = ?)) AND (`report`.`start_time` >= ?)) AND (`report`.`end_time` <= ?)) ORDER BY `version`.`number`, `report`.`start_time`, `report_benchmark`.`iteration`", binds: [BranchUuid(a7d8366a-4f9b-452e-987e-2ae56e4bf4a3), TestbedUuid(5b4a6f3e-a27d-4cc3-a2ce-851dc6421e6e), BenchmarkUuid(88375e7c-f1e0-4cbb-bde1-bdb7773022ae), MeasureUuid(b2275bbc-2044-4f8e-aecd-3c739bd861b9), DateTime(2024-03-12T12:23:38Z), DateTime(2024-04-11T12:23:38Z)] }А затем вручную очищать и параметризовать запрос для преобразования его в валидный SQL:
SELECT branch.id, branch.uuid, branch.project_id, branch.name, branch.slug, branch.start_point_id, branch.created, branch.modified, testbed.id, testbed.uuid, testbed.project_id, testbed.name, testbed.slug, testbed.created, testbed.modified, benchmark.id, benchmark.uuid, benchmark.project_id, benchmark.name, benchmark.slug, benchmark.created, benchmark.modified, measure.id, measure.uuid, measure.project_id, measure.name, measure.slug, measure.units, measure.created, measure.modified, report.uuid, report_benchmark.iteration, report.start_time, report.end_time, version.number, version.hash, threshold.id, threshold.uuid, threshold.project_id, threshold.measure_id, threshold.branch_id, threshold.testbed_id, threshold.model_id, threshold.created, threshold.modified, model.id, model.uuid, model.threshold_id, model.test, model.min_sample_size, model.max_sample_size, model.window, model.lower_boundary, model.upper_boundary, model.created, model.replaced, boundary.id, boundary.uuid, boundary.threshold_id, boundary.model_id, boundary.metric_id, boundary.baseline, boundary.lower_limit, boundary.upper_limit, alert.id, alert.uuid, alert.boundary_id, alert.boundary_limit, alert.status, alert.modified, metric.id, metric.uuid, metric.report_benchmark_id, metric.measure_id, metric.value, metric.lower_value, metric.upper_value FROM (((metric INNER JOIN ((report_benchmark INNER JOIN ((report INNER JOIN (version INNER JOIN (branch_version INNER JOIN branch ON (branch_version.branch_id = branch.id)) ON (branch_version.version_id = version.id)) ON (report.version_id = version.id)) INNER JOIN testbed ON (report.testbed_id = testbed.id)) ON (report_benchmark.report_id = report.id)) INNER JOIN benchmark ON (report_benchmark.benchmark_id = benchmark.id)) ON (metric.report_benchmark_id = report_benchmark.id)) INNER JOIN measure ON (metric.measure_id = measure.id)) LEFT OUTER JOIN (((boundary INNER JOIN threshold ON (boundary.threshold_id = threshold.id)) INNER JOIN model ON (boundary.model_id = model.id)) LEFT OUTER JOIN alert ON (alert.boundary_id = boundary.id)) ON (boundary.metric_id = metric.id)) WHERE ((((((branch.uuid = 'a7d8366a-4f9b-452e-987e-2ae56e4bf4a3') AND (testbed.uuid = '5b4a6f3e-a27d-4cc3-a2ce-851dc6421e6e')) AND (benchmark.uuid = '88375e7c-f1e0-4cbb-bde1-bdb7773022ae')) AND (measure.uuid = 'b2275bbc-2044-4f8e-aecd-3c739bd861b9')) AND (report.start_time >= 0)) AND (report.end_time <= 1712838648197)) ORDER BY version.number, report.start_time, report_benchmark.iteration;Если вы знаете лучший способ, пожалуйста, сообщите мне! Но это тот способ, который предложил разработчик проекта, так что я просто последовал его совету. Теперь, когда у меня был SQL запрос, я наконец был готов… прочитать очень много документации.
Планировщик запросов SQLite
На сайте SQLite есть отличная документация по планировщику запросов. Она точно объясняет, как SQLite выполняет ваш SQL запрос, и учит, какие индексы полезны и на что стоит обратить внимание, например, на полные сканирования таблиц.
Чтобы увидеть, как планировщик запросов выполнит мой запрос Perf,
мне нужно было добавить новый инструмент в мой арсенал: EXPLAIN QUERY PLAN
Вы можете либо добавить к вашему SQL запросу префикс EXPLAIN QUERY PLAN
или выполнить команду .eqp on перед вашим запросом.
В любом случае, я получил результат, который выглядит так:
QUERY PLAN|--MATERIALIZE (join-5)| |--SCAN boundary| |--SEARCH threshold USING INTEGER PRIMARY KEY (rowid=?)| |--SEARCH model USING INTEGER PRIMARY KEY (rowid=?)| |--BLOOM FILTER ON alert (boundary_id=?)| `--SEARCH alert USING AUTOMATIC COVERING INDEX (boundary_id=?) LEFT-JOIN|--SEARCH branch USING INDEX sqlite_autoindex_branch_1 (uuid=?)|--SEARCH measure USING INDEX sqlite_autoindex_measure_1 (uuid=?)|--SEARCH benchmark USING INDEX sqlite_autoindex_benchmark_1 (uuid=?)|--SEARCH testbed USING INDEX sqlite_autoindex_testbed_1 (uuid=?)|--SCAN metric|--SEARCH report_benchmark USING INTEGER PRIMARY KEY (rowid=?)|--SEARCH report USING INTEGER PRIMARY KEY (rowid=?)|--SEARCH version USING INTEGER PRIMARY KEY (rowid=?)|--SEARCH branch_version USING COVERING INDEX sqlite_autoindex_branch_version_1 (branch_id=? AND version_id=?)|--BLOOM FILTER ON (join-5) (metric_id=?)|--SEARCH (join-5) USING AUTOMATIC COVERING INDEX (metric_id=?) LEFT-JOIN`--USE TEMP B-TREE FOR ORDER BYО, боже! Здесь много информации. Но три главные вещи, которые бросились мне в глаза:
- SQLite создает материализованное представление на лету, которое сканирует всю таблицу
boundary - После этого SQLite сканирует всю таблицу
metric - SQLite создает два индекса на лету
И каковы размеры таблиц metric и boundary?
Оказывается, это две самые большие таблицы,
так как именно в них хранятся все Метрики и Границы.
Поскольку это был мой первый опыт настройки производительности SQLite, я хотел проконсультироваться с экспертом, прежде чем вносить какие-либо изменения.
Эксперт по SQLite
В SQLite есть экспериментальный режим “эксперта”, который можно активировать с помощью команды .expert.
Он предлагает индексы для запросов, поэтому я решил его испытать.
Вот что он предложил:
CREATE INDEX report_benchmark_idx_fc6f3e5b ON report_benchmark(report_id, benchmark_id);CREATE INDEX report_idx_55aae6d8 ON report(testbed_id, end_time);CREATE INDEX alert_idx_e1882f70 ON alert(boundary_id);
MATERIALIZE (join-5)SCAN boundarySEARCH threshold USING INTEGER PRIMARY KEY (rowid=?)SEARCH model USING INTEGER PRIMARY KEY (rowid=?)SEARCH alert USING INDEX alert_idx_e1882f70 (boundary_id=?) LEFT-JOINSEARCH branch USING INDEX sqlite_autoindex_branch_1 (uuid=?)SEARCH benchmark USING INDEX sqlite_autoindex_benchmark_1 (uuid=?)SEARCH testbed USING INDEX sqlite_autoindex_testbed_1 (uuid=?)SEARCH measure USING INDEX sqlite_autoindex_measure_1 (uuid=?)SEARCH report USING INDEX report_idx_55aae6d8 (testbed_id=? AND end_time<?)SEARCH version USING INTEGER PRIMARY KEY (rowid=?)SEARCH branch_version USING COVERING INDEX sqlite_autoindex_branch_version_1 (branch_id=? AND version_id=?)SEARCH report_benchmark USING INDEX report_benchmark_idx_fc6f3e5b (report_id=? AND benchmark_id=?)SEARCH metric USING INDEX sqlite_autoindex_metric_2 (report_benchmark_id=? AND measure_id=?)BLOOM FILTER ON (join-5) (metric_id=?)SEARCH (join-5) USING AUTOMATIC COVERING INDEX (metric_id=?) LEFT-JOINUSE TEMP B-TREE FOR ORDER BYЭто определенно улучшение!
Теперь не происходит сканирование таблицы metric и оба индекса “на лету” исчезли.
Честно говоря, первые два индекса я бы сам не придумал.
Спасибо, Эксперт по SQLite!
CREATE INDEX index_report_testbed_end_time ON report(testbed_id, end_time);CREATE INDEX index_report_benchmark ON report_benchmark(report_id, benchmark_id);CREATE INDEX index_alert_boundary ON alert(boundary_id);Теперь осталось только избавиться от этого проклятого материализованного представления “на лету”.
Материализованное представление
Когда я добавил возможность отслеживать и визуализировать Пороговые Границы в прошлом году,
мне нужно было принять решение по модели базы данных.
Между метрикой и соответствующей ей границей существует отношение 1 к 0/1.
То есть метрика может быть связана с нулем или одной границей, и граница может быть связана только с одной метрикой.
Я мог бы просто расширить таблицу metric, включив в нее все данные boundary с возможностью установки каждого поля связанного с boundary в NULL.
Или я мог создать отдельную таблицу boundary с UNIQUE внешним ключом к таблице metric.
Для меня последний вариант показался намного чище, и я подумал, что смогу всегда разобраться с любыми последствиями для производительности позже.
Это были актуальные запросы, использованные для создания таблиц metric и boundary:
CREATE TABLE metric ( id INTEGER PRIMARY KEY NOT NULL, uuid TEXT NOT NULL UNIQUE, report_benchmark_id INTEGER NOT NULL, measure_id INTEGER NOT NULL, value DOUBLE NOT NULL, lower_value DOUBLE, upper_value DOUBLE, FOREIGN KEY (report_benchmark_id) REFERENCES report_benchmark (id) ON DELETE CASCADE, FOREIGN KEY (measure_id) REFERENCES measure (id), UNIQUE(report_benchmark_id, measure_id));CREATE TABLE boundary ( id INTEGER PRIMARY KEY NOT NULL, uuid TEXT NOT NULL UNIQUE, threshold_id INTEGER NOT NULL, statistic_id INTEGER NOT NULL, metric_id INTEGER NOT NULL UNIQUE, baseline DOUBLE NOT NULL, lower_limit DOUBLE, upper_limit DOUBLE, FOREIGN KEY (threshold_id) REFERENCES threshold (id), FOREIGN KEY (statistic_id) REFERENCES statistic (id), FOREIGN KEY (metric_id) REFERENCES metric (id) ON DELETE CASCADE);И оказалось, что “позже” наступило.
Я попытался просто добавить индекс для boundary(metric_id), но это не помогло.
Я считаю, что причина заключается в том, что запрос Perf исходит из таблицы metric,
и поскольку эта связь 0/1, или другими словами, nullable, ее необходимо сканировать (O(n)),
а не искать (O(log(n))).
У меня остался один ясный вариант.
Мне нужно было создать материализованное представление, которое “разгладило” бы отношение между metric и boundary,
чтобы SQLite не приходилось создавать его на лету.
Это запрос, который я использовал для создания нового материализованного представления metric_boundary:
CREATE VIEW metric_boundary ASSELECT metric.id AS metric_id, metric.uuid AS metric_uuid, metric.report_benchmark_id, metric.measure_id, metric.value, metric.lower_value, metric.upper_value, boundary.id, boundary.uuid AS boundary_uuid, boundary.threshold_id AS threshold_id, boundary.model_id, boundary.baseline, boundary.lower_limit, boundary.upper_limitFROM metric LEFT OUTER JOIN boundary ON (boundary.metric_id = metric.id);С этим решением я обмениваю пространство на производительность выполнения. Сколько пространства? Удивительно, но только около 4% увеличения, хотя это представление для двух самых больших таблиц в базе данных. И самое главное, это позволяет мне иметь все и сразу в моем исходном коде.
Создание материализованного представления с Diesel оказалось удивительно простым. Мне просто нужно было использовать точно такие же макросы, которые Diesel использует при генерации моей обычной схемы. Сказав это, я стал гораздо больше ценить Diesel на протяжении всего этого опыта. Смотрите Bonus Bug для всех интересных подробностей.
Заключение
С добавлением трех новых индексов и материализованного представления вот что теперь показывает Планировщик Запросов:
QUERY PLAN|--SEARCH branch USING INDEX sqlite_autoindex_branch_1 (uuid=?)|--SEARCH testbed USING INDEX sqlite_autoindex_testbed_1 (uuid=?)|--SEARCH benchmark USING INDEX sqlite_autoindex_benchmark_1 (uuid=?)|--SEARCH measure USING INDEX sqlite_autoindex_measure_1 (uuid=?)|--SEARCH report USING INDEX index_report_testbed_end_time (testbed_id=? AND end_time<?)|--SEARCH version USING INTEGER PRIMARY KEY (rowid=?)|--SEARCH branch_version USING COVERING INDEX sqlite_autoindex_branch_version_1 (branch_id=? AND version_id=?)|--SEARCH report_benchmark USING INDEX index_report_benchmark (report_id=? AND benchmark_id=?)|--SEARCH metric USING INDEX sqlite_autoindex_metric_2 (report_benchmark_id=? AND measure_id=?)|--SEARCH boundary USING INDEX sqlite_autoindex_boundary_2 (metric_id=?) LEFT-JOIN|--SEARCH threshold USING INTEGER PRIMARY KEY (rowid=?) LEFT-JOIN|--SEARCH model USING INTEGER PRIMARY KEY (rowid=?) LEFT-JOIN|--SEARCH alert USING INDEX index_alert_boundary (boundary_id=?) LEFT-JOIN`--USE TEMP B-TREE FOR ORDER BYПосмотрите на все эти прекрасные SEARCH с существующими индексами! 🥲
И после развертывания моих изменений в продакшен:
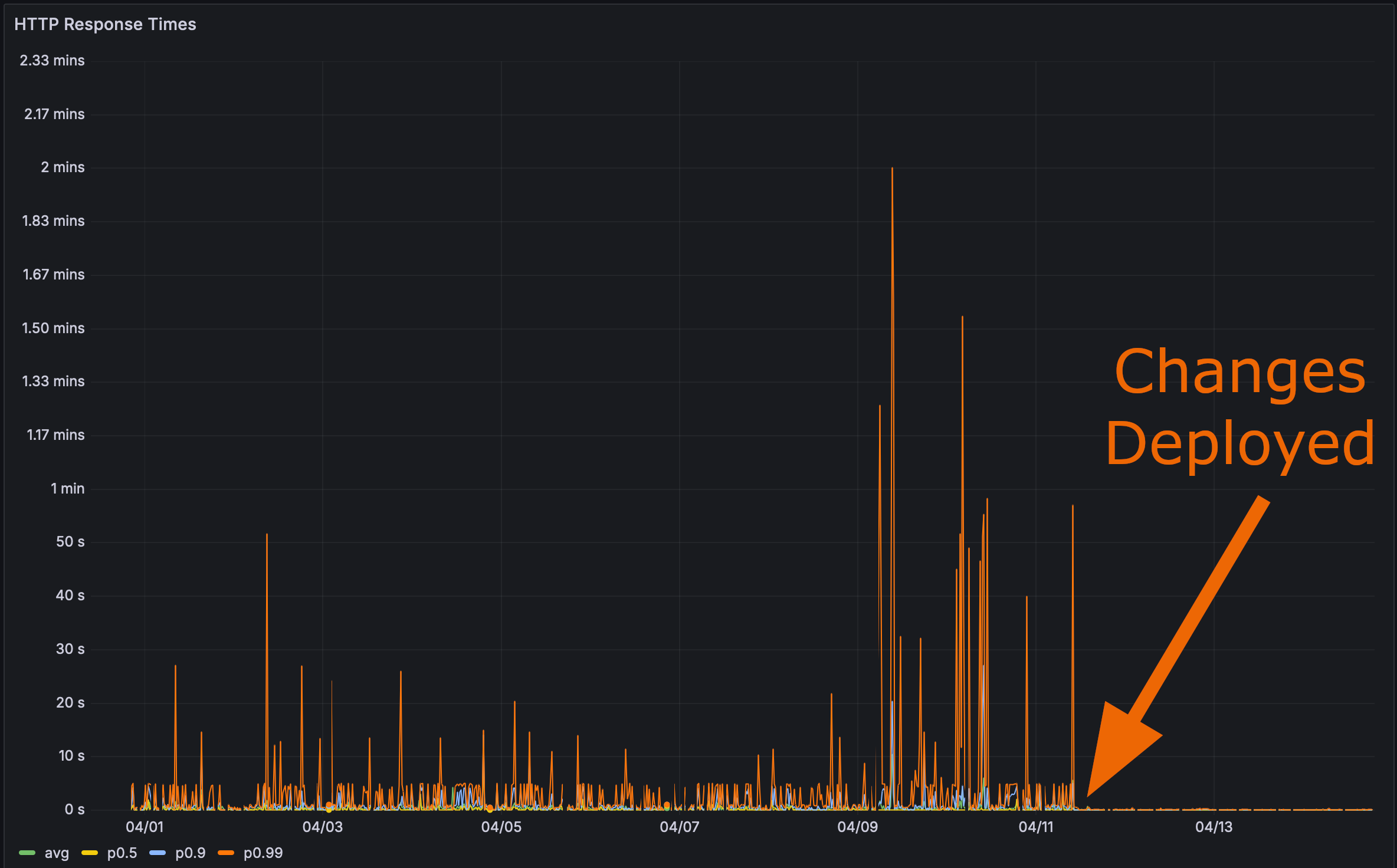
Теперь настало время для финального теста. Как быстро теперь загружается страница с производительностью Rustls?
Здесь я даже дам вам якорную метку. Кликните по ней, а затем обновите страницу.
Производительность имеет значение
Bencher: Непрерывное тестирование производительности

Bencher - это набор инструментов для непрерывного тестирования производительности. Когда-нибудь регрессия производительности влияла на ваших пользователей? Bencher мог бы предотвратить это. Bencher позволяет вам обнаруживать и предотвращать регрессии производительности до того, как они будут слиты.
- Запустить: Запустите свои тесты производительности локально или в CI, используя точно те же самые bare metal раннеры и ваши любимые инструменты для тестирования. CLI
bencherоркестрирует запуск ваших тестов производительности на bare metal и сохраняет их результаты. - Отслеживать: Отслеживайте результаты ваших тестов производительности со временем. Мониторите, запрашивайте и строите графики результатов с помощью веб-консоли Bencher на основе ветки исходного кода, испытательного стенда и меры.
- Поймать: Отлавливайте регрессии производительности локально или в CI, используя точно то же самое bare metal оборудование. Bencher использует инструменты аналитики, работающие по последнему слову техники, чтобы обнаружить регрессии производительности, прежде чем они будут слиты.
По тем же причинам, по которым модульные тесты запускаются, чтобы предотвратить регрессии функций, тесты производительности должны быть запущены с Bencher, чтобы предотвратить регрессии производительности. Ошибки производительности – это тоже ошибки!
Начните отлавливать регрессии производительности — попробуйте Bencher Cloud бесплатно.
Дополнение к использованию собственных продуктов в качестве теста
Я уже использую Bencher для тестирования Bencher, но все существующие адаптеры для инструментов бенчмаркинга предназначены для микро-бенчмаркинга. Большинство инструментов для тестирования HTTP представляют собой скорее инструменты для тестирования нагрузки, и тестирование нагрузки отличается от бенчмаркинга. Кроме того, я не планирую в ближайшее время расширять Bencher функционалом тестирования нагрузки. Это совсем другой случай использования, который потребует совершенно иных архитектурных решений, например, вот база данных временных рядов. Даже если бы у меня было тестирование нагрузки, мне действительно нужно было бы проводить его на свежих данных из продуктивной базы, чтобы это было замечено. Различия в производительности для этих изменений были незначительны с моей тестовой базой данных.
Нажмите, чтобы просмотреть результаты бенчмарков тестовой базы данных
До:
Run Time: real 0.081 user 0.019532 sys 0.005618Run Time: real 0.193 user 0.022192 sys 0.003368Run Time: real 0.070 user 0.021390 sys 0.003369Run Time: real 0.062 user 0.022676 sys 0.002290Run Time: real 0.057 user 0.012053 sys 0.006638Run Time: real 0.052 user 0.018797 sys 0.002016Run Time: real 0.059 user 0.022806 sys 0.002437Run Time: real 0.066 user 0.021869 sys 0.004525Run Time: real 0.060 user 0.021037 sys 0.002864Run Time: real 0.059 user 0.018397 sys 0.003668После добавления индексов и материализованных представлений:
Run Time: real 0.063 user 0.008671 sys 0.004898Run Time: real 0.053 user 0.010671 sys 0.003334Run Time: real 0.053 user 0.010337 sys 0.002884Run Time: real 0.052 user 0.008087 sys 0.002165Run Time: real 0.045 user 0.007265 sys 0.002123Run Time: real 0.038 user 0.008793 sys 0.002240Run Time: real 0.040 user 0.011022 sys 0.002420Run Time: real 0.049 user 0.010004 sys 0.002831Run Time: real 0.059 user 0.010472 sys 0.003661Run Time: real 0.046 user 0.009968 sys 0.002628Все это заставляет меня думать, что мне следует создать микро-бенчмарк, который будет работать с API для измерения производительности и использовать результаты в Bencher. Это потребует значительной тестовой базы данных, чтобы убедиться, что такие регрессии производительности будут выявлены в CI. Я создал задачу для отслеживания этой работы, если вы хотите следить за её прогрессом.
Это заставило меня задуматься: А что если бы можно было делать тестирование снимками (snapshot testing) планов SQL-запросов вашей базы данных? То есть, вы могли бы сравнивать текущие и потенциальные планы SQL-запросов вашей базы данных. Тестирование плана SQL-запросов могло бы быть своего рода бенчмаркингом на основе подсчета инструкций для баз данных. План запроса помогает указать на возможную проблему с производительностью во время выполнения, не требуя фактического бенчмаркинга SQL-запроса. Я также создал задачу для отслеживания и для этого. Пожалуйста, не стесняйтесь добавлять комментарий с вашими мыслями или существующими решениями, которые вам известны!
Дополнительный баг
Изначально у меня была ошибка в коде материализованного представления. Вот как выглядел SQL-запрос:
SELECT branch.id, branch.uuid, branch.project_id, branch.name, branch.slug, branch.start_point_id, branch.created, branch.modified, testbed.id, testbed.uuid, testbed.project_id, testbed.name, testbed.slug, testbed.created, testbed.modified, benchmark.id, benchmark.uuid, benchmark.project_id, benchmark.name, benchmark.slug, benchmark.created, benchmark.modified, measure.id, measure.uuid, measure.project_id, measure.name, measure.slug, measure.units, measure.created, measure.modified, report.uuid, report_benchmark.iteration, report.start_time, report.end_time, version.number, version.hash, threshold.id, threshold.uuid, threshold.project_id, threshold.measure_id, threshold.branch_id, threshold.testbed_id, threshold.model_id, threshold.created, threshold.modified, model.id, model.uuid, model.threshold_id, model.test, model.min_sample_size, model.max_sample_size, model.window, model.lower_boundary, model.upper_boundary, model.created, model.replaced, alert.id, alert.uuid, alert.boundary_id, alert.boundary_limit, alert.status, alert.modified, metric_boundary.metric_id, metric_boundary.metric_uuid, metric_boundary.report_benchmark_id, metric_boundary.measure_id, metric_boundary.value, metric_boundary.lower_value, metric_boundary.upper_value, metric_boundary.boundary_id, metric_boundary.boundary_uuid, metric_boundary.threshold_id, metric_boundary.model_id, metric_boundary.baseline, metric_boundary.lower_limit, metric_boundary.upper_limit FROM (((((metric_boundary INNER JOIN ((report_benchmark INNER JOIN ((report INNER JOIN (version INNER JOIN (branch_version INNER JOIN branch ON (branch_version.branch_id = branch.id)) ON (branch_version.version_id = version.id)) ON (report.version_id = version.id)) INNER JOIN testbed ON (report.testbed_id = testbed.id)) ON (report_benchmark.report_id = report.id)) INNER JOIN benchmark ON (report_benchmark.benchmark_id = benchmark.id)) ON (metric_boundary.report_benchmark_id = report_benchmark.id)) INNER JOIN measure ON (metric_boundary.measure_id = measure.id)) LEFT OUTER JOIN threshold ON (metric_boundary.threshold_id = threshold.id)) LEFT OUTER JOIN model ON (metric_boundary.model_id = model.id)) LEFT OUTER JOIN alert ON (alert.boundary_id = metric_boundary.metric_id)) WHERE ((((((branch.uuid = 'a7d8366a-4f9b-452e-987e-2ae56e4bf4a3') AND (testbed.uuid = '5b4a6f3e-a27d-4cc3-a2ce-851dc6421e6e')) AND (benchmark.uuid = '88375e7c-f1e0-4cbb-bde1-bdb7773022ae')) AND (measure.uuid = 'b2275bbc-2044-4f8e-aecd-3c739bd861b9')) AND (report.start_time >= 0)) AND (report.end_time <= 1712838648197)) ORDER BY version.number, report.start_time, report_benchmark.iteration;Вы видите проблему? Нет. Я тоже не увидел!
Проблема здесь:
LEFT OUTER JOIN alert ON (alert.boundary_id = metric_boundary.metric_id)На самом деле должно быть:
LEFT OUTER JOIN alert ON (alert.boundary_id = metric_boundary.boundary_id)Я пытался быть слишком изобретательным, и в схеме материализованного представления Diesel я разрешил это соединение:
diesel::joinable!(alert -> metric_boundary (boundary_id));Я предполагал, что эта макроинструкция каким-то образом достаточно умна,
чтобы связать alert.boundary_id с metric_boundary.boundary_id.
Но увы, это не так.
Похоже, что было просто выбрано первое поле metric_boundary (metric_id) для связи с alert.
Как только я обнаружил ошибку, исправить её было легко. Мне просто нужно было использовать явное соединение в запросе Perf:
.left_join(schema::alert::table.on(view::metric_boundary::boundary_id.eq(schema::alert::boundary_id.nullable())))🐰 Вот и всё, ребята!