Por que o Ajuste de Desempenho do SQLite tornou o Bencher 1200x Mais Rápido

Everett Pompeii
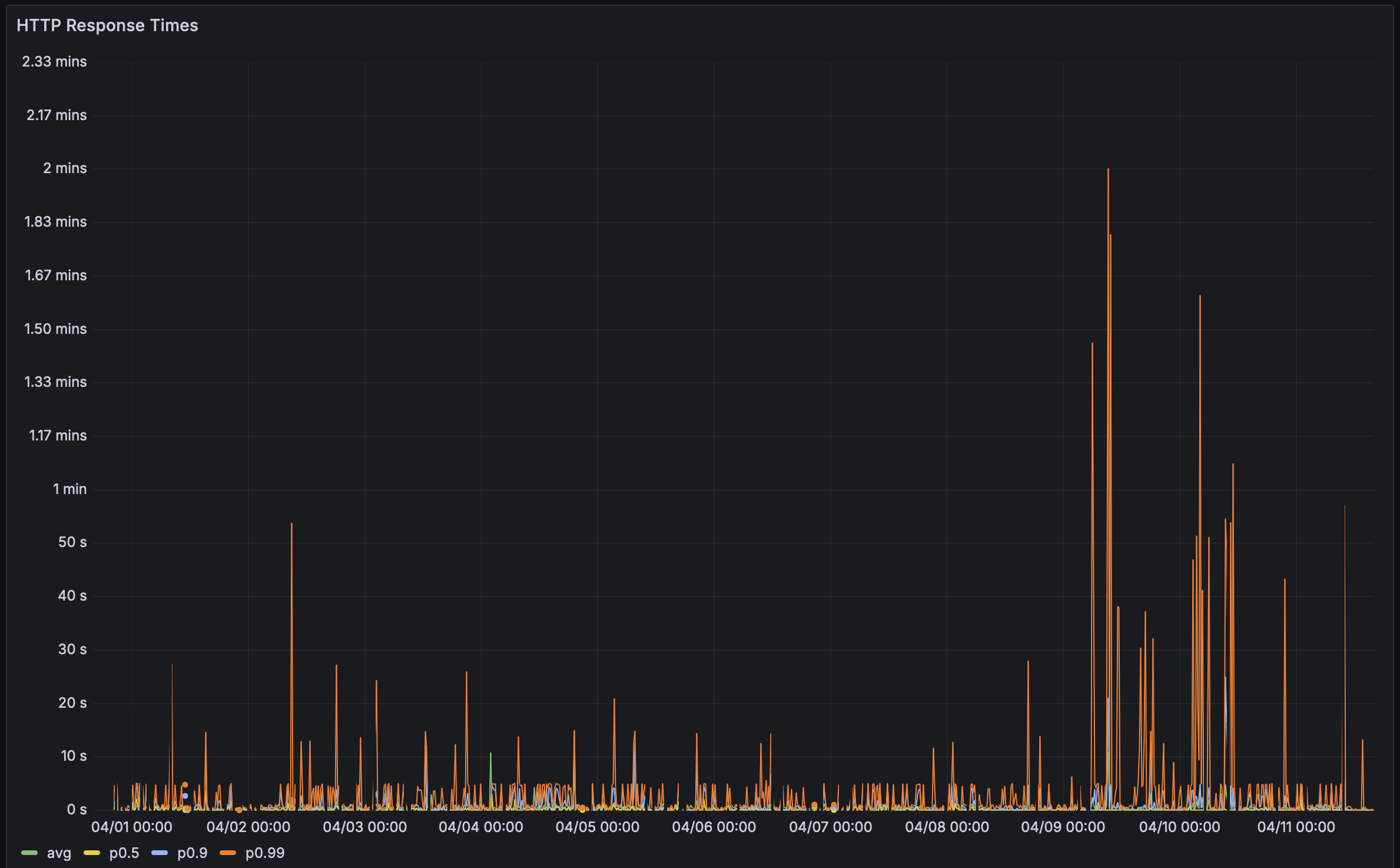
Na semana passada, recebi um feedback de um usuário dizendo que a página de desempenho do Bencher deles estava demorando para carregar. Então decidi verificar, e nossa, eles estavam sendo gentis. Demorou muuuito para carregar! Constrangedoramente demorado. Especialmente para a principal ferramenta de Benchmarks Contínuos.
No passado, eu usava a página de desempenho do Rustls como meu teste decisivo. Eles têm 112 benchmarks e uma das configurações de Benchmarks Contínuos mais impressionantes que existem. Costumava levar cerca de 5 segundos para carregar. Dessa vez levou… ⏳👀 … 38,8 segundos! Com esse tipo de latência, eu tinha que investigar. Bugs de desempenho são bugs, afinal!
Contexto
Desde o início, eu sabia que o Bencher Perf API seria um dos endpoints mais exigentes em termos de desempenho. Acredito que o principal motivo pelo qual muitas pessoas tiveram que reinventar a roda de acompanhamento de benchmarks é que as ferramentas disponíveis no mercado não lidam com a alta dimensionalidade necessária. Por “alta dimensionalidade”, eu quero dizer ser capaz de acompanhar o desempenho ao longo do tempo e em várias dimensões: Branches, Ambientes de Teste, Benchmarks e Medidas. Essa capacidade de segmentar e cruzar cinco dimensões diferentes leva a um modelo muito complexo.
Devido a essa complexidade inerente e à natureza dos dados, eu considerei usar um banco de dados de séries temporais para o Bencher. No final, porém, optei por usar o SQLite. Eu concluí que era melhor fazer coisas que não escalonam do que gastar tempo extra aprendendo uma arquitetura de banco de dados totalmente nova que talvez não ajudasse de fato.
Com o tempo, as demandas sobre a Bencher Perf API também aumentaram. Originalmente, você tinha que selecionar todas as dimensões que queria plotar manualmente. Isso criava muita fricção para os usuários obterem um gráfico útil. Para resolver isso, eu adicionei uma lista dos Relatórios mais recentes às Páginas de Desempenho, e por padrão, o Relatório mais recente era selecionado e plotado. Isso significa que se houvesse 112 benchmarks no Relatório mais recente, então todos os 112 seriam plotados. O modelo também ficou ainda mais complicado com a capacidade de acompanhar e visualizar Limites de Limiar.
Com isso em mente, fiz algumas melhorias relacionadas ao desempenho. Uma vez que o Gráfico de Desempenho precisa do Relatório mais recente para começar a plotar, eu refatorei a API de Relatórios para obter os dados de resultado de um Relatório em uma única chamada ao banco de dados, em vez de iterar. O período de tempo para a consulta padrão do Relatório foi definido para quatro semanas, em vez de ser ilimitado. Eu também limitei drasticamente o escopo de todos os handles do banco de dados, reduzindo a contenção de bloqueios. Para ajudar a comunicar aos usuários, eu adicionei um indicador de status giratório tanto para o Gráfico de Desempenho quanto para as abas de dimensão.
Eu também tive uma tentativa frustrada no último outono de usar uma consulta composta para obter todos os resultados do Perf em uma única query, em vez de usar um loop aninhado quádruplo. Isso me levou a atingir o limite de recursão do sistema de tipos do Rust, transbordando repetidamente a pilha, sofrendo com tempos de compilação insanos (muito mais longos que 38 segundos), e finalmente chegando a um beco sem saída no limite máximo de número de termos em uma instrução select composta do SQLite.
Com tudo isso na bagagem, eu sabia que realmente precisava me aprofundar aqui e vestir as calças de engenheiro de desempenho. Eu nunca havia perfilado um banco de dados SQLite antes, e, honestamente, nunca havia perfilado nenhum banco de dados antes. Agora espere um minuto, você pode estar pensando. Meu perfil no LinkedIn diz que fui “Administrador de Banco de Dados” por quase dois anos. E eu nunca profilei um banco de dados‽ Sim. Essa é uma história para outra hora, suponho.
De ORM para Consulta SQL
O primeiro desafio que encontrei foi extrair a consulta SQL do meu código Rust. Eu uso o Diesel como o mapeador objeto-relacional (ORM) para o Bencher.
🐰 Curiosidade: O Diesel usa o Bencher para o seu Benchmarking Contínuo Relativo. Confira a página de desempenho do Diesel!
O Diesel cria consultas parametrizadas.
Ele envia a consulta SQL e seus parâmetros de ligação separadamente para o banco de dados.
Isto é, a substituição é feita pelo banco de dados.
Portanto, o Diesel não pode fornecer uma consulta completa ao usuário.
O melhor método que encontrei foi usar a função diesel::debug_query para saída da consulta parametrizada:
Query { sql: "SELECT `branch`.`id`, `branch`.`uuid`, `branch`.`project_id`, `branch`.`name`, `branch`.`slug`, `branch`.`start_point_id`, `branch`.`created`, `branch`.`modified`, `testbed`.`id`, `testbed`.`uuid`, `testbed`.`project_id`, `testbed`.`name`, `testbed`.`slug`, `testbed`.`created`, `testbed`.`modified`, `benchmark`.`id`, `benchmark`.`uuid`, `benchmark`.`project_id`, `benchmark`.`name`, `benchmark`.`slug`, `benchmark`.`created`, `benchmark`.`modified`, `measure`.`id`, `measure`.`uuid`, `measure`.`project_id`, `measure`.`name`, `measure`.`slug`, `measure`.`units`, `measure`.`created`, `measure`.`modified`, `report`.`uuid`, `report_benchmark`.`iteration`, `report`.`start_time`, `report`.`end_time`, `version`.`number`, `version`.`hash`, `threshold`.`id`, `threshold`.`uuid`, `threshold`.`project_id`, `threshold`.`measure_id`, `threshold`.`branch_id`, `threshold`.`testbed_id`, `threshold`.`model_id`, `threshold`.`created`, `threshold`.`modified`, `model`.`id`, `model`.`uuid`, `model`.`threshold_id`, `model`.`test`, `model`.`min_sample_size`, `model`.`max_sample_size`, `model`.`window`, `model`.`lower_boundary`, `model`.`upper_boundary`, `model`.`created`, `model`.`replaced`, `boundary`.`id`, `boundary`.`uuid`, `boundary`.`threshold_id`, `boundary`.`model_id`, `boundary`.`metric_id`, `boundary`.`baseline`, `boundary`.`lower_limit`, `boundary`.`upper_limit`, `alert`.`id`, `alert`.`uuid`, `alert`.`boundary_id`, `alert`.`boundary_limit`, `alert`.`status`, `alert`.`modified`, `metric`.`id`, `metric`.`uuid`, `metric`.`report_benchmark_id`, `metric`.`measure_id`, `metric`.`value`, `metric`.`lower_value`, `metric`.`upper_value` FROM (((`metric` INNER JOIN ((`report_benchmark` INNER JOIN ((`report` INNER JOIN (`version` INNER JOIN (`branch_version` INNER JOIN `branch` ON (`branch_version`.`branch_id` = `branch`.`id`)) ON (`branch_version`.`version_id` = `version`.`id`)) ON (`report`.`version_id` = `version`.`id`)) INNER JOIN `testbed` ON (`report`.`testbed_id` = `testbed`.`id`)) ON (`report_benchmark`.`report_id` = `report`.`id`)) INNER JOIN `benchmark` ON (`report_benchmark`.`benchmark_id` = `benchmark`.`id`)) ON (`metric`.`report_benchmark_id` = `report_benchmark`.`id`)) INNER JOIN `measure` ON (`metric`.`measure_id` = `measure`.`id`)) LEFT OUTER JOIN (((`boundary` INNER JOIN `threshold` ON (`boundary`.`threshold_id` = `threshold`.`id`)) INNER JOIN `model` ON (`boundary`.`model_id` = `model`.`id`)) LEFT OUTER JOIN `alert` ON (`alert`.`boundary_id` = `boundary`.`id`)) ON (`boundary`.`metric_id` = `metric`.`id`)) WHERE ((((((`branch`.`uuid` = ?) AND (`testbed`.`uuid` = ?)) AND (`benchmark`.`uuid` = ?)) AND (`measure`.`uuid` = ?)) AND (`report`.`start_time` >= ?)) AND (`report`.`end_time` <= ?)) ORDER BY `version`.`number`, `report`.`start_time`, `report_benchmark`.`iteration`", binds: [BranchUuid(a7d8366a-4f9b-452e-987e-2ae56e4bf4a3), TestbedUuid(5b4a6f3e-a27d-4cc3-a2ce-851dc6421e6e), BenchmarkUuid(88375e7c-f1e0-4cbb-bde1-bdb7773022ae), MeasureUuid(b2275bbc-2044-4f8e-aecd-3c739bd861b9), DateTime(2024-03-12T12:23:38Z), DateTime(2024-04-11T12:23:38Z)] }E então limpando manualmente e parametrizando a consulta em um SQL válido:
SELECT branch.id, branch.uuid, branch.project_id, branch.name, branch.slug, branch.start_point_id, branch.created, branch.modified, testbed.id, testbed.uuid, testbed.project_id, testbed.name, testbed.slug, testbed.created, testbed.modified, benchmark.id, benchmark.uuid, benchmark.project_id, benchmark.name, benchmark.slug, benchmark.created, benchmark.modified, measure.id, measure.uuid, measure.project_id, measure.name, measure.slug, measure.units, measure.created, measure.modified, report.uuid, report_benchmark.iteration, report.start_time, report.end_time, version.number, version.hash, threshold.id, threshold.uuid, threshold.project_id, threshold.measure_id, threshold.branch_id, threshold.testbed_id, threshold.model_id, threshold.created, threshold.modified, model.id, model.uuid, model.threshold_id, model.test, model.min_sample_size, model.max_sample_size, model.window, model.lower_boundary, model.upper_boundary, model.created, model.replaced, boundary.id, boundary.uuid, boundary.threshold_id, boundary.model_id, boundary.metric_id, boundary.baseline, boundary.lower_limit, boundary.upper_limit, alert.id, alert.uuid, alert.boundary_id, alert.boundary_limit, alert.status, alert.modified, metric.id, metric.uuid, metric.report_benchmark_id, metric.measure_id, metric.value, metric.lower_value, metric.upper_value FROM (((metric INNER JOIN ((report_benchmark INNER JOIN ((report INNER JOIN (version INNER JOIN (branch_version INNER JOIN branch ON (branch_version.branch_id = branch.id)) ON (branch_version.version_id = version.id)) ON (report.version_id = version.id)) INNER JOIN testbed ON (report.testbed_id = testbed.id)) ON (report_benchmark.report_id = report.id)) INNER JOIN benchmark ON (report_benchmark.benchmark_id = benchmark.id)) ON (metric.report_benchmark_id = report_benchmark.id)) INNER JOIN measure ON (metric.measure_id = measure.id)) LEFT OUTER JOIN (((boundary INNER JOIN threshold ON (boundary.threshold_id = threshold.id)) INNER JOIN model ON (boundary.model_id = model.id)) LEFT OUTER JOIN alert ON (alert.boundary_id = boundary.id)) ON (boundary.metric_id = metric.id)) WHERE ((((((branch.uuid = 'a7d8366a-4f9b-452e-987e-2ae56e4bf4a3') AND (testbed.uuid = '5b4a6f3e-a27d-4cc3-a2ce-851dc6421e6e')) AND (benchmark.uuid = '88375e7c-f1e0-4cbb-bde1-bdb7773022ae')) AND (measure.uuid = 'b2275bbc-2044-4f8e-aecd-3c739bd861b9')) AND (report.start_time >= 0)) AND (report.end_time <= 1712838648197)) ORDER BY version.number, report.start_time, report_benchmark.iteration;Se você conhece uma maneira melhor, por favor me avise! Esta é a maneira que o mantenedor do projeto sugeriu no entanto, então eu simplesmente prossegui com ela. Agora que eu tinha uma consulta SQL, eu finalmente estava pronto para… ler uma enorme quantidade de documentação.
Planejador de Consultas do SQLite
O site do SQLite possui uma ótima documentação para o seu Planejador de Consultas. Ele explica exatamente como o SQLite executa a sua consulta SQL, e ensina quais índices são úteis e quais operações ficar de olho, como varreduras completas de tabela.
Para ver como o Planejador de Consultas executaria minha consulta Perf,
eu precisei adicionar uma nova ferramenta ao meu arsenal: EXPLAIN QUERY PLAN
Você pode tanto prefixar sua consulta SQL com EXPLAIN QUERY PLAN
ou executar o comando .eqp on antes da sua consulta.
De qualquer maneira, eu obtive um resultado que se parece com isso:
QUERY PLAN|--MATERIALIZE (join-5)| |--SCAN boundary| |--SEARCH threshold USING INTEGER PRIMARY KEY (rowid=?)| |--SEARCH model USING INTEGER PRIMARY KEY (rowid=?)| |--BLOOM FILTER ON alert (boundary_id=?)| `--SEARCH alert USING AUTOMATIC COVERING INDEX (boundary_id=?) LEFT-JOIN|--SEARCH branch USING INDEX sqlite_autoindex_branch_1 (uuid=?)|--SEARCH measure USING INDEX sqlite_autoindex_measure_1 (uuid=?)|--SEARCH benchmark USING INDEX sqlite_autoindex_benchmark_1 (uuid=?)|--SEARCH testbed USING INDEX sqlite_autoindex_testbed_1 (uuid=?)|--SCAN metric|--SEARCH report_benchmark USING INTEGER PRIMARY KEY (rowid=?)|--SEARCH report USING INTEGER PRIMARY KEY (rowid=?)|--SEARCH version USING INTEGER PRIMARY KEY (rowid=?)|--SEARCH branch_version USING COVERING INDEX sqlite_autoindex_branch_version_1 (branch_id=? AND version_id=?)|--BLOOM FILTER ON (join-5) (metric_id=?)|--SEARCH (join-5) USING AUTOMATIC COVERING INDEX (metric_id=?) LEFT-JOIN`--USE TEMP B-TREE FOR ORDER BYNossa! Há muito aqui. Mas as três grandes coisas que me saltaram aos olhos foram:
- O SQLite está criando uma view materializada instantaneamente que varre a inteira tabela
boundary - O SQLite está então varrendo a inteira tabela
metric - O SQLite está criando dois índices instantaneamente
E quão grandes são as tabelas metric e boundary?
Bem, elas acontecem de ser as duas maiores tabelas,
já que é onde todas as Métricas e Limites são armazenadas.
Já que esta foi a minha primeira experiência com ajuste de desempenho no SQLite, eu queria consultar um especialista antes de fazer quaisquer mudanças.
SQLite Expert
SQLite possui um modo “expert” experimental que pode ser ativado com o comando .expert.
Ele sugere índices para consultas; então, decidi experimentar.
Eis o que ele sugeriu:
CREATE INDEX report_benchmark_idx_fc6f3e5b ON report_benchmark(report_id, benchmark_id);CREATE INDEX report_idx_55aae6d8 ON report(testbed_id, end_time);CREATE INDEX alert_idx_e1882f70 ON alert(boundary_id);
MATERIALIZE (join-5)SCAN boundarySEARCH threshold USING INTEGER PRIMARY KEY (rowid=?)SEARCH model USING INTEGER PRIMARY KEY (rowid=?)SEARCH alert USING INDEX alert_idx_e1882f70 (boundary_id=?) LEFT-JOINSEARCH branch USING INDEX sqlite_autoindex_branch_1 (uuid=?)SEARCH benchmark USING INDEX sqlite_autoindex_benchmark_1 (uuid=?)SEARCH testbed USING INDEX sqlite_autoindex_testbed_1 (uuid=?)SEARCH measure USING INDEX sqlite_autoindex_measure_1 (uuid=?)SEARCH report USING INDEX report_idx_55aae6d8 (testbed_id=? AND end_time<?)SEARCH version USING INTEGER PRIMARY KEY (rowid=?)SEARCH branch_version USING COVERING INDEX sqlite_autoindex_branch_version_1 (branch_id=? AND version_id=?)SEARCH report_benchmark USING INDEX report_benchmark_idx_fc6f3e5b (report_id=? AND benchmark_id=?)SEARCH metric USING INDEX sqlite_autoindex_metric_2 (report_benchmark_id=? AND measure_id=?)BLOOM FILTER ON (join-5) (metric_id=?)SEARCH (join-5) USING AUTOMATIC COVERING INDEX (metric_id=?) LEFT-JOINUSE TEMP B-TREE FOR ORDER BYDefinitivamente, isso é uma melhoria!
Ele eliminou a varredura na tabela metric e ambos os índices criados em tempo de execução.
Sinceramente, eu não teria chegado aos dois primeiros índices por conta própria.
Obrigado, SQLite Expert!
CREATE INDEX index_report_testbed_end_time ON report(testbed_id, end_time);CREATE INDEX index_report_benchmark ON report_benchmark(report_id, benchmark_id);CREATE INDEX index_alert_boundary ON alert(boundary_id);Agora, a única coisa que resta eliminar é aquela maldita visualização materializada criada em tempo de execução.
Visão Materializada
Quando adicionei a capacidade de rastrear e visualizar Limites de Limiares no ano passado,
eu tinha uma decisão a tomar no modelo de banco de dados.
Existe um relacionamento de 1-para-0/1 entre uma Métrica e seu Limite correspondente.
Isso significa que uma Métrica pode se relacionar a zero ou um Limite, e um Limite só pode se relacionar a uma Métrica.
Então, eu poderia simplesmente expandir a tabela metric para incluir todos os dados de boundary com todos os campos relacionados a boundary sendo nulos.
Ou eu poderia criar uma tabela boundary separada com uma chave estrangeira UNIQUE para a tabela metric.
Para mim, a última opção pareceu muito mais limpa, e eu imaginei que sempre poderia lidar com quaisquer implicações de desempenho mais tarde.
Estas foram as consultas efetivas usadas para criar as tabelas metric e boundary:
CREATE TABLE metric ( id INTEGER PRIMARY KEY NOT NULL, uuid TEXT NOT NULL UNIQUE, report_benchmark_id INTEGER NOT NULL, measure_id INTEGER NOT NULL, value DOUBLE NOT NULL, lower_value DOUBLE, upper_value DOUBLE, FOREIGN KEY (report_benchmark_id) REFERENCES report_benchmark (id) ON DELETE CASCADE, FOREIGN KEY (measure_id) REFERENCES measure (id), UNIQUE(report_benchmark_id, measure_id));CREATE TABLE boundary ( id INTEGER PRIMARY KEY NOT NULL, uuid TEXT NOT NULL UNIQUE, threshold_id INTEGER NOT NULL, statistic_id INTEGER NOT NULL, metric_id INTEGER NOT NULL UNIQUE, baseline DOUBLE NOT NULL, lower_limit DOUBLE, upper_limit DOUBLE, FOREIGN KEY (threshold_id) REFERENCES threshold (id), FOREIGN KEY (statistic_id) REFERENCES statistic (id), FOREIGN KEY (metric_id) REFERENCES metric (id) ON DELETE CASCADE);E acontece que “mais tarde” chegou.
Eu tentei simplesmente adicionar um índice para boundary(metric_id), mas isso não ajudou.
Eu acredito que o motivo tem a ver com o fato de que a consulta de Perf está se originando da tabela metric
e porque essa relação é 0/1, ou de outra forma, nula, ela tem que ser escaneada (O(n))
e não pode ser buscada (O(log(n))).
Isso me deixou com uma opção clara.
Eu precisava criar uma visão materializada que achatasse a relação metric e boundary
para evitar que o SQLite tenha que criar uma visão materializada na hora.
Esta é a consulta que usei para criar a nova visão materializada metric_boundary:
CREATE VIEW metric_boundary ASSELECT metric.id AS metric_id, metric.uuid AS metric_uuid, metric.report_benchmark_id, metric.measure_id, metric.value, metric.lower_value, metric.upper_value, boundary.id, boundary.uuid AS boundary_uuid, boundary.threshold_id AS threshold_id, boundary.model_id, boundary.baseline, boundary.lower_limit, boundary.upper_limitFROM metric LEFT OUTER JOIN boundary ON (boundary.metric_id = metric.id);Com essa solução, estou trocando espaço por desempenho de execução. Quanto espaço? Surpreendentemente, apenas cerca de um aumento de 4%, mesmo que esta visão seja para as duas maiores tabelas no banco de dados. Melhor de tudo, isso me permite ter meu bolo e comê-lo também no meu código-fonte.
Criar uma visão materializada com Diesel foi surpreendentemente fácil. Eu apenas tive que usar as mesmas macros que o Diesel usa quando gerando meu esquema normal. Com isso dito, aprendi a apreciar muito mais o Diesel ao longo dessa experiência. Veja Bug Bônus para todos os detalhes suculentos.
Conclusão
Com os três novos índices e uma view materializada adicionados, é isso que o Planejador de Consultas agora mostra:
QUERY PLAN|--SEARCH branch USING INDEX sqlite_autoindex_branch_1 (uuid=?)|--SEARCH testbed USING INDEX sqlite_autoindex_testbed_1 (uuid=?)|--SEARCH benchmark USING INDEX sqlite_autoindex_benchmark_1 (uuid=?)|--SEARCH measure USING INDEX sqlite_autoindex_measure_1 (uuid=?)|--SEARCH report USING INDEX index_report_testbed_end_time (testbed_id=? AND end_time<?)|--SEARCH version USING INTEGER PRIMARY KEY (rowid=?)|--SEARCH branch_version USING COVERING INDEX sqlite_autoindex_branch_version_1 (branch_id=? AND version_id=?)|--SEARCH report_benchmark USING INDEX index_report_benchmark (report_id=? AND benchmark_id=?)|--SEARCH metric USING INDEX sqlite_autoindex_metric_2 (report_benchmark_id=? AND measure_id=?)|--SEARCH boundary USING INDEX sqlite_autoindex_boundary_2 (metric_id=?) LEFT-JOIN|--SEARCH threshold USING INTEGER PRIMARY KEY (rowid=?) LEFT-JOIN|--SEARCH model USING INTEGER PRIMARY KEY (rowid=?) LEFT-JOIN|--SEARCH alert USING INDEX index_alert_boundary (boundary_id=?) LEFT-JOIN`--USE TEMP B-TREE FOR ORDER BYOlhe todas essas belas SEARCHes, todas com índices existentes! 🥲
E após implantar minhas alterações em produção:
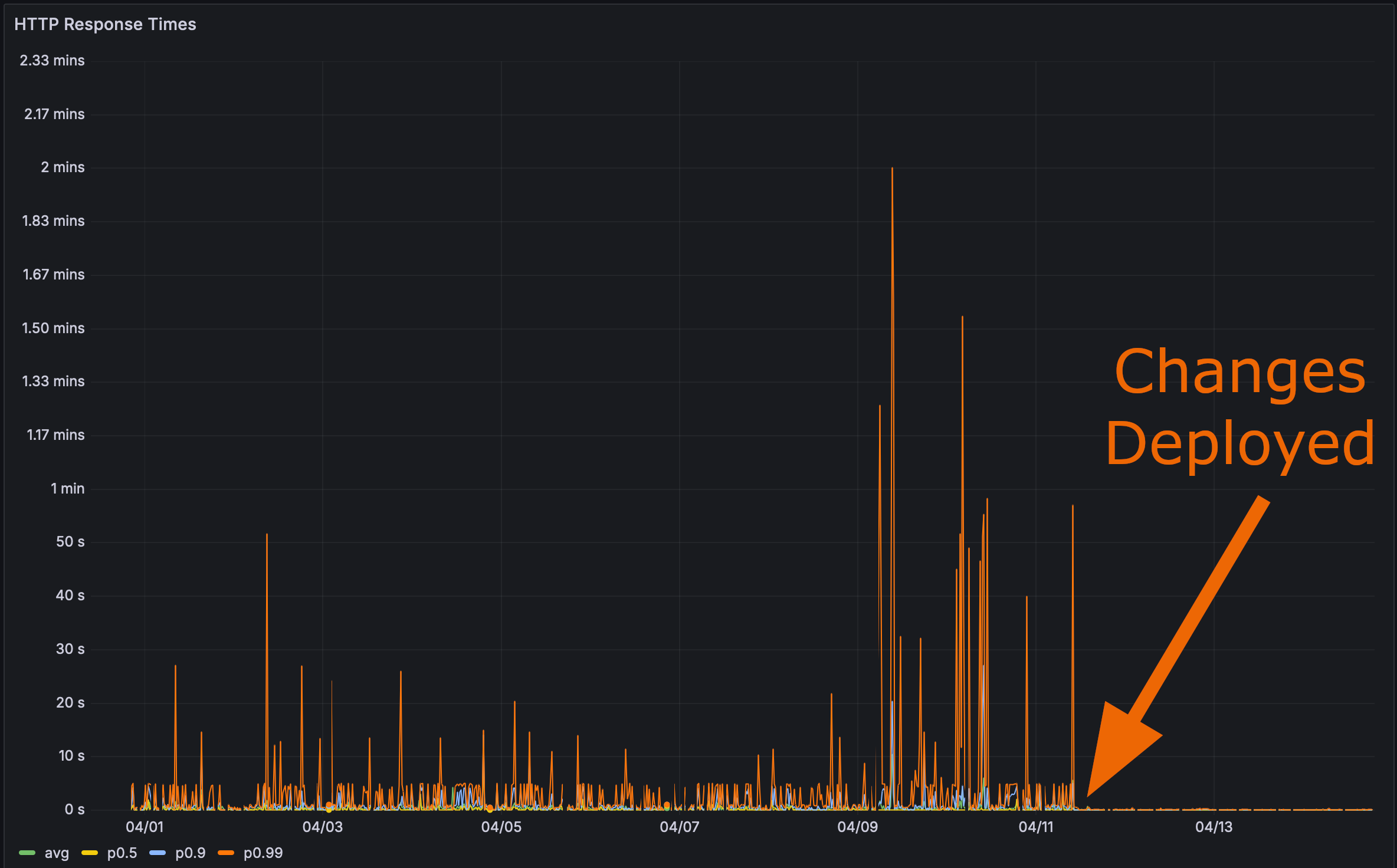
Agora era hora do teste final. Quão rápido a página de Perf do Rustls carrega?
Aqui, eu até te dou uma âncora. Clique nela e depois atualize a página.
O Desempenho Importa
Bencher: Benchmarking Contínuo

Bencher é um conjunto de ferramentas de benchmarking contínuo. Já teve algum impacto de regressão de desempenho nos seus usuários? Bencher poderia ter prevenido isso. Bencher permite que você detecte e previna regressões de desempenho antes que sejam mescladas.
- Execute: Execute seus benchmarks localmente ou no CI usando os exatos mesmos runners bare metal e suas ferramentas de benchmarking favoritas. O CLI
bencherorquestra a execução dos seus benchmarks em bare metal e armazena seus resultados. - Rastreie: Acompanhe os resultados de seus benchmarks ao longo do tempo. Monitore, consulte e faça gráficos dos resultados usando o console web do Bencher baseado na branch de origem, testbed e medida.
- Capture: Capture regressões de desempenho localmente ou no CI usando o exato mesmo hardware bare metal. Bencher usa análises personalizáveis e de última geração para detectar regressões de desempenho antes que sejam mescladas.
Pelos mesmos motivos que os testes de unidade são executados para prevenir regressões de funcionalidades, benchmarks deveriam ser executados com o Bencher para prevenir regressões de desempenho. Bugs de desempenho são bugs!
Comece a capturar regressões de desempenho — experimente o Bencher Cloud gratuitamente.
Adendo sobre Dogfooding
Já estou utilizando o Bencher com o Bencher, mas todos os adaptadores de harness de benchmark existentes são para harnesses de micro-benchmarking. A maioria dos harnesses HTTP são realmente harnesses para testes de carga, e testes de carga são diferentes de benchmarking. Além disso, não estou procurando expandir o Bencher para testes de carga tão cedo. Esse é um caso de uso muito diferente que exigiria considerações de design muito distintas, como aquele banco de dados de séries temporais, por exemplo. Mesmo se eu tivesse implementado testes de carga, realmente precisaria estar executando contra uma nova extração de dados de produção para que isso fosse identificado. As diferenças de desempenho para essas mudanças foram insignificantes com meu banco de dados de teste.
Clique para visualizar os resultados de benchmark do banco de dados de teste
Antes:
Run Time: real 0.081 user 0.019532 sys 0.005618Run Time: real 0.193 user 0.022192 sys 0.003368Run Time: real 0.070 user 0.021390 sys 0.003369Run Time: real 0.062 user 0.022676 sys 0.002290Run Time: real 0.057 user 0.012053 sys 0.006638Run Time: real 0.052 user 0.018797 sys 0.002016Run Time: real 0.059 user 0.022806 sys 0.002437Run Time: real 0.066 user 0.021869 sys 0.004525Run Time: real 0.060 user 0.021037 sys 0.002864Run Time: real 0.059 user 0.018397 sys 0.003668Após índices e visão materializada:
Run Time: real 0.063 user 0.008671 sys 0.004898Run Time: real 0.053 user 0.010671 sys 0.003334Run Time: real 0.053 user 0.010337 sys 0.002884Run Time: real 0.052 user 0.008087 sys 0.002165Run Time: real 0.045 user 0.007265 sys 0.002123Run Time: real 0.038 user 0.008793 sys 0.002240Run Time: real 0.040 user 0.011022 sys 0.002420Run Time: real 0.049 user 0.010004 sys 0.002831Run Time: real 0.059 user 0.010472 sys 0.003661Run Time: real 0.046 user 0.009968 sys 0.002628Tudo isso me leva a crer que devo criar um micro-benchmark que rode contra o endpoint da API Perf e utilizar os resultados com o Bencher. Isso vai exigir um banco de dados de teste considerável para garantir que esse tipo de regressão de desempenho seja capturado em CI. Eu criei um issue de acompanhamento para este trabalho, caso você queira seguir o andamento.
Isso tudo me fez pensar: E se você pudesse fazer teste de snapshot do plano de consulta do seu banco de dados SQL? Ou seja, você poderia comparar seus planos de consulta do banco de dados atual e candidato. Testes do plano de consulta SQL seriam como um benchmarking baseado em contagem de instrução para bancos de dados. O plano de consulta ajuda a indicar que pode haver um problema com o desempenho em tempo de execução, sem precisar realmente fazer o benchmark da consulta ao banco de dados. Eu criei um issue de acompanhamento para isso também. Por favor, sinta-se livre para adicionar um comentário com pensamentos ou qualquer trabalho anterior que você conheça!
Bônus Bug
Eu originalmente encontrei um bug no meu código de visão materializada. A consulta SQL parecia com isso:
SELECT branch.id, branch.uuid, branch.project_id, branch.name, branch.slug, branch.start_point_id, branch.created, branch.modified, testbed.id, testbed.uuid, testbed.project_id, testbed.name, testbed.slug, testbed.created, testbed.modified, benchmark.id, benchmark.uuid, benchmark.project_id, benchmark.name, benchmark.slug, benchmark.created, benchmark.modified, measure.id, measure.uuid, measure.project_id, measure.name, measure.slug, measure.units, measure.created, measure.modified, report.uuid, report_benchmark.iteration, report.start_time, report.end_time, version.number, version.hash, threshold.id, threshold.uuid, threshold.project_id, threshold.measure_id, threshold.branch_id, threshold.testbed_id, threshold.model_id, threshold.created, threshold.modified, model.id, model.uuid, model.threshold_id, model.test, model.min_sample_size, model.max_sample_size, model.window, model.lower_boundary, model.upper_boundary, model.created, model.replaced, alert.id, alert.uuid, alert.boundary_id, alert.boundary_limit, alert.status, alert.modified, metric_boundary.metric_id, metric_boundary.metric_uuid, metric_boundary.report_benchmark_id, metric_boundary.measure_id, metric_boundary.value, metric_boundary.lower_value, metric_boundary.upper_value, metric_boundary.boundary_id, metric_boundary.boundary_uuid, metric_boundary.threshold_id, metric_boundary.model_id, metric_boundary.baseline, metric_boundary.lower_limit, metric_boundary.upper_limit FROM (((((metric_boundary INNER JOIN ((report_benchmark INNER JOIN ((report INNER JOIN (version INNER JOIN (branch_version INNER JOIN branch ON (branch_version.branch_id = branch.id)) ON (branch_version.version_id = version.id)) ON (report.version_id = version.id)) INNER JOIN testbed ON (report.testbed_id = testbed.id)) ON (report_benchmark.report_id = report.id)) INNER JOIN benchmark ON (report_benchmark.benchmark_id = benchmark.id)) ON (metric_boundary.report_benchmark_id = report_benchmark.id)) INNER JOIN measure ON (metric_boundary.measure_id = measure.id)) LEFT OUTER JOIN threshold ON (metric_boundary.threshold_id = threshold.id)) LEFT OUTER JOIN model ON (metric_boundary.model_id = model.id)) LEFT OUTER JOIN alert ON (alert.boundary_id = metric_boundary.metric_id)) WHERE ((((((branch.uuid = 'a7d8366a-4f9b-452e-987e-2ae56e4bf4a3') AND (testbed.uuid = '5b4a6f3e-a27d-4cc3-a2ce-851dc6421e6e')) AND (benchmark.uuid = '88375e7c-f1e0-4cbb-bde1-bdb7773022ae')) AND (measure.uuid = 'b2275bbc-2044-4f8e-aecd-3c739bd861b9')) AND (report.start_time >= 0)) AND (report.end_time <= 1712838648197)) ORDER BY version.number, report.start_time, report_benchmark.iteration;Você vê o problema? Não. Eu também não!
O problema está justamente aqui:
LEFT OUTER JOIN alert ON (alert.boundary_id = metric_boundary.metric_id)Na verdade, deveria ser:
LEFT OUTER JOIN alert ON (alert.boundary_id = metric_boundary.boundary_id)Eu estava tentando ser muito esperto, e na minha estrutura de visão materializada Diesel eu permiti essa junção:
diesel::joinable!(alert -> metric_boundary (boundary_id));Eu assumi que essa macro era de alguma forma inteligente o suficiente
para relacionar o alert.boundary_id ao metric_boundary.boundary_id.
Mas, infelizmente, não era.
Parece que ela apenas escolheu a primeira coluna de metric_boundary (metric_id) para relacionar com alert.
Uma vez que descobri o bug, foi fácil de corrigir. Eu só tive que usar uma junção explícita na consulta Perf:
.left_join(schema::alert::table.on(view::metric_boundary::boundary_id.eq(schema::alert::boundary_id.nullable())))🐰 Isso é tudo, pessoal!