SQLite パフォーマンスチューニングがBencherを1200倍高速化した理由

Everett Pompeii
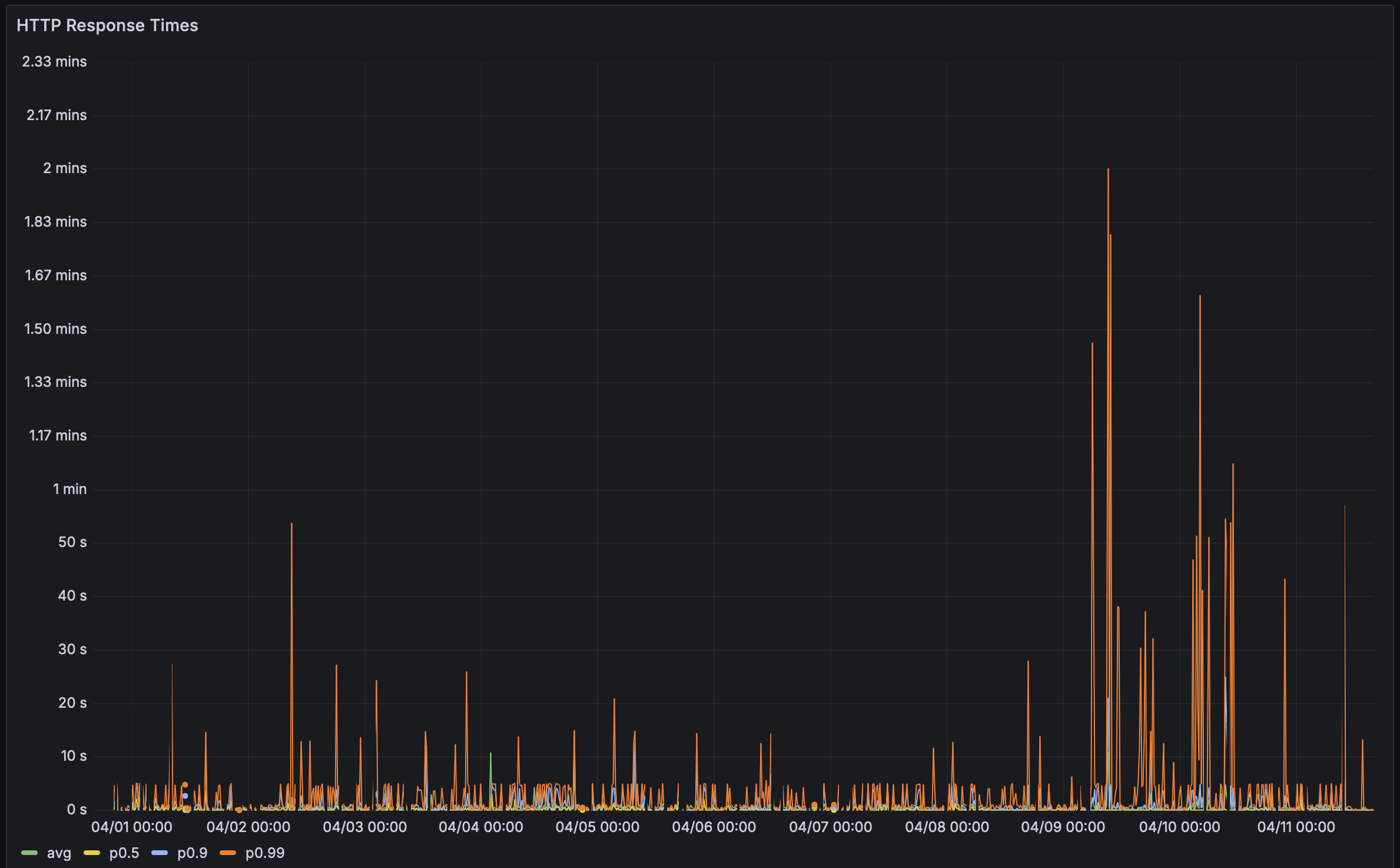
先週、ユーザーからフィードバックを受け取りました。彼らのBencherパフォーマンスページのロードに時間がかかるとのことでした。 そこで、調査してみることにしましたが、彼らが言っていた以上に遅かったです。 とても長いロード時間でした!恥ずかしいほど長いです。 特に、リードする連続ベンチマーキングツールにとっては。
過去には、Rustlsパフォーマンスページを試金石として使っていました。 彼らは112のベンチマークを持っており、一番印象的な連続ベンチマーキングの設定を持っています。 以前は約5秒でロードされていました。しかし今回は… ⏳👀 … 38.8秒かかりました! このような遅延があると、掘り下げなければなりませんでした。パフォーマンスのバグはやはりバグですからね!
背景
最初から、[Bencher Perf API][perf query]が性能的にもっとも要求されるエンドポイントの一つになることは明らかでした。 多くの人々が[ベンチマーク追跡ホイールを再発明][prior art]しなければならなかった主な理由は、既存のオフ・ザ・シェルフツールが必要とされる高い次元性を扱えないからだと考えています。 「高い次元性」とは、時間を超えて、そして複数の次元:[ブランチ][branch]、[テストベッド][testbed]、[ベンチマーク][benchmarks]、そして[測定][measures]を渡って性能を追跡できる能力のことを指します。 この5つの異なる次元をまたいでスライスしダイスする能力は、非常に複雑なモデルにつながります。
この本質的な複雑さとデータの性質のために、Bencher用に時系列データベースを使用することを検討しました。 しかし最終的に、SQLiteを使用することに落ち着きました。 スケールしないことを[行う][do things that dont scale]方が、実際に助けになるかどうかわからない完全に新しいデータベースアーキテクチャを学ぶために余計な時間を費やすよりも良いと判断しました。
時間が経つにつれて、Bencher Perf APIに対する要求も増えてきました。 元々は、プロットしたい次元をすべて手動で選択する必要がありました。 これは、ユーザーが有用なプロットにたどり着くための大きな摩擦を生み出しました。 これを解決するために、Perfページに[最も最近のレポートのリストを追加し][github issue 133]、デフォルトでは最も最近のレポートが選択されてプロットされるようにしました。 これは、最も最近の報告書に112個のベンチマークがある場合、その全部がプロットされることを意味します。 [閾値の境界][thresholds]を追跡して視覚化する能力も複雑さをさらに増す要因となりました。
これを踏まえて、いくつかのパフォーマンス関連の改善を行いました。 Perfプロットは最も最近のレポートからプロットを開始する必要があるため、[レポートAPI][reports api]をリファクタリングして、データベースへの単一の呼び出しでレポートの結果データを取得できるようにしました。反復する代わりです。 デフォルトのレポートクエリーの時間ウィンドウは、無制限ではなく、4週間に設定されました。 また、データベースハンドルの範囲を大幅に制限し、ロックの競合を軽減しました。 ユーザーとのコミュニケーションを助けるために、[Perfプロット][bencher v0317]と[次元タブ][bencher v045]の両方にステータスバーのスピナーを追加しました。
昨秋、四重ネストしたforループの代わりに全てのPerf結果を単一のクエリで取得するコンポジットクエリを試みましたが、失敗しました。 これは私が[Rust型システムの再帰限界][recusion limit]に達し、 スタックを繰り返しオーバーフローさせ、 38秒よりもはるかに長い(信じられないほど長い)コンパイル時間を苦しんで、 最終的には[SQLiteの合成セレクト文の最大項数の限界][sqlite limits]で行き詰まりました。
これら全ての経験を積んで、私はここで本格的に取り組み、パフォーマンスエンジニアの立場を固める必要があると知りました。 私は以前にSQLiteデータベースをプロファイリングしたことがなく、 正直なところ、_どんな_データベースをプロファイリングしたこともありませんでした。 ちょっと待ってください。[私のLinkedInプロファイル][linkedin epompeii]では、ほぼ2年間「データベース管理者」だったって書いてありますよね。 そして、_一度も_データベースのプロファイリングをしたことがないって‽ ええ、それはまた別の話でしょうね。
ORMからSQLクエリへ
最初の障害は、RustコードからSQLクエリを取り出すことでした。 Bencherのオブジェクトリレーショナルマッパー(ORM)として、Dieselを使用しています。
🐰 興味深い事実:Dieselは、自身の相対的な連続ベンチマークのためにBencherを使用しています。 Dieselのパフォーマンスページをチェックしてみてください!
Dieselはパラメーター化されたクエリを生成します。
SQLクエリとそのバインドパラメーターをデータベースに別々に送信します。
つまり、置換はデータベースによって行われます。
そのため、Dieselはユーザーに完全なクエリを提供することができません。
見つけた最善の方法は、the diesel::debug_query関数を使用して、パラメーター化されたクエリを出力することでした:
Query { sql: "SELECT `branch`.`id`, `branch`.`uuid`, `branch`.`project_id`, `branch`.`name`, `branch`.`slug`, `branch`.`start_point_id`, `branch`.`created`, `branch`.`modified`, `testbed`.`id`, `testbed`.`uuid`, `testbed`.`project_id`, `testbed`.`name`, `testbed`.`slug`, `testbed`.`created`, `testbed`.`modified`, `benchmark`.`id`, `benchmark`.`uuid`, `benchmark`.`project_id`, `benchmark`.`name`, `benchmark`.`slug`, `benchmark`.`created`, `benchmark`.`modified`, `measure`.`id`, `measure`.`uuid`, `measure`.`project_id`, `measure`.`name`, `measure`.`slug`, `measure`.`units`, `measure`.`created`, `measure`.`modified`, `report`.`uuid`, `report_benchmark`.`iteration`, `report`.`start_time`, `report`.`end_time`, `version`.`number`, `version`.`hash`, `threshold`.`id`, `threshold`.`uuid`, `threshold`.`project_id`, `threshold`.`measure_id`, `threshold`.`branch_id`, `threshold`.`testbed_id`, `threshold`.`model_id`, `threshold`.`created`, `threshold`.`modified`, `model`.`id`, `model`.`uuid`, `model`.`threshold_id`, `model`.`test`, `model`.`min_sample_size`, `model`.`max_sample_size`, `model`.`window`, `model`.`lower_boundary`, `model`.`upper_boundary`, `model`.`created`, `model`.`replaced`, `boundary`.`id`, `boundary`.`uuid`, `boundary`.`threshold_id`, `boundary`.`model_id`, `boundary`.`metric_id`, `boundary`.`baseline`, `boundary`.`lower_limit`, `boundary`.`upper_limit`, `alert`.`id`, `alert`.`uuid`, `alert`.`boundary_id`, `alert`.`boundary_limit`, `alert`.`status`, `alert`.`modified`, `metric`.`id`, `metric`.`uuid`, `metric`.`report_benchmark_id`, `metric`.`measure_id`, `metric`.`value`, `metric`.`lower_value`, `metric`.`upper_value` FROM (((`metric` INNER JOIN ((`report_benchmark` INNER JOIN ((`report` INNER JOIN (`version` INNER JOIN (`branch_version` INNER JOIN `branch` ON (`branch_version`.`branch_id` = `branch`.`id`)) ON (`branch_version`.`version_id` = `version`.`id`)) ON (`report`.`version_id` = `version`.`id`)) INNER JOIN `testbed` ON (`report`.`testbed_id` = `testbed`.`id`)) ON (`report_benchmark`.`report_id` = `report`.`id`)) INNER JOIN `benchmark` ON (`report_benchmark`.`benchmark_id` = `benchmark`.`id`)) ON (`metric`.`report_benchmark_id` = `report_benchmark`.`id`)) INNER JOIN `measure` ON (`metric`.`measure_id` = `measure`.`id`)) LEFT OUTER JOIN (((`boundary` INNER JOIN `threshold` ON (`boundary`.`threshold_id` = `threshold`.`id`)) INNER JOIN `model` ON (`boundary`.`model_id` = `model`.`id`)) LEFT OUTER JOIN `alert` ON (`alert`.`boundary_id` = `boundary`.`id`)) ON (`boundary`.`metric_id` = `metric`.`id`)) WHERE ((((((`branch`.`uuid` = ?) AND (`testbed`.`uuid` = ?)) AND (`benchmark`.`uuid` = ?)) AND (`measure`.`uuid` = ?)) AND (`report`.`start_time` >= ?)) AND (`report`.`end_time` <= ?)) ORDER BY `version`.`number`, `report`.`start_time`, `report_benchmark`.`iteration`", binds: [BranchUuid(a7d8366a-4f9b-452e-987e-2ae56e4bf4a3), TestbedUuid(5b4a6f3e-a27d-4cc3-a2ce-851dc6421e6e), BenchmarkUuid(88375e7c-f1e0-4cbb-bde1-bdb7773022ae), MeasureUuid(b2275bbc-2044-4f8e-aecd-3c739bd861b9), DateTime(2024-03-12T12:23:38Z), DateTime(2024-04-11T12:23:38Z)] }その後、手作業で清掃し、クエリを有効なSQLにパラメーター化しました:
SELECT branch.id, branch.uuid, branch.project_id, branch.name, branch.slug, branch.start_point_id, branch.created, branch.modified, testbed.id, testbed.uuid, testbed.project_id, testbed.name, testbed.slug, testbed.created, testbed.modified, benchmark.id, benchmark.uuid, benchmark.project_id, benchmark.name, benchmark.slug, benchmark.created, benchmark.modified, measure.id, measure.uuid, measure.project_id, measure.name, measure.slug, measure.units, measure.created, measure.modified, report.uuid, report_benchmark.iteration, report.start_time, report.end_time, version.number, version.hash, threshold.id, threshold.uuid, threshold.project_id, threshold.measure_id, threshold.branch_id, threshold.testbed_id, threshold.model_id, threshold.created, threshold.modified, model.id, model.uuid, model.threshold_id, model.test, model.min_sample_size, model.max_sample_size, model.window, model.lower_boundary, model.upper_boundary, model.created, model.replaced, boundary.id, boundary.uuid, boundary.threshold_id, boundary.model_id, boundary.metric_id, boundary.baseline, boundary.lower_limit, boundary.upper_limit, alert.id, alert.uuid, alert.boundary_id, alert.boundary_limit, alert.status, alert.modified, metric.id, metric.uuid, metric.report_benchmark_id, metric.measure_id, metric.value, metric.lower_value, metric.upper_value FROM (((metric INNER JOIN ((report_benchmark INNER JOIN ((report INNER JOIN (version INNER JOIN (branch_version INNER JOIN branch ON (branch_version.branch_id = branch.id)) ON (branch_version.version_id = version.id)) ON (report.version_id = version.id)) INNER JOIN testbed ON (report.testbed_id = testbed.id)) ON (report_benchmark.report_id = report.id)) INNER JOIN benchmark ON (report_benchmark.benchmark_id = benchmark.id)) ON (metric.report_benchmark_id = report_benchmark.id)) INNER JOIN measure ON (metric.measure_id = measure.id)) LEFT OUTER JOIN (((boundary INNER JOIN threshold ON (boundary.threshold_id = threshold.id)) INNER JOIN model ON (boundary.model_id = model.id)) LEFT OUTER JOIN alert ON (alert.boundary_id = boundary.id)) ON (boundary.metric_id = metric.id)) WHERE ((((((branch.uuid = 'a7d8366a-4f9b-452e-987e-2ae56e4bf4a3') AND (testbed.uuid = '5b4a6f3e-a27d-4cc3-a2ce-851dc6421e6e')) AND (benchmark.uuid = '88375e7c-f1e0-4cbb-bde1-bdb7773022ae')) AND (measure.uuid = 'b2275bbc-2044-4f8e-aecd-3c739bd861b9')) AND (report.start_time >= 0)) AND (report.end_time <= 1712838648197)) ORDER BY version.number, report.start_time, report_benchmark.iteration;もっと良い方法をご存知でしたら、教えてください! これは、プロジェクトのメンテナーが提案した方法ですので、それに従いました。 SQLクエリを手に入れたので、ついに…大量のドキュメントを読む準備が整いました。
SQLite クエリプランナー
SQLiteのウェブサイトには、クエリプランナーに関する素晴らしいドキュメントがあります。 これは、SQLiteがどのようにSQLクエリを実行するか、どのインデックスが役立つか、また、フルテーブルスキャンのように注意すべき操作が何かを正確に説明しています。
Perfクエリの実行方法をクエリプランナーで確認するために、新しいツールをツールベルトに追加する必要がありました: EXPLAIN QUERY PLAN
SQLクエリの前に EXPLAIN QUERY PLAN を付けるか、クエリの前に .eqp on ドットコマンドを実行するかのどちらかです。
どちらにしても、こんな感じの結果が得られました:
QUERY PLAN|--MATERIALIZE (join-5)| |--SCAN boundary| |--SEARCH threshold USING INTEGER PRIMARY KEY (rowid=?)| |--SEARCH model USING INTEGER PRIMARY KEY (rowid=?)| |--BLOOM FILTER ON alert (boundary_id=?)| `--SEARCH alert USING AUTOMATIC COVERING INDEX (boundary_id=?) LEFT-JOIN|--SEARCH branch USING INDEX sqlite_autoindex_branch_1 (uuid=?)|--SEARCH measure USING INDEX sqlite_autoindex_measure_1 (uuid=?)|--SEARCH benchmark USING INDEX sqlite_autoindex_benchmark_1 (uuid=?)|--SEARCH testbed USING INDEX sqlite_autoindex_testbed_1 (uuid=?)|--SCAN metric|--SEARCH report_benchmark USING INTEGER PRIMARY KEY (rowid=?)|--SEARCH report USING INTEGER PRIMARY KEY (rowid=?)|--SEARCH version USING INTEGER PRIMARY KEY (rowid=?)|--SEARCH branch_version USING COVERING INDEX sqlite_autoindex_branch_version_1 (branch_id=? AND version_id=?)|--BLOOM FILTER ON (join-5) (metric_id=?)|--SEARCH (join-5) USING AUTOMATIC COVERING INDEX (metric_id=?) LEFT-JOIN`--USE TEMP B-TREE FOR ORDER BYおやおや! ここにはたくさんのことがありますね。 しかし、私にとって特に目立ったのは3つの大きなことでした:
- SQLiteは、
boundaryテーブルの 全体 をスキャンするフライでマテリアライズドビューを作成しています - 次に、SQLiteは
metricテーブルの 全体 をスキャンしています - SQLiteは二つのフライでインデックスを作成しています
そして、metric と boundary テーブルの大きさはどの程度でしょうか?
実はこれらは二つの最大のテーブルで、Metrics と Boundariesが格納されている場所です。
これが私の最初のSQLiteパフォーマンスチューニングの経験だったので、変更を加える前に専門家に相談したいと思いました。
SQLite エキスパート
SQLiteには、.expert コマンドで有効にできる実験的な「エキスパート」モードがあります。
このモードはクエリに対してインデックスの提案を行なうため、試してみることにしました。
これがその提案です:
CREATE INDEX report_benchmark_idx_fc6f3e5b ON report_benchmark(report_id, benchmark_id);CREATE INDEX report_idx_55aae6d8 ON report(testbed_id, end_time);CREATE INDEX alert_idx_e1882f70 ON alert(boundary_id);
MATERIALIZE (join-5)SCAN boundarySEARCH threshold USING INTEGER PRIMARY KEY (rowid=?)SEARCH model USING INTEGER PRIMARY KEY (rowid=?)SEARCH alert USING INDEX alert_idx_e1882f70 (boundary_id=?) LEFT-JOINSEARCH branch USING INDEX sqlite_autoindex_branch_1 (uuid=?)SEARCH benchmark USING INDEX sqlite_autoindex_benchmark_1 (uuid=?)SEARCH testbed USING INDEX sqlite_autoindex_testbed_1 (uuid=?)SEARCH measure USING INDEX sqlite_autoindex_measure_1 (uuid=?)SEARCH report USING INDEX report_idx_55aae6d8 (testbed_id=? AND end_time<?)SEARCH version USING INTEGER PRIMARY KEY (rowid=?)SEARCH branch_version USING COVERING INDEX sqlite_autoindex_branch_version_1 (branch_id=? AND version_id=?)SEARCH report_benchmark USING INDEX report_benchmark_idx_fc6f3e5b (report_id=? AND benchmark_id=?)SEARCH metric USING INDEX sqlite_autoindex_metric_2 (report_benchmark_id=? AND measure_id=?)BLOOM FILTER ON (join-5) (metric_id=?)SEARCH (join-5) USING AUTOMATIC COVERING INDEX (metric_id=?) LEFT-JOINUSE TEMP B-TREE FOR ORDER BYこれは間違いなく改善です!
metric テーブルのスキャンと、その場で作成されるインデックスの両方をなくしました。
正直、自分だけでは最初の2つのインデックスは思いつきませんでした。
ありがとう、SQLite エキスパート!
CREATE INDEX index_report_testbed_end_time ON report(testbed_id, end_time);CREATE INDEX index_report_benchmark ON report_benchmark(report_id, benchmark_id);CREATE INDEX index_alert_boundary ON alert(boundary_id);これで残すは、その場でマテリアライズされるビューをなくすだけです。
マテリアライズド・ビュー
昨年、しきい値の境界を追跡して視覚化する機能を追加したとき、
データベースモデルにおいて一つの決断を迫られました。
メトリックとそれに対応する境界の間には1対0または1の関係があります。
つまり、メトリックはゼロまたは1つの境界に関連付けることができ、境界は1つのメトリックにしか関連付けることができません。
したがって、metricテーブルを拡張してすべてのboundaryデータを含め、すべてのboundary関連フィールドをNULL許容にすることもできました。
または、metricテーブルにUNIQUE外部キーを持つ別のboundaryテーブルを作成することもできました。
私にとって後者の選択肢の方がはるかにクリーンに感じられ、パフォーマンスに関する懸念は後で対処できると考えました。
これらはmetricテーブルとboundaryテーブルを作成するために使用された実際のクエリです:
CREATE TABLE metric ( id INTEGER PRIMARY KEY NOT NULL, uuid TEXT NOT NULL UNIQUE, report_benchmark_id INTEGER NOT NULL, measure_id INTEGER NOT NULL, value DOUBLE NOT NULL, lower_value DOUBLE, upper_value DOUBLE, FOREIGN KEY (report_benchmark_id) REFERENCES report_benchmark (id) ON DELETE CASCADE, FOREIGN KEY (measure_id) REFERENCES measure (id), UNIQUE(report_benchmark_id, measure_id));CREATE TABLE boundary ( id INTEGER PRIMARY KEY NOT NULL, uuid TEXT NOT NULL UNIQUE, threshold_id INTEGER NOT NULL, statistic_id INTEGER NOT NULL, metric_id INTEGER NOT NULL UNIQUE, baseline DOUBLE NOT NULL, lower_limit DOUBLE, upper_limit DOUBLE, FOREIGN KEY (threshold_id) REFERENCES threshold (id), FOREIGN KEY (statistic_id) REFERENCES statistic (id), FOREIGN KEY (metric_id) REFERENCES metric (id) ON DELETE CASCADE);そして、「後で」が来ました。
単純にboundary(metric_id)用のインデックスを追加しようと試みましたが、それは役に立ちませんでした。
その理由は、Perfクエリがmetricテーブルから発生しているため、
その関係が0/1または別の言い方をすると、NULL許容であるためにスキャン(O(n))が必要で、検索(O(log(n)))ができないということにあると考えています。
これは私に一つの明確な選択肢を残しました。
metricとboundaryの関係をフラット化したマテリアライズド・ビューを作成する必要がありました
これにより、SQLiteがその場でマテリアライズド・ビューを作成することを避けられます。
これが新しいmetric_boundaryマテリアライズド・ビューを作成するために使用したクエリです:
CREATE VIEW metric_boundary ASSELECT metric.id AS metric_id, metric.uuid AS metric_uuid, metric.report_benchmark_id, metric.measure_id, metric.value, metric.lower_value, metric.upper_value, boundary.id, boundary.uuid AS boundary_uuid, boundary.threshold_id AS threshold_id, boundary.model_id, boundary.baseline, boundary.lower_limit, boundary.upper_limitFROM metric LEFT OUTER JOIN boundary ON (boundary.metric_id = metric.id);この解決策では、実行時のパフォーマンスのためにスペースをトレードオフしています。 どれくらいのスペースでしょうか? 驚くことに、このビューがデータベースの2つの最大のテーブルに対して行われているにも関わらず、約4%の増加にとどまります。 何よりも、この解決策によってソースコードで思い通りのことを行うことができます。
Diseelでマテリアライズド・ビューを作成する のは驚くほど簡単でした。 私が普段のスキーマを生成するときにDieselが使用しているのと全く同じマクロを使用するだけでした。 言うまでもなく、この経験を通じてDieselをずっと評価するようになりました。 すべての詳細についてはボーナスバグを参照してください。
まとめ
3つの新しいインデックスとマテリアライズドビューを追加したことで、クエリプランナーが示す内容は以下の通りです:
QUERY PLAN|--SEARCH branch USING INDEX sqlite_autoindex_branch_1 (uuid=?)|--SEARCH testbed USING INDEX sqlite_autoindex_testbed_1 (uuid=?)|--SEARCH benchmark USING INDEX sqlite_autoindex_benchmark_1 (uuid=?)|--SEARCH measure USING INDEX sqlite_autoindex_measure_1 (uuid=?)|--SEARCH report USING INDEX index_report_testbed_end_time (testbed_id=? AND end_time<?)|--SEARCH version USING INTEGER PRIMARY KEY (rowid=?)|--SEARCH branch_version USING COVERING INDEX sqlite_autoindex_branch_version_1 (branch_id=? AND version_id=?)|--SEARCH report_benchmark USING INDEX index_report_benchmark (report_id=? AND benchmark_id=?)|--SEARCH metric USING INDEX sqlite_autoindex_metric_2 (report_benchmark_id=? AND measure_id=?)|--SEARCH boundary USING INDEX sqlite_autoindex_boundary_2 (metric_id=?) LEFT-JOIN|--SEARCH threshold USING INTEGER PRIMARY KEY (rowid=?) LEFT-JOIN|--SEARCH model USING INTEGER PRIMARY KEY (rowid=?) LEFT-JOIN|--SEARCH alert USING INDEX index_alert_boundary (boundary_id=?) LEFT-JOIN`--USE TEMP B-TREE FOR ORDER BYこれらの美しいSEARCHがすべて既存のインデックスを使用しているのを見てください! 🥲
そして、私の変更を本番環境にデプロイした後:
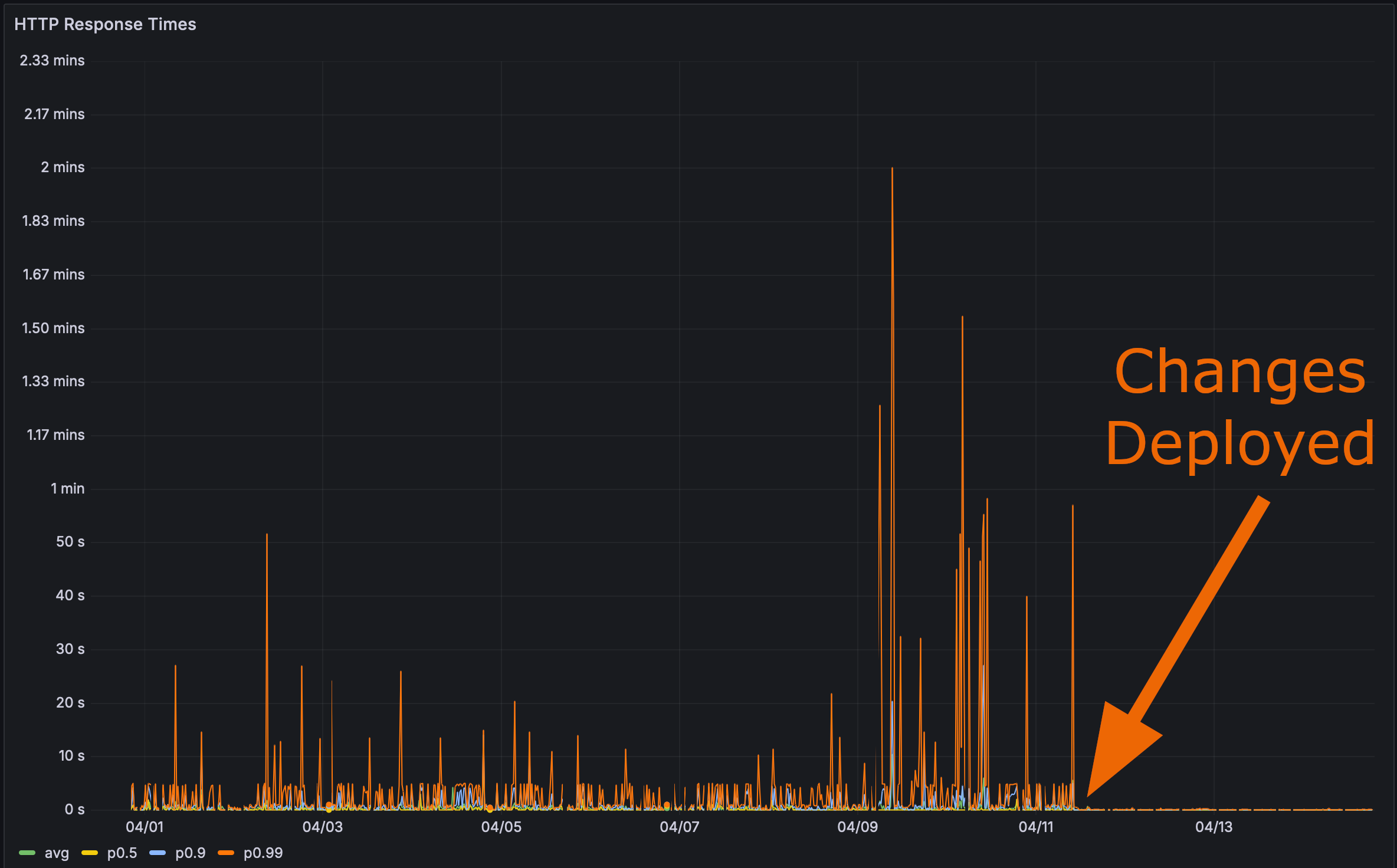
これで最終テストの時間です。 Rustlsパフォーマンスページの読み込み速度はどれほど速いですか?
ここにアンカータグを用意しました。クリックしてからページを更新してください。
パフォーマンスは重要です
Bencher: 連続ベンチマーキング

Bencherは、継続的ベンチマーキングツールのスイートです。 パフォーマンスの後退があなたのユーザーに影響を与えたことはありますか? Bencherなら、それが起こるのを防げた可能性があります。 Bencherは、パフォーマンスの低下が_マージされる_前に検出し、防止することを可能にします。
- 実行: _まったく同じ_ベアメタルランナーとお気に入りのベンチマーキングツールを使用して、ベンチマークをローカルまたはCIで実行します。
bencherCLIはベアメタル上でのベンチマークの実行をオーケストレーションし、その結果を保存します。 - 追跡: ベンチマークの結果を時間と共に追跡します。ソースブランチ、テストベッド、測定基準に基づいてBencherのWebコンソールを使用して結果を監視、クエリ、グラフ化します。
- キャッチ: _まったく同じ_ベアメタルハードウェアを使用して、ローカルまたはCIでパフォーマンスの後退をキャッチします。Bencherは最先端のカスタマイズ可能な分析を使用して、パフォーマンスの後退がマージされる前にそれを検出します。
機能の後退を防ぐためにユニットテストが実行されるのと同じ理由で、Bencherを使用してベンチマークを実行してパフォーマンスの後退を防ぐべきです。パフォーマンスのバグはバグです!
パフォーマンスの回帰を捉えるのを開始してください - Bencher Cloudを無料で試す。
ドッグフーディングについての補足
既にBencherでBencherをドッグフーディングしていますが、既存のベンチマークハーネスアダプタは、マイクロベンチマーク用のものばかりです。 多くのHTTPハーネスは、実際にはロードテスト用のハーネスですが、ロードテストとベンチマーキングは異なります。 さらに、私はBencherをロードテストに拡大する予定は近いうちにはないです。 それは、非常に異なる使用事例であり、たとえば時系列データベースのような、全く異なる設計上の考慮が必要になるでしょう。 たとえロードテストを導入していたとしても、この問題を発見するためには、実際には本番データの新しいプルに対して実行する必要があったでしょう。 これらの変更に対するパフォーマンスの違いは、私のテストデータベースでは無視できるものでした。
テストデータベースのベンチマーク結果を見るにはクリックしてください
Before(変更前):
Run Time: real 0.081 user 0.019532 sys 0.005618Run Time: real 0.193 user 0.022192 sys 0.003368Run Time: real 0.070 user 0.021390 sys 0.003369Run Time: real 0.062 user 0.022676 sys 0.002290Run Time: real 0.057 user 0.012053 sys 0.006638Run Time: real 0.052 user 0.018797 sys 0.002016Run Time: real 0.059 user 0.022806 sys 0.002437Run Time: real 0.066 user 0.021869 sys 0.004525Run Time: real 0.060 user 0.021037 sys 0.002864Run Time: real 0.059 user 0.018397 sys 0.003668インデックスとマテリアライズドビューを追加後:
Run Time: real 0.063 user 0.008671 sys 0.004898Run Time: real 0.053 user 0.010671 sys 0.003334Run Time: real 0.053 user 0.010337 sys 0.002884Run Time: real 0.052 user 0.008087 sys 0.002165Run Time: real 0.045 user 0.007265 sys 0.002123Run Time: real 0.038 user 0.008793 sys 0.002240Run Time: real 0.040 user 0.011022 sys 0.002420Run Time: real 0.049 user 0.010004 sys 0.002831Run Time: real 0.059 user 0.010472 sys 0.003661Run Time: real 0.046 user 0.009968 sys 0.002628これらすべてから、Perf APIエンドポイントに対して実行するマイクロベンチマークを作成し、Bencherでその結果をドッグフーディングするべきだと思い至りました。 CIでこのようなパフォーマンスの退行を捉えるためには、かなりのサイズのテストデータベースが必要になります。 この作業について追跡するissueを作成しました。興味があればフォローしてください。
しかし、これで思いついたことがあります: あなたのSQLデータベースクエリプランのsnapshot testingができたらどうでしょう? つまり、現在のSQLデータベースクエリプランと候補のSQLデータベースクエリプランを比較できるということです。 SQLクエリプランテストは、データベースの命令数に基づくベンチマーキングのようなものになります。 クエリプランは、実際にデータベースクエリをベンチマークすることなく、ランタイムパフォーマンスに問題があるかもしれないことを示してくれます。 これについても追跡するissueを作成しました。 ぜひ、思いつきや知っている先行技術についてコメントを追加してください!
ボーナス バグ
私はもともと、[マテリアライズドビュー][materialized view] のコードにバグがありました。 SQLクエリはこのように見えました:
SELECT branch.id, branch.uuid, branch.project_id, branch.name, branch.slug, branch.start_point_id, branch.created, branch.modified, testbed.id, testbed.uuid, testbed.project_id, testbed.name, testbed.slug, testbed.created, testbed.modified, benchmark.id, benchmark.uuid, benchmark.project_id, benchmark.name, benchmark.slug, benchmark.created, benchmark.modified, measure.id, measure.uuid, measure.project_id, measure.name, measure.slug, measure.units, measure.created, measure.modified, report.uuid, report_benchmark.iteration, report.start_time, report.end_time, version.number, version.hash, threshold.id, threshold.uuid, threshold.project_id, threshold.measure_id, threshold.branch_id, threshold.testbed_id, threshold.model_id, threshold.created, threshold.modified, model.id, model.uuid, model.threshold_id, model.test, model.min_sample_size, model.max_sample_size, model.window, model.lower_boundary, model.upper_boundary, model.created, model.replaced, alert.id, alert.uuid, alert.boundary_id, alert.boundary_limit, alert.status, alert.modified, metric_boundary.metric_id, metric_boundary.metric_uuid, metric_boundary.report_benchmark_id, metric_boundary.measure_id, metric_boundary.value, metric_boundary.lower_value, metric_boundary.upper_value, metric_boundary.boundary_id, metric_boundary.boundary_uuid, metric_boundary.threshold_id, metric_boundary.model_id, metric_boundary.baseline, metric_boundary.lower_limit, metric_boundary.upper_limit FROM (((((metric_boundary INNER JOIN ((report_benchmark INNER JOIN ((report INNER JOIN (version INNER JOIN (branch_version INNER JOIN branch ON (branch_version.branch_id = branch.id)) ON (branch_version.version_id = version.id)) ON (report.version_id = version.id)) INNER JOIN testbed ON (report.testbed_id = testbed.id)) ON (report_benchmark.report_id = report.id)) INNER JOIN benchmark ON (report_benchmark.benchmark_id = benchmark.id)) ON (metric_boundary.report_benchmark_id = report_benchmark.id)) INNER JOIN measure ON (metric_boundary.measure_id = measure.id)) LEFT OUTER JOIN threshold ON (metric_boundary.threshold_id = threshold.id)) LEFT OUTER JOIN model ON (metric_boundary.model_id = model.id)) LEFT OUTER JOIN alert ON (alert.boundary_id = metric_boundary.metric_id)) WHERE ((((((branch.uuid = 'a7d8366a-4f9b-452e-987e-2ae56e4bf4a3') AND (testbed.uuid = '5b4a6f3e-a27d-4cc3-a2ce-851dc6421e6e')) AND (benchmark.uuid = '88375e7c-f1e0-4cbb-bde1-bdb7773022ae')) AND (measure.uuid = 'b2275bbc-2044-4f8e-aecd-3c739bd861b9')) AND (report.start_time >= 0)) AND (report.end_time <= 1712838648197)) ORDER BY version.number, report.start_time, report_benchmark.iteration;問題点を見つけられますか?いいえ、私もです!
問題はここにあります:
LEFT OUTER JOIN alert ON (alert.boundary_id = metric_boundary.metric_id)実際には次のようにすべきでした:
LEFT OUTER JOIN alert ON (alert.boundary_id = metric_boundary.boundary_id)私は賢く行こうとしすぎていましたが、 Dieselマテリアライズドビュースキーマでは、この結合を許可していました:
diesel::joinable!(alert -> metric_boundary (boundary_id));このマクロが何らかの方法でalert.boundary_idをmetric_boundary.boundary_idと関連付けるのに十分賢いと思っていました。
しかし、残念ながらそうではありませんでした。
metric_boundaryの最初の列(metric_id)をalertと関連付けるように選択したようです。
バグを発見した一度、それを修正するのは簡単でした。 Perfクエリで明示的な結合を使う必要がありました:
.left_join(schema::alert::table.on(view::metric_boundary::boundary_id.eq(schema::alert::boundary_id.nullable())))🐰 以上です!