Warum SQLite Performance-Tuning Bencher 1200x schneller machte

Everett Pompeii
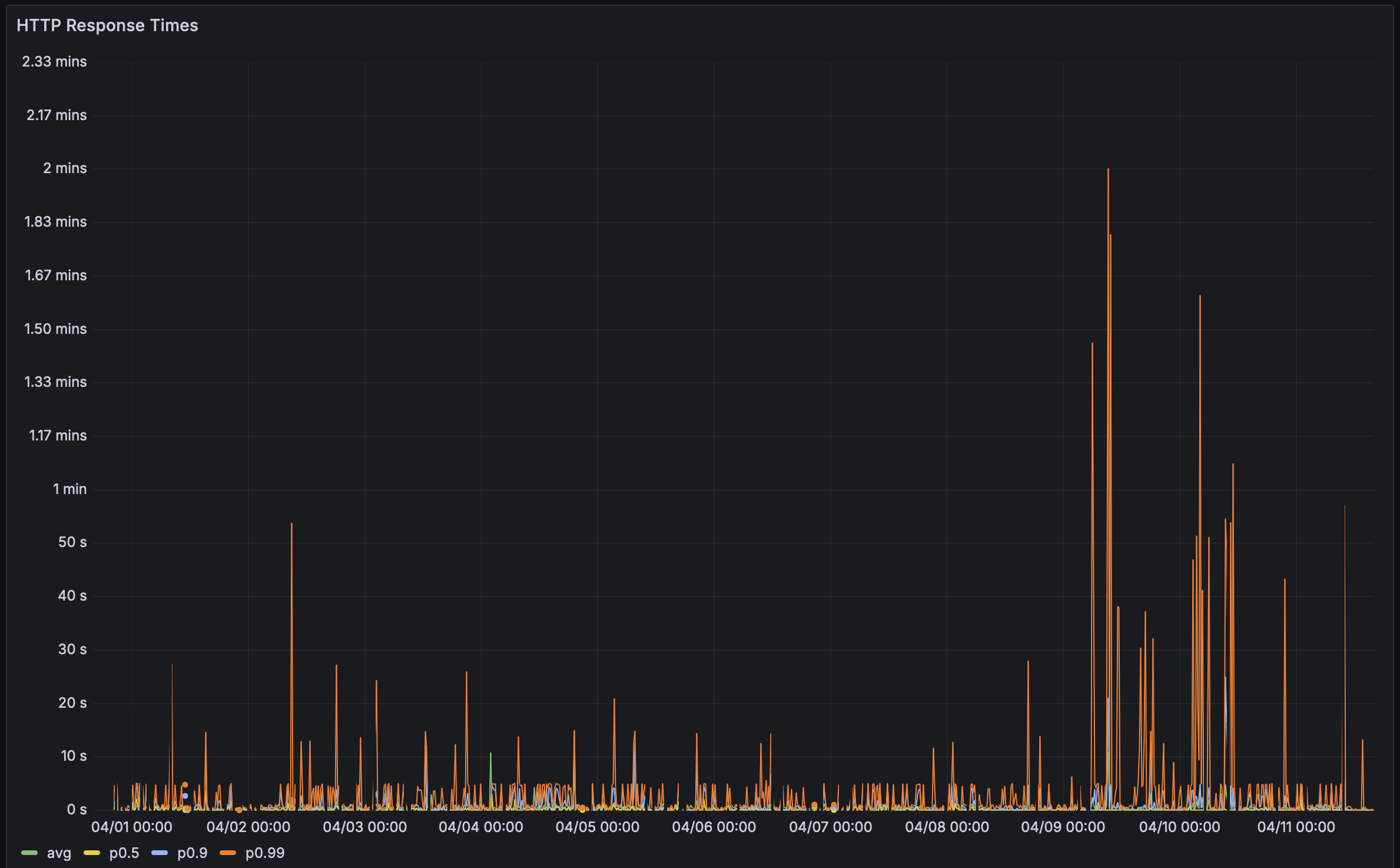
Letzte Woche erhielt ich ein Feedback von einem Nutzer, dass ihre Bencher Perf-Seite eine Weile zum Laden brauchte. Also entschied ich mich, es selbst zu überprüfen, und oh, Mann, waren sie nett. Es dauerte sooo lange zu laden! Peinlich lange. Vor allem für das führende Continuous Benchmarking Tool.
In der Vergangenheit habe ich die Rustls Perf-Seite als meinen Lackmustest verwendet. Sie haben 112 Benchmarks und eine der beeindruckendsten Continuous Benchmarking-Einrichtungen, die es gibt. Früher dauerte es etwa 5 Sekunden zum Laden. Dieses Mal dauerte es… ⏳👀 … 38,8 Sekunden! Bei einer solchen Latenzzeit musste ich tiefer graben. Performance-Bugs sind schließlich auch Bugs!
Hintergrund
Von Anfang an war mir klar, dass die Bencher Perf API eine der leistungsanspruchsvollsten Endpunkte sein würde. Ich glaube, der Hauptgrund, warum so viele Leute das Rad der Leistungsmessung neu erfinden mussten, liegt daran, dass die bestehenden Tools von der Stange die erforderliche hohe Dimensionalität nicht bewältigen. Mit “hoher Dimensionalität” meine ich die Fähigkeit, die Leistung über die Zeit und über mehrere Dimensionen hinweg zu verfolgen: Branches, Testbeds, Benchmarks und Maße. Diese Fähigkeit, quer durch fünf verschiedene Dimensionen zu schneiden und zu würfeln, führt zu einem sehr komplexen Modell.
Aufgrund dieser inhärenten Komplexität und der Art der Daten erwog ich die Verwendung einer Zeitreihendatenbank für Bencher. Letztendlich entschied ich mich jedoch dafür, SQLite zu verwenden. Ich fand, es war besser, Dinge zu tun, die sich nicht skalieren lassen, anstatt zusätzliche Zeit damit zu verbringen, eine völlig neue Datenbankarchitektur zu erlernen, die möglicherweise gar nicht hilft.
Im Laufe der Zeit haben auch die Anforderungen an die Bencher Perf API zugenommen. Ursprünglich mussten Sie alle Dimensionen, die Sie plotten wollten, manuell auswählen. Dies schuf viel Reibung für die Benutzer, um zu einem nützlichen Plot zu gelangen. Um dies zu lösen, fügte ich eine Liste der neuesten Berichte zu den Perf-Seiten hinzu, und standardmäßig wurde der neueste Bericht ausgewählt und geplottet. Das bedeutet, dass, wenn es im neuesten Bericht 112 Benchmarks gab, alle 112 geplottet wurden. Das Modell wurde noch komplizierter mit der Fähigkeit, Schwellenwertgrenzen zu verfolgen und zu visualisieren.
Mit diesem Hintergrund machte ich einige leistungsbezogene Verbesserungen. Da der Perf-Plot den neuesten Bericht benötigt, um mit dem Plotten zu beginnen, refaktorierte ich die Berichte-API, um die Ergebnisdaten eines Berichts mit einem einzigen Aufruf der Datenbank zu erhalten, anstatt zu iterieren. Das Zeitfenster für die Standardberichtabfrage wurde auf vier Wochen festgelegt, anstatt unbegrenzt zu sein. Ich beschränkte auch drastisch den Umfang aller Datenbank-Handles, wodurch der Lock-Wettbewerb verringert wurde. Um den Benutzern zu helfen, fügte ich einen Statusleisten-Spinner sowohl für den Perf-Plot als auch für die Dimension-Reiter hinzu.
Ich hatte auch einen erfolglosen Versuch im letzten Herbst, eine zusammengesetzte Abfrage zu verwenden, um alle Perf-Ergebnisse in einer einzigen Abfrage zu erhalten, anstatt eine vierfach geschachtelte Schleife zu verwenden. Dies führte dazu, dass ich an das Rekursion-Grenzwertsystem von Rust stieß, wiederholt den Stack überlief, wahnsinnige (viel länger als 38 Sekunden) Kompilierzeiten durchlitt und schließlich in einer Sackgasse bei SQLite’s maximaler Anzahl von Begriffen in einer zusammengesetzten SELECT-Anweisung endete.
Mit all dem unter meinem Gürtel wusste ich, dass ich mich hier wirklich einarbeiten musste und meine Leistungsingenieur-Hose anziehen. Ich hatte noch nie zuvor eine SQLite-Datenbank profiliert, und ehrlich gesagt, hatte ich noch nie irgendeine Datenbank zuvor profiliert. Nun ja, magst du vielleicht denken. Mein LinkedIn-Profil sagt, ich war fast zwei Jahre lang “Datenbankadministrator”. Und ich habe nie eine Datenbank profiliert‽ Ja. Das ist wohl eine Geschichte für ein andermal.
Von ORM zu SQL-Query
Das erste Hindernis, auf das ich stieß, war das Herausfinden der SQL-Abfrage aus meinem Rust-Code. Ich verwende Diesel als den Object-Relational Mapper (ORM) für Bencher.
🐰 Lustige Tatsache: Diesel verwendet Bencher für ihr Relatives Kontinuierliches Benchmarking. Schaut euch die Diesel Perf Seite an!
Diesel erstellt parametrisierte Abfragen.
Es sendet die SQL-Abfrage und ihre Bindparameter separat an die Datenbank.
Das heißt, die Substitution wird von der Datenbank durchgeführt.
Daher kann Diesel dem Benutzer keine vollständige Abfrage zur Verfügung stellen.
Die beste Methode, die ich fand, war die Verwendung der Funktion diesel::debug_query, um die parametrisierte Abfrage auszugeben:
Query { sql: "SELECT `branch`.`id`, `branch`.`uuid`, `branch`.`project_id`, `branch`.`name`, `branch`.`slug`, `branch`.`start_point_id`, `branch`.`created`, `branch`.`modified`, `testbed`.`id`, `testbed`.`uuid`, `testbed`.`project_id`, `testbed`.`name`, `testbed`.`slug`, `testbed`.`created`, `testbed`.`modified`, `benchmark`.`id`, `benchmark`.`uuid`, `benchmark`.`project_id`, `benchmark`.`name`, `benchmark`.`slug`, `benchmark`.`created`, `benchmark`.`modified`, `measure`.`id`, `measure`.`uuid`, `measure`.`project_id`, `measure`.`name`, `measure`.`slug`, `measure`.`units`, `measure`.`created`, `measure`.`modified`, `report`.`uuid`, `report_benchmark`.`iteration`, `report`.`start_time`, `report`.`end_time`, `version`.`number`, `version`.`hash`, `threshold`.`id`, `threshold`.`uuid`, `threshold`.`project_id`, `threshold`.`measure_id`, `threshold`.`branch_id`, `threshold`.`testbed_id`, `threshold`.`model_id`, `threshold`.`created`, `threshold`.`modified`, `model`.`id`, `model`.`uuid`, `model`.`threshold_id`, `model`.`test`, `model`.`min_sample_size`, `model`.`max_sample_size`, `model`.`window`, `model`.`lower_boundary`, `model`.`upper_boundary`, `model`.`created`, `model`.`replaced`, `boundary`.`id`, `boundary`.`uuid`, `boundary`.`threshold_id`, `boundary`.`model_id`, `boundary`.`metric_id`, `boundary`.`baseline`, `boundary`.`lower_limit`, `boundary`.`upper_limit`, `alert`.`id`, `alert`.`uuid`, `alert`.`boundary_id`, `alert`.`boundary_limit`, `alert`.`status`, `alert`.`modified`, `metric`.`id`, `metric`.`uuid`, `metric`.`report_benchmark_id`, `metric`.`measure_id`, `metric`.`value`, `metric`.`lower_value`, `metric`.`upper_value` FROM (((`metric` INNER JOIN ((`report_benchmark` INNER JOIN ((`report` INNER JOIN (`version` INNER JOIN (`branch_version` INNER JOIN `branch` ON (`branch_version`.`branch_id` = `branch`.`id`)) ON (`branch_version`.`version_id` = `version`.`id`)) ON (`report`.`version_id` = `version`.`id`)) INNER JOIN `testbed` ON (`report`.`testbed_id` = `testbed`.`id`)) ON (`report_benchmark`.`report_id` = `report`.`id`)) INNER JOIN `benchmark` ON (`report_benchmark`.`benchmark_id` = `benchmark`.`id`)) ON (`metric`.`report_benchmark_id` = `report_benchmark`.`id`)) INNER JOIN `measure` ON (`metric`.`measure_id` = `measure`.`id`)) LEFT OUTER JOIN (((`boundary` INNER JOIN `threshold` ON (`boundary`.`threshold_id` = `threshold`.`id`)) INNER JOIN `model` ON (`boundary`.`model_id` = `model`.`id`)) LEFT OUTER JOIN `alert` ON (`alert`.`boundary_id` = `boundary`.`id`)) ON (`boundary`.`metric_id` = `metric`.`id`)) WHERE ((((((`branch`.`uuid` = ?) AND (`testbed`.`uuid` = ?)) AND (`benchmark`.`uuid` = ?)) AND (`measure`.`uuid` = ?)) AND (`report`.`start_time` >= ?)) AND (`report`.`end_time` <= ?)) ORDER BY `version`.`number`, `report`.`start_time`, `report_benchmark`.`iteration`", binds: [BranchUuid(a7d8366a-4f9b-452e-987e-2ae56e4bf4a3), TestbedUuid(5b4a6f3e-a27d-4cc3-a2ce-851dc6421e6e), BenchmarkUuid(88375e7c-f1e0-4cbb-bde1-bdb7773022ae), MeasureUuid(b2275bbc-2044-4f8e-aecd-3c739bd861b9), DateTime(2024-03-12T12:23:38Z), DateTime(2024-04-11T12:23:38Z)] }Und dann die manuelle Aufbereitung und Parametrisierung der Abfrage in gültiges SQL:
SELECT branch.id, branch.uuid, branch.project_id, branch.name, branch.slug, branch.start_point_id, branch.created, branch.modified, testbed.id, testbed.uuid, testbed.project_id, testbed.name, testbed.slug, testbed.created, testbed.modified, benchmark.id, benchmark.uuid, benchmark.project_id, benchmark.name, benchmark.slug, benchmark.created, benchmark.modified, measure.id, measure.uuid, measure.project_id, measure.name, measure.slug, measure.units, measure.created, measure.modified, report.uuid, report_benchmark.iteration, report.start_time, report.end_time, version.number, version.hash, threshold.id, threshold.uuid, threshold.project_id, threshold.measure_id, threshold.branch_id, threshold.testbed_id, threshold.model_id, threshold.created, threshold.modified, model.id, model.uuid, model.threshold_id, model.test, model.min_sample_size, model.max_sample_size, model.window, model.lower_boundary, model.upper_boundary, model.created, model.replaced, boundary.id, boundary.uuid, boundary.threshold_id, boundary.model_id, boundary.metric_id, boundary.baseline, boundary.lower_limit, boundary.upper_limit, alert.id, alert.uuid, alert.boundary_id, alert.boundary_limit, alert.status, alert.modified, metric.id, metric.uuid, metric.report_benchmark_id, metric.measure_id, metric.value, metric.lower_value, metric.upper_value FROM (((metric INNER JOIN ((report_benchmark INNER JOIN ((report INNER JOIN (version INNER JOIN (branch_version INNER JOIN branch ON (branch_version.branch_id = branch.id)) ON (branch_version.version_id = version.id)) ON (report.version_id = version.id)) INNER JOIN testbed ON (report.testbed_id = testbed.id)) ON (report_benchmark.report_id = report.id)) INNER JOIN benchmark ON (report_benchmark.benchmark_id = benchmark.id)) ON (metric.report_benchmark_id = report_benchmark.id)) INNER JOIN measure ON (metric.measure_id = measure.id)) LEFT OUTER JOIN (((boundary INNER JOIN threshold ON (boundary.threshold_id = threshold.id)) INNER JOIN model ON (boundary.model_id = model.id)) LEFT OUTER JOIN alert ON (alert.boundary_id = boundary.id)) ON (boundary.metric_id = metric.id)) WHERE ((((((branch.uuid = 'a7d8366a-4f9b-452e-987e-2ae56e4bf4a3') AND (testbed.uuid = '5b4a6f3e-a27d-4cc3-a2ce-851dc6421e6e')) AND (benchmark.uuid = '88375e7c-f1e0-4cbb-bde1-bdb7773022ae')) AND (measure.uuid = 'b2275bbc-2044-4f8e-aecd-3c739bd861b9')) AND (report.start_time >= 0)) AND (report.end_time <= 1712838648197)) ORDER BY version.number, report.start_time, report_benchmark.iteration;Wenn Sie einen besseren Weg kennen, lassen Sie es mich bitte wissen! Das ist jedoch der Weg, den der Projektbetreuer vorgeschlagen hat, also habe ich das einfach gemacht. Jetzt, da ich eine SQL-Abfrage hatte, war ich endlich bereit… eine Menge Dokumentation zu lesen.
SQLite Abfrageplaner
Die SQLite-Website bietet hervorragende Dokumentation für ihren Abfrageplaner. Sie erklärt genau, wie SQLite Ihre SQL-Abfrage ausführt, und sie lehrt Sie, welche Indizes nützlich sind und auf welche Operationen Sie achten sollten, wie z.B. vollständige Tabellenscans.
Um zu sehen, wie der Abfrageplaner meine Perf-Abfrage ausführen würde,
musste ich ein neues Werkzeug zu meinem Werkzeuggürtel hinzufügen: EXPLAIN QUERY PLAN
Sie können entweder Ihrer SQL-Abfrage EXPLAIN QUERY PLAN voranstellen
oder den Befehl .eqp on vor Ihrer Abfrage ausführen.
So oder so, ich erhielt ein Ergebnis, das so aussieht:
QUERY PLAN|--MATERIALIZE (join-5)| |--SCAN boundary| |--SEARCH threshold USING INTEGER PRIMARY KEY (rowid=?)| |--SEARCH model USING INTEGER PRIMARY KEY (rowid=?)| |--BLOOM FILTER ON alert (boundary_id=?)| `--SEARCH alert USING AUTOMATIC COVERING INDEX (boundary_id=?) LEFT-JOIN|--SEARCH branch USING INDEX sqlite_autoindex_branch_1 (uuid=?)|--SEARCH measure USING INDEX sqlite_autoindex_measure_1 (uuid=?)|--SEARCH benchmark USING INDEX sqlite_autoindex_benchmark_1 (uuid=?)|--SEARCH testbed USING INDEX sqlite_autoindex_testbed_1 (uuid=?)|--SCAN metric|--SEARCH report_benchmark USING INTEGER PRIMARY KEY (rowid=?)|--SEARCH report USING INTEGER PRIMARY KEY (rowid=?)|--SEARCH version USING INTEGER PRIMARY KEY (rowid=?)|--SEARCH branch_version USING COVERING INDEX sqlite_autoindex_branch_version_1 (branch_id=? AND version_id=?)|--BLOOM FILTER ON (join-5) (metric_id=?)|--SEARCH (join-5) USING AUTOMATIC COVERING INDEX (metric_id=?) LEFT-JOIN`--USE TEMP B-TREE FOR ORDER BYOh, Junge! Das ist eine Menge. Aber die drei großen Dinge, die mir sofort ins Auge sprangen, waren:
- SQLite erstellt on-the-fly eine materialisierte Ansicht, die die gesamte
boundaryTabelle scannt - SQLite scannt dann die gesamte
metricTabelle - SQLite erstellt zwei on-the-fly Indizes
Und wie groß sind die metric und boundary Tabellen?
Nun, es stellt sich heraus, dass sie die zwei größten Tabellen sind,
da dort alle Metriken und Grenzwerte gespeichert sind.
Da dies mein erstes Rodeo mit der Leistungsoptimierung von SQLite war, wollte ich vor irgendwelchen Änderungen einen Experten zu Rate ziehen.
SQLite Experte
SQLite hat einen experimentellen “Experten” Modus, der mit dem Befehl .expert aktiviert werden kann.
Es schlägt Indizes für Abfragen vor, also habe ich beschlossen, es auszuprobieren.
Das hat es vorgeschlagen:
CREATE INDEX report_benchmark_idx_fc6f3e5b ON report_benchmark(report_id, benchmark_id);CREATE INDEX report_idx_55aae6d8 ON report(testbed_id, end_time);CREATE INDEX alert_idx_e1882f70 ON alert(boundary_id);
MATERIALIZE (join-5)SCAN boundarySEARCH threshold USING INTEGER PRIMARY KEY (rowid=?)SEARCH model USING INTEGER PRIMARY KEY (rowid=?)SEARCH alert USING INDEX alert_idx_e1882f70 (boundary_id=?) LEFT-JOINSEARCH branch USING INDEX sqlite_autoindex_branch_1 (uuid=?)SEARCH benchmark USING INDEX sqlite_autoindex_benchmark_1 (uuid=?)SEARCH testbed USING INDEX sqlite_autoindex_testbed_1 (uuid=?)SEARCH measure USING INDEX sqlite_autoindex_measure_1 (uuid=?)SEARCH report USING INDEX report_idx_55aae6d8 (testbed_id=? AND end_time<?)SEARCH version USING INTEGER PRIMARY KEY (rowid=?)SEARCH branch_version USING COVERING INDEX sqlite_autoindex_branch_version_1 (branch_id=? AND version_id=?)SEARCH report_benchmark USING INDEX report_benchmark_idx_fc6f3e5b (report_id=? AND benchmark_id=?)SEARCH metric USING INDEX sqlite_autoindex_metric_2 (report_benchmark_id=? AND measure_id=?)BLOOM FILTER ON (join-5) (metric_id=?)SEARCH (join-5) USING AUTOMATIC COVERING INDEX (metric_id=?) LEFT-JOINUSE TEMP B-TREE FOR ORDER BYDas ist definitiv eine Verbesserung!
Es hat das Scannen der metric Tabelle und beide Indizes auf die Fliege beseitigt.
Ehrlich gesagt, hätte ich die ersten zwei Indizes nicht alleine gefunden.
Danke, SQLite Experte!
CREATE INDEX index_report_testbed_end_time ON report(testbed_id, end_time);CREATE INDEX index_report_benchmark ON report_benchmark(report_id, benchmark_id);CREATE INDEX index_alert_boundary ON alert(boundary_id);Jetzt bleibt nur noch, diese verdammte on-the-fly materialisierte Ansicht loszuwerden.
Materialisierte Ansicht
Als ich letztes Jahr die Fähigkeit hinzufügte, Schwellenwertgrenzen zu verfolgen und zu visualisieren,
stand ich vor einer Entscheidung im Datenbankmodell.
Es gibt eine 1-zu-0/1-Beziehung zwischen einem Metrik und seiner entsprechenden Grenze.
Das bedeutet, eine Metrik kann sich auf null oder eine Grenze beziehen, und eine Grenze kann sich immer nur auf eine Metrik beziehen.
Ich hätte also einfach die metric-Tabelle erweitern können, um alle boundary-Daten einzuschließen, wobei jedes boundary-bezogene Feld nullbar wäre.
Oder ich könnte eine separate boundary-Tabelle mit einem UNIQUE Fremdschlüssel zur metric-Tabelle erstellen.
Für mich fühlte sich die letztere Option viel sauberer an, und ich dachte, ich könnte immer später mit eventuellen Leistungsimplikationen umgehen.
Das waren die effektiven Abfragen, um die metric- und boundary-Tabellen zu erstellen:
CREATE TABLE metric ( id INTEGER PRIMARY KEY NOT NULL, uuid TEXT NOT NULL UNIQUE, report_benchmark_id INTEGER NOT NULL, measure_id INTEGER NOT NULL, value DOUBLE NOT NULL, lower_value DOUBLE, upper_value DOUBLE, FOREIGN KEY (report_benchmark_id) REFERENCES report_benchmark (id) ON DELETE CASCADE, FOREIGN KEY (measure_id) REFERENCES measure (id), UNIQUE(report_benchmark_id, measure_id));CREATE TABLE boundary ( id INTEGER PRIMARY KEY NOT NULL, uuid TEXT NOT NULL UNIQUE, threshold_id INTEGER NOT NULL, statistic_id INTEGER NOT NULL, metric_id INTEGER NOT NULL UNIQUE, baseline DOUBLE NOT NULL, lower_limit DOUBLE, upper_limit DOUBLE, FOREIGN KEY (threshold_id) REFERENCES threshold (id), FOREIGN KEY (statistic_id) REFERENCES statistic (id), FOREIGN KEY (metric_id) REFERENCES metric (id) ON DELETE CASCADE);Und es stellt sich heraus, dass “später” gekommen war.
Ich habe versucht, einfach einen Index für boundary(metric_id) hinzuzufügen, aber das half nicht.
Ich glaube, der Grund liegt darin, dass die Perf-Abfrage von der metric-Tabelle ausgeht
und weil diese Beziehung 0/1 ist, oder anders gesagt, nullbar ist, muss sie gescannt werden (O(n))
und kann nicht gesucht werden (O(log(n))).
Das ließ mich mit einer klaren Option zurück.
Ich musste eine materialisierte Ansicht erstellen, die die metric- und boundary-Beziehung abflachte,
um zu verhindern, dass SQLite eine ad-hoc materialisierte Ansicht erstellen muss.
Das ist die Abfrage, die ich verwendet habe, um die neue metric_boundary materialisierte Ansicht zu erstellen:
CREATE VIEW metric_boundary ASSELECT metric.id AS metric_id, metric.uuid AS metric_uuid, metric.report_benchmark_id, metric.measure_id, metric.value, metric.lower_value, metric.upper_value, boundary.id, boundary.uuid AS boundary_uuid, boundary.threshold_id AS threshold_id, boundary.model_id, boundary.baseline, boundary.lower_limit, boundary.upper_limitFROM metric LEFT OUTER JOIN boundary ON (boundary.metric_id = metric.id);Mit dieser Lösung tausche ich Platz gegen Laufzeitleistung. Wie viel Platz? Überraschenderweise nur etwa 4% mehr, obwohl diese Ansicht für die zwei größten Tabellen in der Datenbank ist. Das Beste daran ist, dass es mir erlaubt, in meinem Quellcode sowohl zu haben als auch zu essen.
Eine materialisierte Ansicht mit Diesel zu erstellen war überraschend einfach. Ich musste nur genau dieselben Makros verwenden, die Diesel verwendet, wenn ich mein normales Schema generiere. Mit dem gesagt, habe ich gelernt, Diesel im Laufe dieser Erfahrung viel mehr zu schätzen. Siehe Bonus Bug für alle saftigen Details.
Zusammenfassung
Mit den drei neuen Indizes und einer materialisierten Sicht, die hinzugefügt wurden, zeigt der Abfrageplaner nun Folgendes:
QUERY PLAN|--SEARCH branch USING INDEX sqlite_autoindex_branch_1 (uuid=?)|--SEARCH testbed USING INDEX sqlite_autoindex_testbed_1 (uuid=?)|--SEARCH benchmark USING INDEX sqlite_autoindex_benchmark_1 (uuid=?)|--SEARCH measure USING INDEX sqlite_autoindex_measure_1 (uuid=?)|--SEARCH report USING INDEX index_report_testbed_end_time (testbed_id=? AND end_time<?)|--SEARCH version USING INTEGER PRIMARY KEY (rowid=?)|--SEARCH branch_version USING COVERING INDEX sqlite_autoindex_branch_version_1 (branch_id=? AND version_id=?)|--SEARCH report_benchmark USING INDEX index_report_benchmark (report_id=? AND benchmark_id=?)|--SEARCH metric USING INDEX sqlite_autoindex_metric_2 (report_benchmark_id=? AND measure_id=?)|--SEARCH boundary USING INDEX sqlite_autoindex_boundary_2 (metric_id=?) LEFT-JOIN|--SEARCH threshold USING INTEGER PRIMARY KEY (rowid=?) LEFT-JOIN|--SEARCH model USING INTEGER PRIMARY KEY (rowid=?) LEFT-JOIN|--SEARCH alert USING INDEX index_alert_boundary (boundary_id=?) LEFT-JOIN`--USE TEMP B-TREE FOR ORDER BYSehen Sie sich all diese wunderschönen SEARCH Operationen an, alle mit vorhandenen Indizes! 🥲
Und nachdem ich meine Änderungen in der Produktion eingesetzt habe:
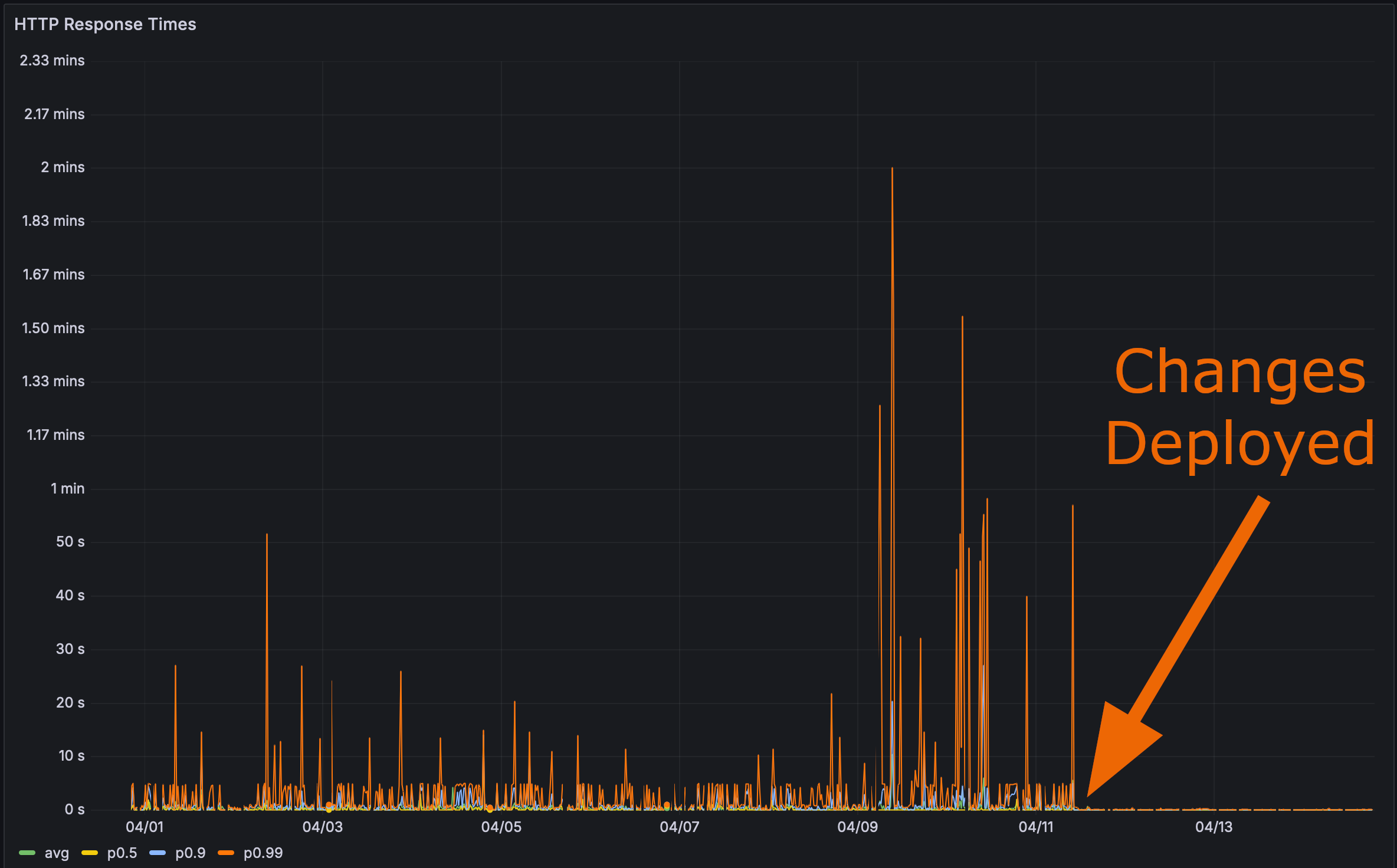
Nun war es Zeit für den finalen Test. Wie schnell lädt nun die Rustls Perf-Seite?
Hier gebe ich Ihnen sogar einen Anker-Tag. Klicken Sie darauf und aktualisieren Sie dann die Seite.
Performance ist wichtig
Bencher: Kontinuierliches Benchmarking

Bencher ist eine Suite von Tools für kontinuierliches Benchmarking. Hatten Sie jemals eine Performance Regression, die Ihre Nutzer beeinflusste? Bencher hätte das verhindern können. Bencher ermöglicht es Ihnen, Leistungsregressionen zu erkennen und zu verhindern, bevor sie gemergt werden.
- Ausführen: Führen Sie Ihre Benchmarks lokal oder in CI mit exakt denselben Bare-Metal-Runnern und Ihren bevorzugten Benchmarking-Tools aus. Das
bencherCLI orchestriert die Ausführung Ihrer Benchmarks auf Bare Metal und speichert die Ergebnisse. - Verfolgen: Verfolgen Sie die Ergebnisse Ihrer Benchmarks im Laufe der Zeit. Überwachen, abfragen und grafisch darstellen der Ergebnisse mit der Bencher Web Konsole auf Basis des Quellzweigs, Testbetts und Maßnahme.
- Auffangen: Fangen Sie Leistungsregressionen lokal oder in CI mit exakt derselben Bare-Metal-Hardware ab. Bencher verwendet modernste, anpassbare Analysen, um Leistungsregressionen zu erkennen, bevor sie gemergt werden.
Aus denselben Gründen, warum Unit Tests laufen, um Feature Regressionen zu verhindern, sollten Benchmarks mit Bencher ausgeführt werden, um Leistungsregressionen zu verhindern. Performance-Bugs sind Fehler!
Beginnen Sie damit, Leistungsregressionen aufzufangen - probieren Sie Bencher Cloud kostenlos aus.
Nachtrag zum Dogfooding
Ich setze Bencher bereits mit Bencher ein, aber alle existierenden Benchmark-Harness-Adapter sind für Micro-Benchmarking-Harnesses. Die meisten HTTP-Harnesses sind tatsächlich Load-Testing-Harnesses und Load Testing unterscheidet sich vom Benchmarking. Weiterhin habe ich nicht vor, Bencher in absehbarer Zeit auf Load Testing auszuweiten. Das ist ein sehr unterschiedlicher Anwendungsfall, der ganz andere Designüberlegungen erfordern würde, wie zum Beispiel eine Zeitreihendatenbank. Selbst wenn ich Load Testing implementiert hätte, hätte ich wirklich gegen einen frischen Pull von Produktionsdaten laufen müssen, damit dies erkannt worden wäre. Die Leistungsunterschiede für diese Änderungen waren mit meiner Testdatenbank vernachlässigbar.
Klicken, um die Benchmark-Ergebnisse der Testdatenbank anzuzeigen
Vorher:
Run Time: real 0.081 user 0.019532 sys 0.005618Run Time: real 0.193 user 0.022192 sys 0.003368Run Time: real 0.070 user 0.021390 sys 0.003369Run Time: real 0.062 user 0.022676 sys 0.002290Run Time: real 0.057 user 0.012053 sys 0.006638Run Time: real 0.052 user 0.018797 sys 0.002016Run Time: real 0.059 user 0.022806 sys 0.002437Run Time: real 0.066 user 0.021869 sys 0.004525Run Time: real 0.060 user 0.021037 sys 0.002864Run Time: real 0.059 user 0.018397 sys 0.003668Nach Indizes und materialisierten Ansichten:
Run Time: real 0.063 user 0.008671 sys 0.004898Run Time: real 0.053 user 0.010671 sys 0.003334Run Time: real 0.053 user 0.010337 sys 0.002884Run Time: real 0.052 user 0.008087 sys 0.002165Run Time: real 0.045 user 0.007265 sys 0.002123Run Time: real 0.038 user 0.008793 sys 0.002240Run Time: real 0.040 user 0.011022 sys 0.002420Run Time: real 0.049 user 0.010004 sys 0.002831Run Time: real 0.059 user 0.010472 sys 0.003661Run Time: real 0.046 user 0.009968 sys 0.002628All dies führt mich zu dem Schluss, dass ich ein Micro-Benchmark erstellen sollte, das gegen den Perf API-Endpunkt läuft und die Ergebnisse mit Bencher dogfoodet. Dies wird eine beträchtliche Testdatenbank erfordern, um sicherzustellen, dass solche Leistungsregressionen in CI erfasst werden. Ich habe ein Tracking-Issue für diese Arbeit erstellt, falls Sie folgen möchten.
Das bringt mich allerdings zum Nachdenken: Was wäre, wenn Sie Snapshot-Testing Ihres SQL-Datenbankabfrageplans durchführen könnten? Das heißt, Sie könnten Ihre aktuellen und kandidierenden SQL-Datenbankabfragepläne vergleichen. SQL-Abfrageplan-Testing wäre so etwas wie Benchmarking auf Basis von Instruktionszählungen für Datenbanken. Der Abfrageplan hilft zu erkennen, dass es möglicherweise ein Problem mit der Laufzeitleistung gibt, ohne dass die Datenbankabfrage tatsächlich einem Benchmark unterzogen werden muss. Ich habe auch ein Tracking-Issue dafür erstellt. Bitte zögern Sie nicht, einen Kommentar mit Gedanken oder vorheriger Kunst, von der Sie wissen, hinzuzufügen!
Bonus Bug
Ursprünglich hatte ich einen Fehler in meinem materialisierten View-Code. So sah die SQL-Abfrage aus:
SELECT branch.id, branch.uuid, branch.project_id, branch.name, branch.slug, branch.start_point_id, branch.created, branch.modified, testbed.id, testbed.uuid, testbed.project_id, testbed.name, testbed.slug, testbed.created, testbed.modified, benchmark.id, benchmark.uuid, benchmark.project_id, benchmark.name, benchmark.slug, benchmark.created, benchmark.modified, measure.id, measure.uuid, measure.project_id, measure.name, measure.slug, measure.units, measure.created, measure.modified, report.uuid, report_benchmark.iteration, report.start_time, report.end_time, version.number, version.hash, threshold.id, threshold.uuid, threshold.project_id, threshold.measure_id, threshold.branch_id, threshold.testbed_id, threshold.model_id, threshold.created, threshold.modified, model.id, model.uuid, model.threshold_id, model.test, model.min_sample_size, model.max_sample_size, model.window, model.lower_boundary, model.upper_boundary, model.created, model.replaced, alert.id, alert.uuid, alert.boundary_id, alert.boundary_limit, alert.status, alert.modified, metric_boundary.metric_id, metric_boundary.metric_uuid, metric_boundary.report_benchmark_id, metric_boundary.measure_id, metric_boundary.value, metric_boundary.lower_value, metric_boundary.upper_value, metric_boundary.boundary_id, metric_boundary.boundary_uuid, metric_boundary.threshold_id, metric_boundary.model_id, metric_boundary.baseline, metric_boundary.lower_limit, metric_boundary.upper_limit FROM (((((metric_boundary INNER JOIN ((report_benchmark INNER JOIN ((report INNER JOIN (version INNER JOIN (branch_version INNER JOIN branch ON (branch_version.branch_id = branch.id)) ON (branch_version.version_id = version.id)) ON (report.version_id = version.id)) INNER JOIN testbed ON (report.testbed_id = testbed.id)) ON (report_benchmark.report_id = report.id)) INNER JOIN benchmark ON (report_benchmark.benchmark_id = benchmark.id)) ON (metric_boundary.report_benchmark_id = report_benchmark.id)) INNER JOIN measure ON (metric_boundary.measure_id = measure.id)) LEFT OUTER JOIN threshold ON (metric_boundary.threshold_id = threshold.id)) LEFT OUTER JOIN model ON (metric_boundary.model_id = model.id)) LEFT OUTER JOIN alert ON (alert.boundary_id = metric_boundary.metric_id)) WHERE ((((((branch.uuid = 'a7d8366a-4f9b-452e-987e-2ae56e4bf4a3') AND (testbed.uuid = '5b4a6f3e-a27d-4cc3-a2ce-851dc6421e6e')) AND (benchmark.uuid = '88375e7c-f1e0-4cbb-bde1-bdb7773022ae')) AND (measure.uuid = 'b2275bbc-2044-4f8e-aecd-3c739bd861b9')) AND (report.start_time >= 0)) AND (report.end_time <= 1712838648197)) ORDER BY version.number, report.start_time, report_benchmark.iteration;Siehst du das Problem? Nein. Ich auch nicht!
Das Problem liegt hier:
LEFT OUTER JOIN alert ON (alert.boundary_id = metric_boundary.metric_id)Es sollte tatsächlich sein:
LEFT OUTER JOIN alert ON (alert.boundary_id = metric_boundary.boundary_id)Ich wollte zu clever sein, und in meinem Diesel-Materialized View Schema hatte ich diesen Join zugelassen:
diesel::joinable!(alert -> metric_boundary (boundary_id));Ich ging davon aus, dass diese Makro irgendwie schlau genug wäre,
alert.boundary_id mit metric_boundary.boundary_id in Verbindung zu bringen.
Aber das war leider nicht der Fall.
Es scheint einfach die erste Spalte von metric_boundary (metric_id) gewählt zu haben, um sie mit alert in Verbindung zu bringen.
Als ich den Fehler entdeckte, war es einfach, ihn zu beheben. Ich musste nur einen expliziten Join in der Perf-Abfrage verwenden:
.left_join(schema::alert::table.on(view::metric_boundary::boundary_id.eq(schema::alert::boundary_id.nullable())))🐰 Das war’s, Leute!