Pourquoi l'optimisation des performances de SQLite a rendu Bencher 1200x plus rapide

Everett Pompeii
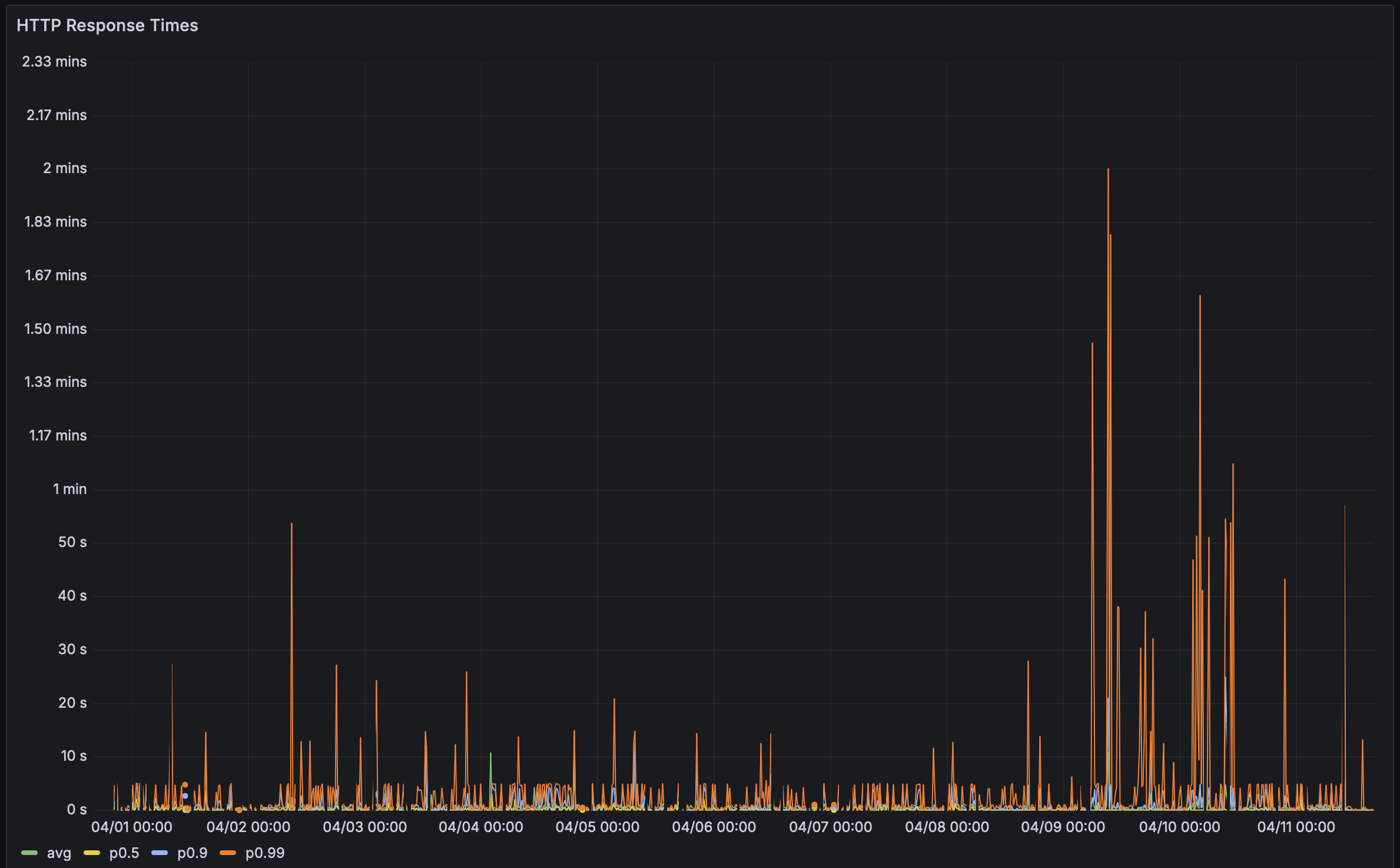
La semaine dernière, j’ai reçu un retour d’un utilisateur disant que leur page de performance Bencher mettait du temps à charger. Alors j’ai décidé de vérifier, et oh, ils étaient vraiment indulgents. Ça a pris un temps foooou à charger ! D’une longueur embarrassante. Surtout pour l’outil phare de Benchmarking Continu.
Par le passé, j’ai utilisé la page de performance Rustls comme test de référence. Ils ont 112 benchmarks et l’une des mises en place de Benchmarking Continu les plus impressionnantes qui existent. Cela prenait environ 5 secondes à charger. Cette fois, ça a pris… ⏳👀 … 38.8 secondes ! Avec un tel délai, je devais creuser. Les bugs de performance sont des bugs, après tout !
Contexte
Dès le début, je savais que l’API de performance Bencher allait être l’un des points de terminaison les plus exigeants en termes de performances. Je pense que la principale raison pour laquelle tant de personnes ont dû réinventer la roue du suivi des benchmarks est que les outils existants ne gèrent pas la haute dimensionalité requise. Par “haute dimensionalité”, je veux dire être capable de suivre la performance dans le temps et à travers de multiples dimensions : Branches, Bancs d’essai, Benchmarks et Mesures. Cette capacité à trancher et à dés en cinq dimensions différentes conduit à un modèle très complexe.
En raison de cette complexité inhérente et de la nature des données, j’ai envisagé d’utiliser une base de données de séries temporelles pour Bencher. Finalement, j’ai opté pour l’utilisation de SQLite à la place. J’ai estimé qu’il valait mieux faire des choses qui ne sont pas évolutives que de passer du temps supplémentaire à apprendre une toute nouvelle architecture de base de données qui pourrait ne pas vraiment aider.
Au fil du temps, les exigences sur l’API de performance Bencher ont également augmenté. Au départ, vous deviez sélectionner manuellement toutes les dimensions que vous vouliez tracer. Cela créait beaucoup de friction pour les utilisateurs afin d’obtenir un tracé utile. Pour résoudre cela, j’ai ajouté une liste des Rapports les plus récents aux pages de Perf, et par défaut, le Rapport le plus récent était sélectionné et tracé. Cela signifie que si le dernier Rapport contenait 112 benchmarks, alors tous les 112 seraient tracés. Le modèle est également devenu encore plus compliqué avec la capacité de suivre et de visualiser les limites de seuil.
Avec cela à l’esprit, j’ai apporté quelques améliorations liées à la performance. Puisque le tracé Perf a besoin du Rapport le plus récent pour commencer à tracer, j’ai refactorisé l’API des Rapports pour obtenir les données de résultat d’un Rapport en un seul appel à la base de données au lieu d’itérer. La fenêtre temporelle pour la requête de Rapport par défaut a été fixée à quatre semaines, au lieu d’être illimitée. J’ai également limité considérablement la portée de toutes les manipulations de base de données, réduisant la contention des verrous. Pour aider à communiquer avec les utilisateurs, j’ai ajouté un indicateur de progression pour le tracé Perf ainsi que pour les onglets de dimensions.
J’ai également eu une tentative échouée l’automne dernier d’utiliser une requête composite pour obtenir tous les résultats de Perf dans une seule requête, au lieu d’utiliser une boucle imbriquée quadruple. Cela m’a conduit à atteindre la limite de récursion du système de types de Rust, à déborder de la pile à répétition, à souffrir de temps de compilation insensés (bien plus longs que 38 secondes), et finalement à une impasse à la limite maximale de SQLite du nombre de termes dans une déclaration de sélection composée.
Avec tout cela à mon actif, je savais que je devais vraiment m’impliquer ici et enfiler mon pantalon d’ingénieur de performance. Je n’avais jamais profilé une base de données SQLite avant, et honnêtement, je n’avais jamais vraiment profilé aucune base de données avant. Attendez une minute, vous pourriez penser. Mon profil LinkedIn dit que j’étais “Administrateur de Base de Données” pendant presque deux ans. Et je n’ai jamais profilé une base de données‽ Oui. C’est une histoire pour une autre fois, je suppose.
De l’ORM à la Requête SQL
La première difficulté à laquelle je me suis heurté était d’extraire la requête SQL de mon code Rust. J’utilise Diesel comme mappeur objet-relationnel (ORM) pour Bencher.
🐰 Le Saviez-vous ? Diesel utilise Bencher pour leur Benchmarking Continu Relatif. Jetez un œil à la page de performances de Diesel !
Diesel crée des requêtes paramétrées.
Il envoie la requête SQL et ses paramètres liés séparément à la base de données.
C’est-à-dire que la substitution est réalisée par la base de données.
Par conséquent, Diesel ne peut pas fournir une requête complète à l’utilisateur.
La meilleure méthode que j’ai trouvée était d’utiliser la fonction diesel::debug_query pour afficher la requête paramétrée :
Query { sql: "SELECT `branch`.`id`, `branch`.`uuid`, `branch`.`project_id`, `branch`.`name`, `branch`.`slug`, `branch`.`start_point_id`, `branch`.`created`, `branch`.`modified`, `testbed`.`id`, `testbed`.`uuid`, `testbed`.`project_id`, `testbed`.`name`, `testbed`.`slug`, `testbed`.`created`, `testbed`.`modified`, `benchmark`.`id`, `benchmark`.`uuid`, `benchmark`.`project_id`, `benchmark`.`name`, `benchmark`.`slug`, `benchmark`.`created`, `benchmark`.`modified`, `measure`.`id`, `measure`.`uuid`, `measure`.`project_id`, `measure`.`name`, `measure`.`slug`, `measure`.`units`, `measure`.`created`, `measure`.`modified`, `report`.`uuid`, `report_benchmark`.`iteration`, `report`.`start_time`, `report`.`end_time`, `version`.`number`, `version`.`hash`, `threshold`.`id`, `threshold`.`uuid`, `threshold`.`project_id`, `threshold`.`measure_id`, `threshold`.`branch_id`, `threshold`.`testbed_id`, `threshold`.`model_id`, `threshold`.`created`, `threshold`.`modified`, `model`.`id`, `model`.`uuid`, `model`.`threshold_id`, `model`.`test`, `model`.`min_sample_size`, `model`.`max_sample_size`, `model`.`window`, `model`.`lower_boundary`, `model`.`upper_boundary`, `model`.`created`, `model`.`replaced`, `boundary`.`id`, `boundary`.`uuid`, `boundary`.`threshold_id`, `boundary`.`model_id`, `boundary`.`metric_id`, `boundary`.`baseline`, `boundary`.`lower_limit`, `boundary`.`upper_limit`, `alert`.`id`, `alert`.`uuid`, `alert`.`boundary_id`, `alert`.`boundary_limit`, `alert`.`status`, `alert`.`modified`, `metric`.`id`, `metric`.`uuid`, `metric`.`report_benchmark_id`, `metric`.`measure_id`, `metric`.`value`, `metric`.`lower_value`, `metric`.`upper_value` FROM (((`metric` INNER JOIN ((`report_benchmark` INNER JOIN ((`report` INNER JOIN (`version` INNER JOIN (`branch_version` INNER JOIN `branch` ON (`branch_version`.`branch_id` = `branch`.`id`)) ON (`branch_version`.`version_id` = `version`.`id`)) ON (`report`.`version_id` = `version`.`id`)) INNER JOIN `testbed` ON (`report`.`testbed_id` = `testbed`.`id`)) ON (`report_benchmark`.`report_id` = `report`.`id`)) INNER JOIN `benchmark` ON (`report_benchmark`.`benchmark_id` = `benchmark`.`id`)) ON (`metric`.`report_benchmark_id` = `report_benchmark`.`id`)) INNER JOIN `measure` ON (`metric`.`measure_id` = `measure`.`id`)) LEFT OUTER JOIN (((`boundary` INNER JOIN `threshold` ON (`boundary`.`threshold_id` = `threshold`.`id`)) INNER JOIN `model` ON (`boundary`.`model_id` = `model`.`id`)) LEFT OUTER JOIN `alert` ON (`alert`.`boundary_id` = `boundary`.`id`)) ON (`boundary`.`metric_id` = `metric`.`id`)) WHERE ((((((`branch`.`uuid` = ?) AND (`testbed`.`uuid` = ?)) AND (`benchmark`.`uuid` = ?)) AND (`measure`.`uuid` = ?)) AND (`report`.`start_time` >= ?)) AND (`report`.`end_time` <= ?)) ORDER BY `version`.`number`, `report`.`start_time`, `report_benchmark`.`iteration`", binds: [BranchUuid(a7d8366a-4f9b-452e-987e-2ae56e4bf4a3), TestbedUuid(5b4a6f3e-a27d-4cc3-a2ce-851dc6421e6e), BenchmarkUuid(88375e7c-f1e0-4cbb-bde1-bdb7773022ae), MeasureUuid(b2275bbc-2044-4f8e-aecd-3c739bd861b9), DateTime(2024-03-12T12:23:38Z), DateTime(2024-04-11T12:23:38Z)] }Et ensuite, nettoyer manuellement et paramétrer la requête en SQL valide :
SELECT branch.id, branch.uuid, branch.project_id, branch.name, branch.slug, branch.start_point_id, branch.created, branch.modified, testbed.id, testbed.uuid, testbed.project_id, testbed.name, testbed.slug, testbed.created, testbed.modified, benchmark.id, benchmark.uuid, benchmark.project_id, benchmark.name, benchmark.slug, benchmark.created, benchmark.modified, measure.id, measure.uuid, measure.project_id, measure.name, measure.slug, measure.units, measure.created, measure.modified, report.uuid, report_benchmark.iteration, report.start_time, report.end_time, version.number, version.hash, threshold.id, threshold.uuid, threshold.project_id, threshold.measure_id, threshold.branch_id, threshold.testbed_id, threshold.model_id, threshold.created, threshold.modified, model.id, model.uuid, model.threshold_id, model.test, model.min_sample_size, model.max_sample_size, model.window, model.lower_boundary, model.upper_boundary, model.created, model.replaced, boundary.id, boundary.uuid, boundary.threshold_id, boundary.model_id, boundary.metric_id, boundary.baseline, boundary.lower_limit, boundary.upper_limit, alert.id, alert.uuid, alert.boundary_id, alert.boundary_limit, alert.status, alert.modified, metric.id, metric.uuid, metric.report_benchmark_id, metric.measure_id, metric.value, metric.lower_value, metric.upper_value FROM (((metric INNER JOIN ((report_benchmark INNER JOIN ((report INNER JOIN (version INNER JOIN (branch_version INNER JOIN branch ON (branch_version.branch_id = branch.id)) ON (branch_version.version_id = version.id)) ON (report.version_id = version.id)) INNER JOIN testbed ON (report.testbed_id = testbed.id)) ON (report_benchmark.report_id = report.id)) INNER JOIN benchmark ON (report_benchmark.benchmark_id = benchmark.id)) ON (metric.report_benchmark_id = report_benchmark.id)) INNER JOIN measure ON (metric.measure_id = measure.id)) LEFT OUTER JOIN (((boundary INNER JOIN threshold ON (boundary.threshold_id = threshold.id)) INNER JOIN model ON (boundary.model_id = model.id)) LEFT OUTER JOIN alert ON (alert.boundary_id = boundary.id)) ON (boundary.metric_id = metric.id)) WHERE ((((((branch.uuid = 'a7d8366a-4f9b-452e-987e-2ae56e4bf4a3') AND (testbed.uuid = '5b4a6f3e-a27d-4cc3-a2ce-851dc6421e6e')) AND (benchmark.uuid = '88375e7c-f1e0-4cbb-bde1-bdb7773022ae')) AND (measure.uuid = 'b2275bbc-2044-4f8e-aecd-3c739bd861b9')) AND (report.start_time >= 0)) AND (report.end_time <= 1712838648197)) ORDER BY version.number, report.start_time, report_benchmark.iteration;Si vous connaissez une meilleure façon, veuillez me le faire savoir ! C’est ainsi que le mainteneur du projet l’a suggéré toutefois, alors j’ai simplement suivi cette voie. Maintenant que j’avais une requête SQL, j’étais enfin prêt à… lire énormément de documentation.
Planificateur de requêtes SQLite
Le site web de SQLite propose une documentation excellente pour son planificateur de requêtes. Elle explique précisément comment SQLite exécute votre requête SQL, et elle vous enseigne quels indices sont utiles et quels opérations surveiller, comme les balayages complets de table.
Afin de voir comment le planificateur de requêtes exécuterait ma requête Perf,
j’ai dû ajouter un nouvel outil à ma boîte à outils : EXPLAIN QUERY PLAN
Vous pouvez soit préfixer votre requête SQL avec EXPLAIN QUERY PLAN
ou exécuter la commande .eqp on avant votre requête.
Dans les deux cas, j’ai obtenu un résultat qui ressemble à ceci :
QUERY PLAN|--MATERIALIZE (join-5)| |--SCAN boundary| |--SEARCH threshold USING INTEGER PRIMARY KEY (rowid=?)| |--SEARCH model USING INTEGER PRIMARY KEY (rowid=?)| |--BLOOM FILTER ON alert (boundary_id=?)| `--SEARCH alert USING AUTOMATIC COVERING INDEX (boundary_id=?) LEFT-JOIN|--SEARCH branch USING INDEX sqlite_autoindex_branch_1 (uuid=?)|--SEARCH measure USING INDEX sqlite_autoindex_measure_1 (uuid=?)|--SEARCH benchmark USING INDEX sqlite_autoindex_benchmark_1 (uuid=?)|--SEARCH testbed USING INDEX sqlite_autoindex_testbed_1 (uuid=?)|--SCAN metric|--SEARCH report_benchmark USING INTEGER PRIMARY KEY (rowid=?)|--SEARCH report USING INTEGER PRIMARY KEY (rowid=?)|--SEARCH version USING INTEGER PRIMARY KEY (rowid=?)|--SEARCH branch_version USING COVERING INDEX sqlite_autoindex_branch_version_1 (branch_id=? AND version_id=?)|--BLOOM FILTER ON (join-5) (metric_id=?)|--SEARCH (join-5) USING AUTOMATIC COVERING INDEX (metric_id=?) LEFT-JOIN`--USE TEMP B-TREE FOR ORDER BYOh, là là ! Il y a beaucoup à digérer ici. Mais les trois grandes choses qui m’ont sauté aux yeux sont :
- SQLite crée une vue matérialisée à la volée qui scanne la table
boundaryen entier - Ensuite, SQLite scanne la table
metricen entier - SQLite crée deux index à la volée
Et à quel point les tables metric et boundary sont-elles volumineuses ?
Eh bien, il se trouve qu’elles sont justement les deux tables les plus volumineuses,
car c’est là que sont stockées toutes les Métriques et les Seuils.
Comme c’était mon premier rodéo de tuning de performance SQLite, je voulais consulter un expert avant de faire des changements.
Expert SQLite
SQLite dispose d’un mode “expert” expérimental qui peut être activé avec la commande .expert.
Il suggère des index pour les requêtes, donc j’ai décidé de l’essayer.
Voici ce qu’il a suggéré :
CREATE INDEX report_benchmark_idx_fc6f3e5b ON report_benchmark(report_id, benchmark_id);CREATE INDEX report_idx_55aae6d8 ON report(testbed_id, end_time);CREATE INDEX alert_idx_e1882f70 ON alert(boundary_id);
MATERIALIZE (join-5)SCAN boundarySEARCH threshold USING INTEGER PRIMARY KEY (rowid=?)SEARCH model USING INTEGER PRIMARY KEY (rowid=?)SEARCH alert USING INDEX alert_idx_e1882f70 (boundary_id=?) LEFT-JOINSEARCH branch USING INDEX sqlite_autoindex_branch_1 (uuid=?)SEARCH benchmark USING INDEX sqlite_autoindex_benchmark_1 (uuid=?)SEARCH testbed USING INDEX sqlite_autoindex_testbed_1 (uuid=?)SEARCH measure USING INDEX sqlite_autoindex_measure_1 (uuid=?)SEARCH report USING INDEX report_idx_55aae6d8 (testbed_id=? AND end_time<?)SEARCH version USING INTEGER PRIMARY KEY (rowid=?)SEARCH branch_version USING COVERING INDEX sqlite_autoindex_branch_version_1 (branch_id=? AND version_id=?)SEARCH report_benchmark USING INDEX report_benchmark_idx_fc6f3e5b (report_id=? AND benchmark_id=?)SEARCH metric USING INDEX sqlite_autoindex_metric_2 (report_benchmark_id=? AND measure_id=?)BLOOM FILTER ON (join-5) (metric_id=?)SEARCH (join-5) USING AUTOMATIC COVERING INDEX (metric_id=?) LEFT-JOINUSE TEMP B-TREE FOR ORDER BYC’est définitivement une amélioration !
Il a supprimé le scan sur la table metric et les deux index créés à la volée.
Honnêtement, je n’aurais pas trouvé les deux premiers index par moi-même.
Merci, SQLite Expert !
CREATE INDEX index_report_testbed_end_time ON report(testbed_id, end_time);CREATE INDEX index_report_benchmark ON report_benchmark(report_id, benchmark_id);CREATE INDEX index_alert_boundary ON alert(boundary_id);Maintenant, la seule chose qu’il reste à éliminer, c’est cette fichue vue matérialisée créée à la volée.
Vue Matérialisée
Lorsque j’ai ajouté la capacité de suivre et de visualiser les Limites de Seuil l’année dernière,
j’avais une décision à prendre concernant le modèle de base de données.
Il existe une relation de 1 à 0/1 entre une Métrique et sa Limite correspondante.
C’est-à-dire qu’une Métrique peut être liée à zéro ou une Limite, et une Limite ne peut être liée qu’à une seule Métrique.
J’aurais donc pu simplement étendre la table métrique pour inclure toutes les données de limite avec chaque champ lié à limite étant nullable.
Ou je pourrais créer une table limite séparée avec une clé étrangère UNIQUE pour la table métrique.
Pour moi, la dernière option semblait beaucoup plus propre, et je me disais que je pourrais toujours gérer les implications de performance plus tard.
Voici les requêtes effectives utilisées pour créer les tables métrique et limite :
CREATE TABLE metric ( id INTEGER PRIMARY KEY NOT NULL, uuid TEXT NOT NULL UNIQUE, report_benchmark_id INTEGER NOT NULL, measure_id INTEGER NOT NULL, value DOUBLE NOT NULL, lower_value DOUBLE, upper_value DOUBLE, FOREIGN KEY (report_benchmark_id) REFERENCES report_benchmark (id) ON DELETE CASCADE, FOREIGN KEY (measure_id) REFERENCES measure (id), UNIQUE(report_benchmark_id, measure_id));CREATE TABLE boundary ( id INTEGER PRIMARY KEY NOT NULL, uuid TEXT NOT NULL UNIQUE, threshold_id INTEGER NOT NULL, statistic_id INTEGER NOT NULL, metric_id INTEGER NOT NULL UNIQUE, baseline DOUBLE NOT NULL, lower_limit DOUBLE, upper_limit DOUBLE, FOREIGN KEY (threshold_id) REFERENCES threshold (id), FOREIGN KEY (statistic_id) REFERENCES statistic (id), FOREIGN KEY (metric_id) REFERENCES metric (id) ON DELETE CASCADE);Et il s’avère que “plus tard” est arrivé.
J’ai tenté d’ajouter simplement un index pour limite(metric_id) mais cela n’a pas aidé.
Je crois que la raison a à voir avec le fait que la requête Perf provient de la table métrique
et parce que cette relation est de 0/1 ou pour le dire autrement, nullable elle doit être balayée (O(n))
et ne peut pas être cherchée (O(log(n))).
Cela m’a laissé une option claire.
Je devais créer une vue matérialisée qui aplatit la relation entre métrique et limite
pour empêcher SQLite de devoir créer une vue matérialisée à la volée.
Voici la requête que j’ai utilisée pour créer la nouvelle vue matérialisée metric_boundary :
CREATE VIEW metric_boundary ASSELECT metric.id AS metric_id, metric.uuid AS metric_uuid, metric.report_benchmark_id, metric.measure_id, metric.value, metric.lower_value, metric.upper_value, boundary.id, boundary.uuid AS boundary_uuid, boundary.threshold_id AS threshold_id, boundary.model_id, boundary.baseline, boundary.lower_limit, boundary.upper_limitFROM metric LEFT OUTER JOIN boundary ON (boundary.metric_id = metric.id);Avec cette solution, je troque de l’espace contre des performances d’exécution. Combien d’espace ? Étonnamment, seulement environ une augmentation de 4 %, même si cette vue concerne les deux plus grandes tables de la base de données. Le mieux dans tout ça, c’est que ça me permet d’avoir le beurre et l’argent du beurre dans mon code source.
Créer une vue matérialisée avec Diesel a été étonnamment facile. Il suffisait d’utiliser exactement les mêmes macros que Diesel utilise lors de la génération de mon schéma normal. Cela dit, j’ai appris à apprécier beaucoup plus Diesel tout au long de cette expérience. Voir Bug Bonus pour tous les détails croustillants.
Conclusion
Avec l’ajout des trois nouveaux index et d’une vue matérialisée, voici ce que montre désormais le Planificateur de requêtes :
QUERY PLAN|--SEARCH branch USING INDEX sqlite_autoindex_branch_1 (uuid=?)|--SEARCH testbed USING INDEX sqlite_autoindex_testbed_1 (uuid=?)|--SEARCH benchmark USING INDEX sqlite_autoindex_benchmark_1 (uuid=?)|--SEARCH measure USING INDEX sqlite_autoindex_measure_1 (uuid=?)|--SEARCH report USING INDEX index_report_testbed_end_time (testbed_id=? AND end_time<?)|--SEARCH version USING INTEGER PRIMARY KEY (rowid=?)|--SEARCH branch_version USING COVERING INDEX sqlite_autoindex_branch_version_1 (branch_id=? AND version_id=?)|--SEARCH report_benchmark USING INDEX index_report_benchmark (report_id=? AND benchmark_id=?)|--SEARCH metric USING INDEX sqlite_autoindex_metric_2 (report_benchmark_id=? AND measure_id=?)|--SEARCH boundary USING INDEX sqlite_autoindex_boundary_2 (metric_id=?) LEFT-JOIN|--SEARCH threshold USING INTEGER PRIMARY KEY (rowid=?) LEFT-JOIN|--SEARCH model USING INTEGER PRIMARY KEY (rowid=?) LEFT-JOIN|--SEARCH alert USING INDEX index_alert_boundary (boundary_id=?) LEFT-JOIN`--USE TEMP B-TREE FOR ORDER BYRegardez toutes ces magnifiques recherches SEARCH réalisées avec des index existants ! 🥲
Et après avoir déployé mes modifications en production :
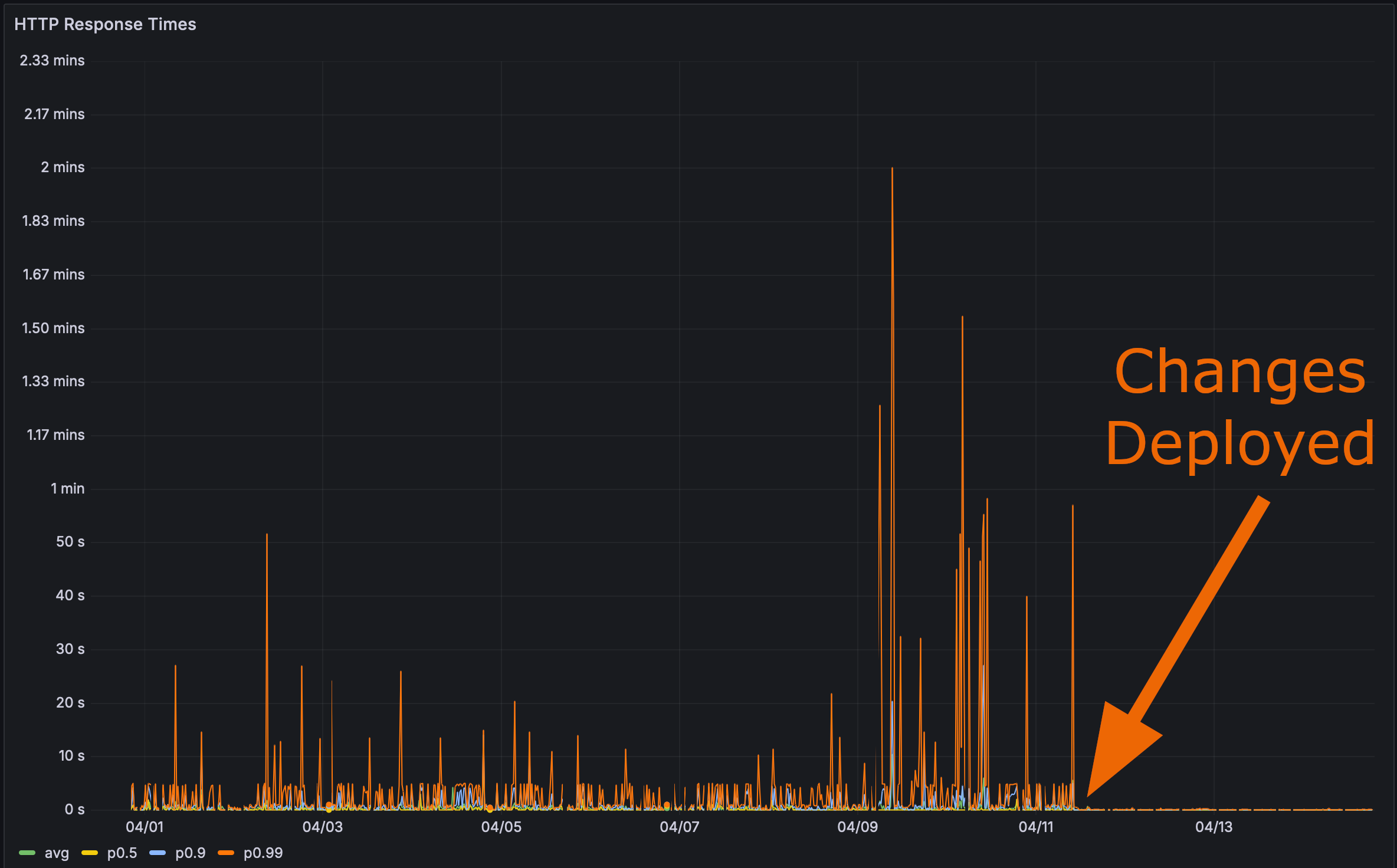
Il était alors temps pour le test final. À quelle vitesse la page de performance Rustls se charge-t-elle ?
Voici même un lien ancre. Cliquez dessus puis rafraîchissez la page.
La performance compte
Bencher: Benchmarking Continu

Bencher est une suite d’outils de benchmarking continu. Avez-vous déjà eu une régression de performance qui a impacté vos utilisateurs ? Bencher aurait pu empêcher cela de se produire. Bencher vous permet de détecter et de prévenir les régressions de performance avant qu’elles n’arrivent en production.
- Exécuter: Exécutez vos benchmarks localement ou en CI en utilisant vos outils de benchmarking préférés. La CLI
bencherenveloppe simplement votre harnais de benchmarking existant et stocke ses résultats. - Suivre: Suivez les résultats de vos benchmarks au fil du temps. Surveillez, interrogez et graphiquez les résultats à l’aide de la console web Bencher en fonction de la branche source, du banc d’essai et de la mesure.
- Détecter: Détectez les régressions de performances en CI. Bencher utilise des analyses de pointe et personnalisables pour détecter les régressions de performances avant qu’elles n’arrivent en production.
Pour les mêmes raisons que les tests unitaires sont exécutés en CI pour prévenir les régressions de fonctionnalités, les benchmarks devraient être exécutés en CI avec Bencher pour prévenir les régressions de performance. Les bugs de performance sont des bugs !
Commencez à détecter les régressions de performances en CI — essayez Bencher Cloud gratuitement.
Addendum sur l’Auto-utilisation
Je suis déjà en train d’auto-utiliser Bencher avec Bencher, mais tous les adaptateurs de harnais de benchmark existants sont pour des harnais de micro-benchmarking. La plupart des harnais HTTP sont réellement des harnais de test de charge, et le test de charge est différent du benchmarking. De plus, je ne cherche pas à étendre Bencher au test de charge de si tôt. C’est un cas d’utilisation très différent qui nécessiterait des considérations de conception très différentes, comme cette base de données en série temporelle par exemple. Même si j’avais mis en place des tests de charge, j’aurais vraiment besoin de travailler contre une nouvelle extraction de données de production pour que cela soit détecté. Les différences de performance pour ces changements étaient négligeables avec ma base de données de test.
Cliquez pour voir les résultats des benchmarks de la base de données de test
Avant :
Run Time: real 0.081 user 0.019532 sys 0.005618Run Time: real 0.193 user 0.022192 sys 0.003368Run Time: real 0.070 user 0.021390 sys 0.003369Run Time: real 0.062 user 0.022676 sys 0.002290Run Time: real 0.057 user 0.012053 sys 0.006638Run Time: real 0.052 user 0.018797 sys 0.002016Run Time: real 0.059 user 0.022806 sys 0.002437Run Time: real 0.066 user 0.021869 sys 0.004525Run Time: real 0.060 user 0.021037 sys 0.002864Run Time: real 0.059 user 0.018397 sys 0.003668Après les index et la vue matérialisée :
Run Time: real 0.063 user 0.008671 sys 0.004898Run Time: real 0.053 user 0.010671 sys 0.003334Run Time: real 0.053 user 0.010337 sys 0.002884Run Time: real 0.052 user 0.008087 sys 0.002165Run Time: real 0.045 user 0.007265 sys 0.002123Run Time: real 0.038 user 0.008793 sys 0.002240Run Time: real 0.040 user 0.011022 sys 0.002420Run Time: real 0.049 user 0.010004 sys 0.002831Run Time: real 0.059 user 0.010472 sys 0.003661Run Time: real 0.046 user 0.009968 sys 0.002628Tout cela me conduit à croire que je devrais créer un micro-benchmark qui s’exécute contre le point de terminaison de l’API Perf et auto-utiliser les résultats avec Bencher. Cela nécessitera une base de données de test de taille considérable pour s’assurer que ce type de régressions de performance soit détecté dans l’IC. J’ai créé un problème de suivi pour ce travail, si vous souhaitez suivre l’évolution.
Tout cela m’a toutefois fait réfléchir : Et si vous pouviez faire des tests de captures instantanées de votre plan de requête de base de données SQL ? C’est-à-dire, vous pourriez comparer vos plans de requête de base de données actuels par rapport à ceux candidats. Les tests de plan de requête SQL seraient une sorte de benchmarking basé sur le nombre d’instructions pour les bases de données. Le plan de requête aide à indiquer qu’il peut y avoir un problème avec la performance d’exécution, sans avoir à réellement benchmark la requête de la base de données. J’ai créé un problème de suivi pour cela également. N’hésitez pas à ajouter un commentaire avec vos pensées ou toute œuvre antérieure que vous connaissez !
Bonus Bug
J’avais initialement un bug dans mon code de vue matérialisée. Voici à quoi ressemblait la requête SQL :
SELECT branch.id, branch.uuid, branch.project_id, branch.name, branch.slug, branch.start_point_id, branch.created, branch.modified, testbed.id, testbed.uuid, testbed.project_id, testbed.name, testbed.slug, testbed.created, testbed.modified, benchmark.id, benchmark.uuid, benchmark.project_id, benchmark.name, benchmark.slug, benchmark.created, benchmark.modified, measure.id, measure.uuid, measure.project_id, measure.name, measure.slug, measure.units, measure.created, measure.modified, report.uuid, report_benchmark.iteration, report.start_time, report.end_time, version.number, version.hash, threshold.id, threshold.uuid, threshold.project_id, threshold.measure_id, threshold.branch_id, threshold.testbed_id, threshold.model_id, threshold.created, threshold.modified, model.id, model.uuid, model.threshold_id, model.test, model.min_sample_size, model.max_sample_size, model.window, model.lower_boundary, model.upper_boundary, model.created, model.replaced, alert.id, alert.uuid, alert.boundary_id, alert.boundary_limit, alert.status, alert.modified, metric_boundary.metric_id, metric_boundary.metric_uuid, metric_boundary.report_benchmark_id, metric_boundary.measure_id, metric_boundary.value, metric_boundary.lower_value, metric_boundary.upper_value, metric_boundary.boundary_id, metric_boundary.boundary_uuid, metric_boundary.threshold_id, metric_boundary.model_id, metric_boundary.baseline, metric_boundary.lower_limit, metric_boundary.upper_limit FROM (((((metric_boundary INNER JOIN ((report_benchmark INNER JOIN ((report INNER JOIN (version INNER JOIN (branch_version INNER JOIN branch ON (branch_version.branch_id = branch.id)) ON (branch_version.version_id = version.id)) ON (report.version_id = version.id)) INNER JOIN testbed ON (report.testbed_id = testbed.id)) ON (report_benchmark.report_id = report.id)) INNER JOIN benchmark ON (report_benchmark.benchmark_id = benchmark.id)) ON (metric_boundary.report_benchmark_id = report_benchmark.id)) INNER JOIN measure ON (metric_boundary.measure_id = measure.id)) LEFT OUTER JOIN threshold ON (metric_boundary.threshold_id = threshold.id)) LEFT OUTER JOIN model ON (metric_boundary.model_id = model.id)) LEFT OUTER JOIN alert ON (alert.boundary_id = metric_boundary.metric_id)) WHERE ((((((branch.uuid = 'a7d8366a-4f9b-452e-987e-2ae56e4bf4a3') AND (testbed.uuid = '5b4a6f3e-a27d-4cc3-a2ce-851dc6421e6e')) AND (benchmark.uuid = '88375e7c-f1e0-4cbb-bde1-bdb7773022ae')) AND (measure.uuid = 'b2275bbc-2044-4f8e-aecd-3c739bd861b9')) AND (report.start_time >= 0)) AND (report.end_time <= 1712838648197)) ORDER BY version.number, report.start_time, report_benchmark.iteration;Avez-vous vu le problème ? Non. Moi non plus !
Le problème est ici :
LEFT OUTER JOIN alert ON (alert.boundary_id = metric_boundary.metric_id)Cela aurait dû être :
LEFT OUTER JOIN alert ON (alert.boundary_id = metric_boundary.boundary_id)J’essayais d’être trop astucieux, et dans mon schéma de vue matérialisée Diesel, j’avais permis cette jointure :
diesel::joinable!(alert -> metric_boundary (boundary_id));Je supposais que cette macro était d’une certaine manière assez intelligente
pour relier alert.boundary_id à metric_boundary.boundary_id.
Mais hélas, ce n’était pas le cas.
Il semble qu’elle ait juste choisi la première colonne de metric_boundary (metric_id) pour se rapporter à alert.
Une fois que j’ai découvert le bug, il était facile à corriger. Il suffisait simplement d’utiliser une jointure explicite dans la requête Perf :
.left_join(schema::alert::table.on(view::metric_boundary::boundary_id.eq(schema::alert::boundary_id.nullable())))🐰 C’est tout, folks !