SQLite 성능 튜닝이 Bencher를 1200배 더 빠르게 만든 이유

Everett Pompeii
지난주에 한 사용자로부터 피드백을 받았습니다. 그들의 Bencher Perf 페이지가 로딩하는 데 시간이 걸린다고 했습니다. 그래서 저도 확인해 보기로 했는데, 정말, 그들이 상냥하게 말한 것이었네요. 로딩하는 데 너무나 오래 걸렸어요! 부끄럽게도 오래 걸렸습니다. 특히 지속적 벤치마킹 도구의 선두주자에게는 더욱이요.
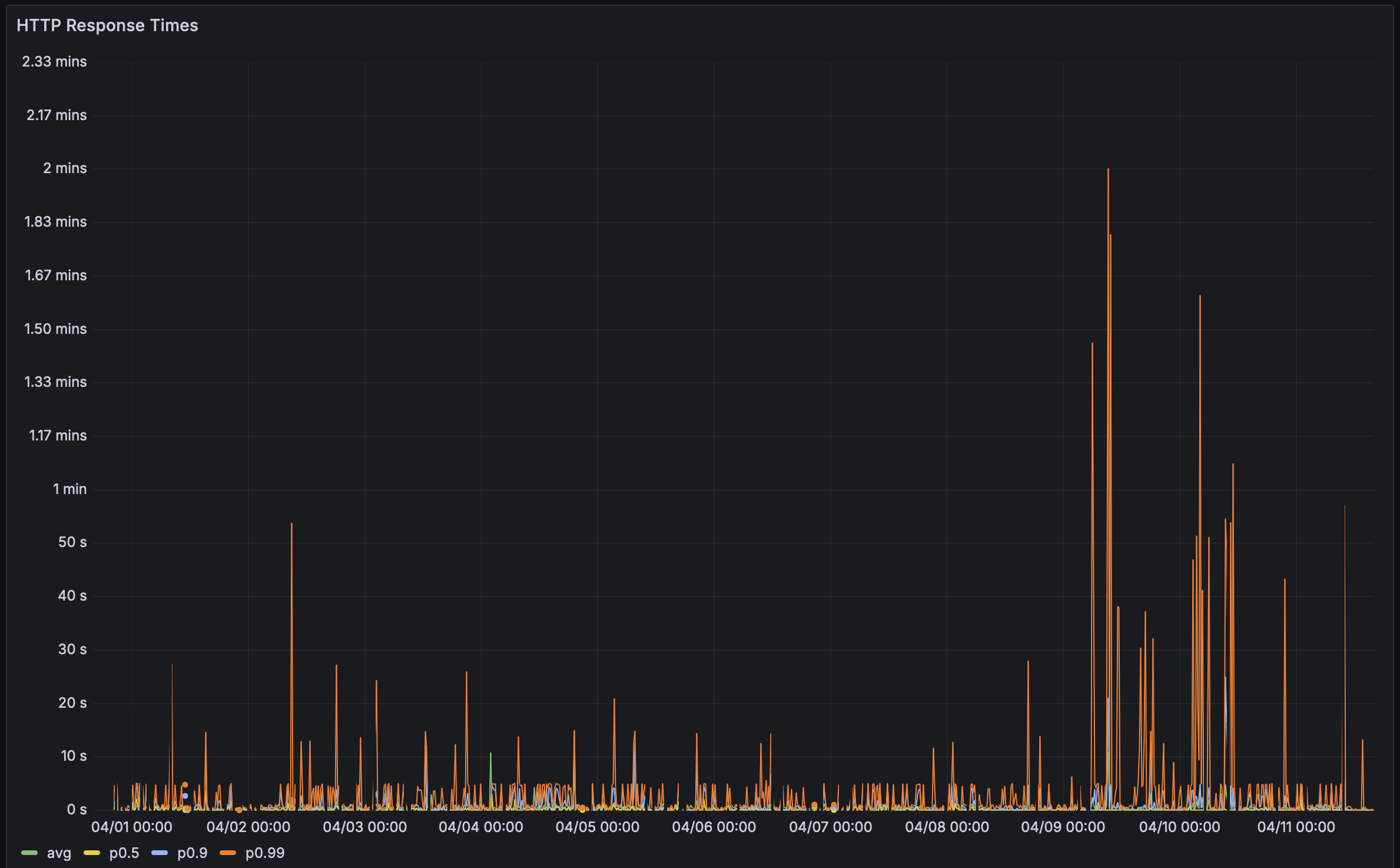
과거에, 저는 Rustls Perf 페이지를 리트머스 시험지로 사용해 왔습니다. 그들은 112개의 벤치마크를 가지고 있고 가장 인상적인 지속적 벤치마킹 설정 중 하나를 가지고 있습니다. 이전에는 로딩하는 데 대략 5초가 걸렸습니다. 이번에는… ⏳👀 … 38.8초가 걸렸네요! 이런 종류의 지연 시간으로는, 저는 파고들 수밖에 없었습니다. 성능 버그도 결국 버그니까요!
배경
처음부터, Bencher Perf API 가 성능 측면에서 가장 요구가 많은 엔드포인트 중 하나가 될 것이라는 것을 알고 있었습니다. 많은 사람들이 벤치마크 추적 도구를 다시 만들어야 했던 주된 이유는 기존의 현장 도구들이 필요한 고차원성을 처리하지 못하기 때문입니다. “고차원성”이란 시간 경과에 따른 성능을 추적하고 브랜치, 테스트베드, 벤치마크, 측정치 등 여러 차원을 통해 추적할 수 있는 능력을 의미합니다. 이 다섯 가지 다른 차원을 통한 분석 능력은 매우 복잡한 모델로 이어집니다.
이러한 내재적 복잡성과 데이터의 성격 때문에, Bencher에 시계열 데이터베이스를 사용하는 것을 고려했습니다. 결국에는, SQLite를 사용하기로 결정했습니다. 스케일링하지 않는 일을 처리하는 것이 스케일링하지 않는 일 하기는 실제로 도움이 될지 그렇지 않을지 알 수 없는 전혀 새로운 데이터베이스 아키텍처를 배우는 데 추가 시간을 소비하는 것보다 낫다고 판단했습니다.
시간이 지남에 따라 Bencher Perf API에 대한 요구 사항도 증가했습니다. 원래는 사용자가 수동으로 그래프에 표시하고자 하는 모든 차원을 선택해야 했습니다. 이것은 사용자가 유용한 그래프에 도달하는 데 많은 마찰을 일으켰습니다. 이를 해결하기 위해, Perf 페이지에 가장 최근 보고서 목록을 추가했습니다. 기본적으로 가장 최근 보고서가 선택되어 그래프에 표시되었습니다. 이는 가장 최근 보고서에 112개의 벤치마크가 있을 경우 112개 모두가 그래프에 표시됨을 의미합니다. 모델은 또한 임계값 경계를 추적하고 시각화하는 기능으로 더욱 복잡해졌습니다.
이러한 점을 염두에 두고, 성능 관련 개선을 몇 가지 실행했습니다. Perf 그래프가 가장 최근 보고서로부터 플로팅을 시작해야 하므로, Reports API를 리팩토링하여 데이터베이스를 순회하는 대신 단일 호출로 보고서의 결과 데이터를 얻었습니다. 기본 보고서 쿼리의 시간 창을 무제한이 아닌 네 주로 설정했습니다. 또한 모든 데이터베이스 핸들의 범위를 대폭 제한하여 잠금 경합을 줄였습니다. 사용자와 소통을 돕기 위해 Perf 플롯과 차원 탭 모두에 상태 바 스피너를 추가했습니다.
작년 가을에 단일 쿼리로 모든 Perf 결과를 가져오기 위해 복합 쿼리를 사용하려는 시도는 실패했습니다. 이는 사중 중첩된 for 루프를 사용하는 대신이었습니다. 이로 인해 Rust 타입 시스템 재귀 제한에 도달하게 되었고, 스택이 반복적으로 오버플로우되며, 정신이 나갈 것 같은(38초 이상) 컴파일 시간을 겪은 끝에, SQLite 복합 선택문의 최대 항목 수 제한에서 궁극적으로 실패로 돌아왔습니다.
이 모든 경험을 바탕으로, 여기서 정말로 성능 엔지니어 체제를 갖추고 주력해야 한다는 것을 알았습니다. SQLite 데이터베이스를 프로파일링한 적이 없었고, 솔직히 말해서 어떤 데이터베이스도 실제로 프로파일링한 적이 없었습니다. 잠깐, 당신이 생각할지도 모릅니다. 내 LinkedIn 프로필에는 거의 2년 동안 “데이터베이스 관리자”였다고 되어 있습니다. 그리고 저는 한 번도 데이터베이스를 프로파일링하지 않았습니까? 네. 아마도 그 이야기는 다음에 할 기회가 있겠죠.
ORM에서 SQL 쿼리로
제가 처음 마주친 문제는 Rust 코드에서 SQL 쿼리를 추출하는 것이었습니다. 저는 Bencher의 객체 관계 매퍼(ORM)로 Diesel을 사용합니다.
🐰 재미있는 사실: Diesel은 상대적 연속 벤치마킹을 위해 Bencher를 사용합니다. Diesel 성능 페이지를 확인해보세요!
Diesel은 매개변수화된 쿼리를 생성합니다.
즉, SQL 쿼리와 해당 바인드 매개변수를 데이터베이스에 별도로 전송합니다.
즉, 대체 작업은 데이터베이스에서 수행됩니다.
따라서, Diesel은 사용자에게 완전한 쿼리를 제공할 수 없습니다.
제가 찾은 가장 좋은 방법은 the diesel::debug_query 함수를 사용하여 매개변수화된 쿼리를 출력하는 것이었습니다:
Query { sql: "SELECT `branch`.`id`, `branch`.`uuid`, `branch`.`project_id`, `branch`.`name`, `branch`.`slug`, `branch`.`start_point_id`, `branch`.`created`, `branch`.`modified`, `testbed`.`id`, `testbed`.`uuid`, `testbed`.`project_id`, `testbed`.`name`, `testbed`.`slug`, `testbed`.`created`, `testbed`.`modified`, `benchmark`.`id`, `benchmark`.`uuid`, `benchmark`.`project_id`, `benchmark`.`name`, `benchmark`.`slug`, `benchmark`.`created`, `benchmark`.`modified`, `measure`.`id`, `measure`.`uuid`, `measure`.`project_id`, `measure`.`name`, `measure`.`slug`, `measure`.`units`, `measure`.`created`, `measure`.`modified`, `report`.`uuid`, `report_benchmark`.`iteration`, `report`.`start_time`, `report`.`end_time`, `version`.`number`, `version`.`hash`, `threshold`.`id`, `threshold`.`uuid`, `threshold`.`project_id`, `threshold`.`measure_id`, `threshold`.`branch_id`, `threshold`.`testbed_id`, `threshold`.`model_id`, `threshold`.`created`, `threshold`.`modified`, `model`.`id`, `model`.`uuid`, `model`.`threshold_id`, `model`.`test`, `model`.`min_sample_size`, `model`.`max_sample_size`, `model`.`window`, `model`.`lower_boundary`, `model`.`upper_boundary`, `model`.`created`, `model`.`replaced`, `boundary`.`id`, `boundary`.`uuid`, `boundary`.`threshold_id`, `boundary`.`model_id`, `boundary`.`metric_id`, `boundary`.`baseline`, `boundary`.`lower_limit`, `boundary`.`upper_limit`, `alert`.`id`, `alert`.`uuid`, `alert`.`boundary_id`, `alert`.`boundary_limit`, `alert`.`status`, `alert`.`modified`, `metric`.`id`, `metric`.`uuid`, `metric`.`report_benchmark_id`, `metric`.`measure_id`, `metric`.`value`, `metric`.`lower_value`, `metric`.`upper_value` FROM (((`metric` INNER JOIN ((`report_benchmark` INNER JOIN ((`report` INNER JOIN (`version` INNER JOIN (`branch_version` INNER JOIN `branch` ON (`branch_version`.`branch_id` = `branch`.`id`)) ON (`branch_version`.`version_id` = `version`.`id`)) ON (`report`.`version_id` = `version`.`id`)) INNER JOIN `testbed` ON (`report`.`testbed_id` = `testbed`.`id`)) ON (`report_benchmark`.`report_id` = `report`.`id`)) INNER JOIN `benchmark` ON (`report_benchmark`.`benchmark_id` = `benchmark`.`id`)) ON (`metric`.`report_benchmark_id` = `report_benchmark`.`id`)) INNER JOIN `measure` ON (`metric`.`measure_id` = `measure`.`id`)) LEFT OUTER JOIN (((`boundary` INNER JOIN `threshold` ON (`boundary`.`threshold_id` = `threshold`.`id`)) INNER JOIN `model` ON (`boundary`.`model_id` = `model`.`id`)) LEFT OUTER JOIN `alert` ON (`alert`.`boundary_id` = `boundary`.`id`)) ON (`boundary`.`metric_id` = `metric`.`id`)) WHERE ((((((`branch`.`uuid` = ?) AND (`testbed`.`uuid` = ?)) AND (`benchmark`.`uuid` = ?)) AND (`measure`.`uuid` = ?)) AND (`report`.`start_time` >= ?)) AND (`report`.`end_time` <= ?)) ORDER BY `version`.`number`, `report`.`start_time`, `report_benchmark`.`iteration`", binds: [BranchUuid(a7d8366a-4f9b-452e-987e-2ae56e4bf4a3), TestbedUuid(5b4a6f3e-a27d-4cc3-a2ce-851dc6421e6e), BenchmarkUuid(88375e7c-f1e0-4cbb-bde1-bdb7773022ae), MeasureUuid(b2275bbc-2044-4f8e-aecd-3c739bd861b9), DateTime(2024-03-12T12:23:38Z), DateTime(2024-04-11T12:23:38Z)] }그리고 유효한 SQL로 쿼리를 손으로 정리하고 매개변수화했습니다:
SELECT branch.id, branch.uuid, branch.project_id, branch.name, branch.slug, branch.start_point_id, branch.created, branch.modified, testbed.id, testbed.uuid, testbed.project_id, testbed.name, testbed.slug, testbed.created, testbed.modified, benchmark.id, benchmark.uuid, benchmark.project_id, benchmark.name, benchmark.slug, benchmark.created, benchmark.modified, measure.id, measure.uuid, measure.project_id, measure.name, measure.slug, measure.units, measure.created, measure.modified, report.uuid, report_benchmark.iteration, report.start_time, report.end_time, version.number, version.hash, threshold.id, threshold.uuid, threshold.project_id, threshold.measure_id, threshold.branch_id, threshold.testbed_id, threshold.model_id, threshold.created, threshold.modified, model.id, model.uuid, model.threshold_id, model.test, model.min_sample_size, model.max_sample_size, model.window, model.lower_boundary, model.upper_boundary, model.created, model.replaced, boundary.id, boundary.uuid, boundary.threshold_id, boundary.model_id, boundary.metric_id, boundary.baseline, boundary.lower_limit, boundary.upper_limit, alert.id, alert.uuid, alert.boundary_id, alert.boundary_limit, alert.status, alert.modified, metric.id, metric.uuid, metric.report_benchmark_id, metric.measure_id, metric.value, metric.lower_value, metric.upper_value FROM (((metric INNER JOIN ((report_benchmark INNER JOIN ((report INNER JOIN (version INNER JOIN (branch_version INNER JOIN branch ON (branch_version.branch_id = branch.id)) ON (branch_version.version_id = version.id)) ON (report.version_id = version.id)) INNER JOIN testbed ON (report.testbed_id = testbed.id)) ON (report_benchmark.report_id = report.id)) INNER JOIN benchmark ON (report_benchmark.benchmark_id = benchmark.id)) ON (metric.report_benchmark_id = report_benchmark.id)) INNER JOIN measure ON (metric.measure_id = measure.id)) LEFT OUTER JOIN (((boundary INNER JOIN threshold ON (boundary.threshold_id = threshold.id)) INNER JOIN model ON (boundary.model_id = model.id)) LEFT OUTER JOIN alert ON (alert.boundary_id = boundary.id)) ON (boundary.metric_id = metric.id)) WHERE ((((((branch.uuid = 'a7d8366a-4f9b-452e-987e-2ae56e4bf4a3') AND (testbed.uuid = '5b4a6f3e-a27d-4cc3-a2ce-851dc6421e6e')) AND (benchmark.uuid = '88375e7c-f1e0-4cbb-bde1-bdb7773022ae')) AND (measure.uuid = 'b2275bbc-2044-4f8e-aecd-3c739bd861b9')) AND (report.start_time >= 0)) AND (report.end_time <= 1712838648197)) ORDER BY version.number, report.start_time, report_benchmark.iteration;더 나은 방법을 알고 계시다면 알려주세요! 이 방법은 프로젝트 관리자가 제안한 방법이긴 하지만, 그래서 저는 그대로 따랐습니다. 이제 SQL 쿼리를 얻었으니, 마침내… 많은 문서를 읽을 준비가 되었습니다.
SQLite 쿼리 플래너
SQLite 웹사이트에는 쿼리 플래너에 대한 훌륭한 문서가 있습니다. 이 문서는 SQLite가 SQL 쿼리를 어떻게 실행하는지 정확히 설명하고, 어떤 인덱스가 유용한지, 전체 테이블 스캔 같은 주의해야 할 작업이 무엇인지 알려줍니다.
내 Perf 쿼리를 쿼리 플래너가 어떻게 실행할지 보기 위해서,
내 도구 상자에 새로운 도구를 추가할 필요가 있었습니다: EXPLAIN QUERY PLAN
SQL 쿼리 앞에 EXPLAIN QUERY PLAN을 붙이거나
쿼리 전에 .eqp on 도트 명령을 실행할 수 있습니다.
어느 쪽이든, 이렇게 생긴 결과를 얻었습니다:
QUERY PLAN|--MATERIALIZE (join-5)| |--SCAN boundary| |--SEARCH threshold USING INTEGER PRIMARY KEY (rowid=?)| |--SEARCH model USING INTEGER PRIMARY KEY (rowid=?)| |--BLOOM FILTER ON alert (boundary_id=?)| `--SEARCH alert USING AUTOMATIC COVERING INDEX (boundary_id=?) LEFT-JOIN|--SEARCH branch USING INDEX sqlite_autoindex_branch_1 (uuid=?)|--SEARCH measure USING INDEX sqlite_autoindex_measure_1 (uuid=?)|--SEARCH benchmark USING INDEX sqlite_autoindex_benchmark_1 (uuid=?)|--SEARCH testbed USING INDEX sqlite_autoindex_testbed_1 (uuid=?)|--SCAN metric|--SEARCH report_benchmark USING INTEGER PRIMARY KEY (rowid=?)|--SEARCH report USING INTEGER PRIMARY KEY (rowid=?)|--SEARCH version USING INTEGER PRIMARY KEY (rowid=?)|--SEARCH branch_version USING COVERING INDEX sqlite_autoindex_branch_version_1 (branch_id=? AND version_id=?)|--BLOOM FILTER ON (join-5) (metric_id=?)|--SEARCH (join-5) USING AUTOMATIC COVERING INDEX (metric_id=?) LEFT-JOIN`--USE TEMP B-TREE FOR ORDER BY오, 보이시나요! 여기에는 많은 것들이 있습니다. 하지만 저에게 눈에 띄는 세 가지 큰 사항은 다음과 같습니다:
- SQLite가
boundary테이블의 전체 를 스캔하는 즉석에서 만들어진 머티리얼라이즈드 뷰를 생성하고 있습니다 - SQLite가 그 다음으로
metric테이블의 전체 를 스캔하고 있습니다 - SQLite가 즉석에서 두 개의 인덱스를 생성하고 있습니다
그렇다면 metric과 boundary 테이블의 크기는 얼마나 될까요?
이들은 바로 가장 큰 두 테이블입니다,
왜냐하면 모든 메트릭과 경계값들이 여기에 저장되기 때문입니다.
SQLite 성능 튜닝의 첫 번째 경험이었기 때문에, 변경을 하기 전에 전문가와 상의하고 싶었습니다.
SQLite 전문가
SQLite에는 .expert 명령어로 활성화할 수 있는 실험적인 “전문가” 모드가 있습니다.
이 모드는 쿼리에 대한 인덱스를 제안하므로, 한번 사용해 보기로 했습니다.
이것이 제안한 것입니다:
CREATE INDEX report_benchmark_idx_fc6f3e5b ON report_benchmark(report_id, benchmark_id);CREATE INDEX report_idx_55aae6d8 ON report(testbed_id, end_time);CREATE INDEX alert_idx_e1882f70 ON alert(boundary_id);
MATERIALIZE (join-5)SCAN boundarySEARCH threshold USING INTEGER PRIMARY KEY (rowid=?)SEARCH model USING INTEGER PRIMARY KEY (rowid=?)SEARCH alert USING INDEX alert_idx_e1882f70 (boundary_id=?) LEFT-JOINSEARCH branch USING INDEX sqlite_autoindex_branch_1 (uuid=?)SEARCH benchmark USING INDEX sqlite_autoindex_benchmark_1 (uuid=?)SEARCH testbed USING INDEX sqlite_autoindex_testbed_1 (uuid=?)SEARCH measure USING INDEX sqlite_autoindex_measure_1 (uuid=?)SEARCH report USING INDEX report_idx_55aae6d8 (testbed_id=? AND end_time<?)SEARCH version USING INTEGER PRIMARY KEY (rowid=?)SEARCH branch_version USING COVERING INDEX sqlite_autoindex_branch_version_1 (branch_id=? AND version_id=?)SEARCH report_benchmark USING INDEX report_benchmark_idx_fc6f3e5b (report_id=? AND benchmark_id=?)SEARCH metric USING INDEX sqlite_autoindex_metric_2 (report_benchmark_id=? AND measure_id=?)BLOOM FILTER ON (join-5) (metric_id=?)SEARCH (join-5) USING AUTOMATIC COVERING INDEX (metric_id=?) LEFT-JOINUSE TEMP B-TREE FOR ORDER BY분명히 개선되었습니다!
metric 테이블에 대한 스캔과 현장에서 생성된 인덱스 두 개를 없앴습니다.
솔직히, 저 혼자서는 처음 두 인덱스를 떠올리지 못했을 겁니다.
고마워요, SQLite 전문가!
CREATE INDEX index_report_testbed_end_time ON report(testbed_id, end_time);CREATE INDEX index_report_benchmark ON report_benchmark(report_id, benchmark_id);CREATE INDEX index_alert_boundary ON alert(boundary_id);이제 남은 것은 그 성가신 현장에서 생성된 머티리얼라이즈드 뷰를 없애는 것뿐입니다.
머티리얼라이즈드 뷰(Materialized View)
지난해 임계 경계를 추적 및 시각화할 수 있는 기능을 추가했을 때,
데이터베이스 모델에서 결정을 내려야 했습니다.
메트릭과 해당 경계 사이에는 1대0 또는 1대1 관계가 있습니다.
즉, 메트릭은 경계와 관련이 없거나 하나의 경계와 관련될 수 있고, 경계는 한 메트릭과만 관련될 수 있습니다.
그래서 metric 테이블을 확장하여 모든 boundary 데이터를 포함시키고, boundary 관련 필드를 모두 null 허용할 수도 있었습니다.
또는 metric 테이블에 UNIQUE 외래 키를 가진 별도의 boundary 테이블을 생성할 수도 있었습니다.
저에게는 후자의 옵션이 훨씬 깔끔해 보였고, 성능 문제는 나중에 언제든지 처리할 수 있을 것이라고 생각했습니다.
metric 테이블과 boundary 테이블을 생성하기 위해 사용된 실제 쿼리는 다음과 같습니다:
CREATE TABLE metric ( id INTEGER PRIMARY KEY NOT NULL, uuid TEXT NOT NULL UNIQUE, report_benchmark_id INTEGER NOT NULL, measure_id INTEGER NOT NULL, value DOUBLE NOT NULL, lower_value DOUBLE, upper_value DOUBLE, FOREIGN KEY (report_benchmark_id) REFERENCES report_benchmark (id) ON DELETE CASCADE, FOREIGN KEY (measure_id) REFERENCES measure (id), UNIQUE(report_benchmark_id, measure_id));CREATE TABLE boundary ( id INTEGER PRIMARY KEY NOT NULL, uuid TEXT NOT NULL UNIQUE, threshold_id INTEGER NOT NULL, statistic_id INTEGER NOT NULL, metric_id INTEGER NOT NULL UNIQUE, baseline DOUBLE NOT NULL, lower_limit DOUBLE, upper_limit DOUBLE, FOREIGN KEY (threshold_id) REFERENCES threshold (id), FOREIGN KEY (statistic_id) REFERENCES statistic (id), FOREIGN KEY (metric_id) REFERENCES metric (id) ON DELETE CASCADE);그리고 “나중”이 도착했습니다.
단순히 boundary(metric_id)에 대한 인덱스를 추가해 보려고 했지만 도움이 되지 않았습니다.
이유는 metric 테이블에서 파생된 Perf 쿼리는
그 관계가 0/1이거나 다시 말해 null 허용이므로 스캔되어야 하고(O(n))
검색할 수는 없다(O(log(n)))는 사실과 관련이 있다고 믿습니다.
이는 저에게 명확한 해결책을 남겼습니다.
SQLite가 동적으로 머티리얼라이즈드 뷰를 생성하는 것을 방지하기 위해
metric과 boundary 관계를 평면화하는 머티리얼라이즈드 뷰를 생성해야 했습니다.
새로운 metric_boundary 머티리얼라이즈드 뷰를 생성하기 위해 사용된 쿼리는 다음과 같습니다:
CREATE VIEW metric_boundary ASSELECT metric.id AS metric_id, metric.uuid AS metric_uuid, metric.report_benchmark_id, metric.measure_id, metric.value, metric.lower_value, metric.upper_value, boundary.id, boundary.uuid AS boundary_uuid, boundary.threshold_id AS threshold_id, boundary.model_id, boundary.baseline, boundary.lower_limit, boundary.upper_limitFROM metric LEFT OUTER JOIN boundary ON (boundary.metric_id = metric.id);이 솔루션으로 공간을 런타임 성능과 교환합니다. 얼마나 많은 공간이냐고요? 놀랍게도 이 뷰는 데이터베이스에서 가장 큰 두 테이블에 대한 것임에도 불구하고 약 4%의 증가에 불과합니다. 최고의 부분은, 이를 통해 소스 코드에서 눈앞의 이익을 얻을 수 있다는 것입니다.
Diesel을 사용하여 머티리얼라이즈드 뷰를 생성하는 것이 놀랍도록 쉬웠습니다. 평소 스키마를 생성할 때 Diesel이 사용하는 정확히 같은 매크로를 사용하기만 하면 됩니다. 이 과정을 통해, 저는 Diesel을 훨씬 더 평가하게 되었습니다. 모든 맛있는 세부 사항은 보너스 버그를 참조하세요.
정리
세 개의 새로운 인덱스와 머티리얼라이즈드 뷰를 추가하면서, 이제 질의 계획자가 보여주는 것은 다음과 같습니다:
QUERY PLAN|--SEARCH branch USING INDEX sqlite_autoindex_branch_1 (uuid=?)|--SEARCH testbed USING INDEX sqlite_autoindex_testbed_1 (uuid=?)|--SEARCH benchmark USING INDEX sqlite_autoindex_benchmark_1 (uuid=?)|--SEARCH measure USING INDEX sqlite_autoindex_measure_1 (uuid=?)|--SEARCH report USING INDEX index_report_testbed_end_time (testbed_id=? AND end_time<?)|--SEARCH version USING INTEGER PRIMARY KEY (rowid=?)|--SEARCH branch_version USING COVERING INDEX sqlite_autoindex_branch_version_1 (branch_id=? AND version_id=?)|--SEARCH report_benchmark USING INDEX index_report_benchmark (report_id=? AND benchmark_id=?)|--SEARCH metric USING INDEX sqlite_autoindex_metric_2 (report_benchmark_id=? AND measure_id=?)|--SEARCH boundary USING INDEX sqlite_autoindex_boundary_2 (metric_id=?) LEFT-JOIN|--SEARCH threshold USING INTEGER PRIMARY KEY (rowid=?) LEFT-JOIN|--SEARCH model USING INTEGER PRIMARY KEY (rowid=?) LEFT-JOIN|--SEARCH alert USING INDEX index_alert_boundary (boundary_id=?) LEFT-JOIN`--USE TEMP B-TREE FOR ORDER BY모든 SEARCH가 기존 인덱스를 사용하여 아름답게 표시됩니다! 🥲
그리고 제 변경 사항을 프로덕션에 배포한 후:
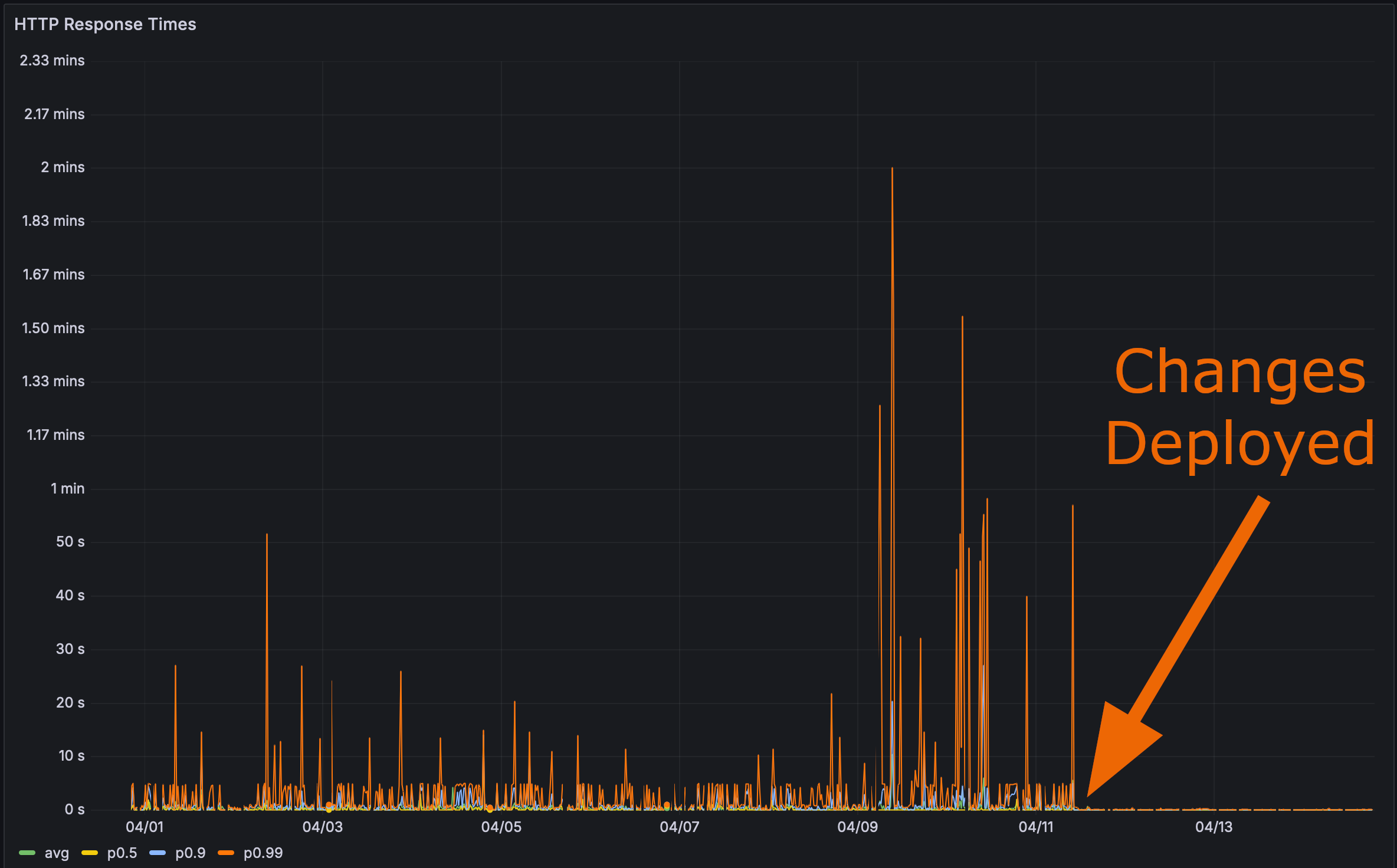
이제 마지막 테스트 시간이었습니다. Rustls Perf 페이지가 얼마나 빨리 로드되는지?
여기 앵커 태그도 드리겠습니다. 클릭하고 나서 페이지를 새로고침하세요.
성능은 중요합니다
Bencher: 지속적인 벤치마킹

Bencher는 지속적인 벤치마킹 도구 모음입니다. 성능 회귀가 사용자에게 영향을 미친 경험이 있나요? Bencher가 그런 일이 일어나는 것을 막을 수 있었습니다. Bencher를 이용하면 성능 회귀를 상용 환경으로 이동하기 전에 탐지하고 예방할 수 있습니다.
- 실행: 기존 벤치마킹 도구를 사용하여 로컬 또는 CI에서 벤치마크를 실행합니다.
bencherCLI는 기존 벤치마킹 하네스를 감싸고 결과를 저장합니다. - 추적: 벤치마크 결과를 시간이 지남에 따라 추적합니다. 소스 브랜치, 테스트 베드, 측정 기반의 Bencher 웹 콘솔을 사용하여 결과를 모니터링, 쿼리, 그래프로 만듭니다.
- 캐치: CI에서 성능 회귀를 잡아냅니다. Bencher는 최첨단, 사용자 정의 가능한 분석을 사용하여 상용 환경으로 가기 전에 성능 회귀를 탐지합니다.
단위 테스트가 CI에서 기능 회귀를 방지하기 위해 실행되는 것처럼, 벤치마크는 Bencher와 함께 CI에서 실행되어 성능 회귀를 방지해야 합니다. 성능 버그도 버그입니다!
CI에서 성능 회귀를 잡아내기 시작하세요 - Bencher Cloud를 무료로 시도해보세요.
도그푸딩에 관한 추가 사항
저는 이미 Bencher로 Bencher를 도그푸딩하고 있지만, 기존의 벤치마크 하네스 어댑터들은 모두 마이크로-벤치마킹 하네스를 위한 것입니다. 대부분의 HTTP 하네스는 실제로 부하 테스트 하네스이며, 부하 테스트는 벤치마킹과 다릅니다. 더욱이, 저는 Bencher를 부하 테스트로 확장할 계획이 없습니다. 그것은 매우 다른 사용 사례이며 예를 들어 시계열 데이터베이스 같은 매우 다른 설계 고려사항을 요구할 것입니다. 심지어 부하 테스트를 갖추고 있다고 하더라도, 이를 발견하기 위해서는 제가 신규로 생성한 프로덕션 데이터에 대해 실행해야 할 것입니다. 이러한 변경으로 인한 성능 차이는 제 테스트 데이터베이스로는 무시할 수 있었습니다.
테스트 데이터베이스 벤치마크 결과 보기
변경 전:
Run Time: real 0.081 user 0.019532 sys 0.005618Run Time: real 0.193 user 0.022192 sys 0.003368Run Time: real 0.070 user 0.021390 sys 0.003369Run Time: real 0.062 user 0.022676 sys 0.002290Run Time: real 0.057 user 0.012053 sys 0.006638Run Time: real 0.052 user 0.018797 sys 0.002016Run Time: real 0.059 user 0.022806 sys 0.002437Run Time: real 0.066 user 0.021869 sys 0.004525Run Time: real 0.060 user 0.021037 sys 0.002864Run Time: real 0.059 user 0.018397 sys 0.003668인덱스 및 머티리얼라이즈드 뷰 변경 후:
Run Time: real 0.063 user 0.008671 sys 0.004898Run Time: real 0.053 user 0.010671 sys 0.003334Run Time: real 0.053 user 0.010337 sys 0.002884Run Time: real 0.052 user 0.008087 sys 0.002165Run Time: real 0.045 user 0.007265 sys 0.002123Run Time: real 0.038 user 0.008793 sys 0.002240Run Time: real 0.040 user 0.011022 sys 0.002420Run Time: real 0.049 user 0.010004 sys 0.002831Run Time: real 0.059 user 0.010472 sys 0.003661Run Time: real 0.046 user 0.009968 sys 0.002628이 모든 것이 저로 하여금 마이크로-벤치마크를 생성하게 했습니다. 그것은 Perf API 엔드포인트에 대해 실행되고 Bencher로 결과를 도그푸딩할 것입니다. 이러한 종류의 성능 회귀를 CI에서 잡을 수 있도록 상당한 크기의 테스트 데이터베이스가 필요할 것입니다. 이 작업을 추적하기 위해 트래킹 이슈를 생성했습니다. 관심이 있다면 따라와 주세요.
이 모든 것이 저를 생각하게 합니다: 만약 여러분이 SQL 데이터베이스 쿼리 플랜의 스냅샷 테스팅을 할 수 있다면 어떨까요? 즉, 현재 대비 후보 SQL 데이터베이스 쿼리 플랜을 비교할 수 있습니다. SQL 쿼리 플랜 테스팅은 데이터베이스를 위한 지침 수 기반의 벤치마킹과 같은 종류가 될 것입니다. 쿼리 플랜은 데이터베이스 쿼리의 런타임 성능에 문제가 있을 수 있음을 나타내는 데 도움이 됩니다. 실제로 데이터베이스 쿼리를 벤치마킹할 필요 없이 말이죠. 이에 대해서도 트래킹 이슈를 생성했습니다. 생각이나 알고 있는 선행 연구에 대해 의견을 추가해 주시면 감사하겠습니다!
보너스 버그
저는 최근에 제 머티리얼라이즈드 뷰 코드에 버그가 있었습니다. 이게 SQL 쿼리의 모습입니다:
SELECT branch.id, branch.uuid, branch.project_id, branch.name, branch.slug, branch.start_point_id, branch.created, branch.modified, testbed.id, testbed.uuid, testbed.project_id, testbed.name, testbed.slug, testbed.created, testbed.modified, benchmark.id, benchmark.uuid, benchmark.project_id, benchmark.name, benchmark.slug, benchmark.created, benchmark.modified, measure.id, measure.uuid, measure.project_id, measure.name, measure.slug, measure.units, measure.created, measure.modified, report.uuid, report_benchmark.iteration, report.start_time, report.end_time, version.number, version.hash, threshold.id, threshold.uuid, threshold.project_id, threshold.measure_id, threshold.branch_id, threshold.testbed_id, threshold.model_id, threshold.created, threshold.modified, model.id, model.uuid, model.threshold_id, model.test, model.min_sample_size, model.max_sample_size, model.window, model.lower_boundary, model.upper_boundary, model.created, model.replaced, alert.id, alert.uuid, alert.boundary_id, alert.boundary_limit, alert.status, alert.modified, metric_boundary.metric_id, metric_boundary.metric_uuid, metric_boundary.report_benchmark_id, metric_boundary.measure_id, metric_boundary.value, metric_boundary.lower_value, metric_boundary.upper_value, metric_boundary.boundary_id, metric_boundary.boundary_uuid, metric_boundary.threshold_id, metric_boundary.model_id, metric_boundary.baseline, metric_boundary.lower_limit, metric_boundary.upper_limit FROM (((((metric_boundary INNER JOIN ((report_benchmark INNER JOIN ((report INNER JOIN (version INNER JOIN (branch_version INNER JOIN branch ON (branch_version.branch_id = branch.id)) ON (branch_version.version_id = version.id)) ON (report.version_id = version.id)) INNER JOIN testbed ON (report.testbed_id = testbed.id)) ON (report_benchmark.report_id = report.id)) INNER JOIN benchmark ON (report_benchmark.benchmark_id = benchmark.id)) ON (metric_boundary.report_benchmark_id = report_benchmark.id)) INNER JOIN measure ON (metric_boundary.measure_id = measure.id)) LEFT OUTER JOIN threshold ON (metric_boundary.threshold_id = threshold.id)) LEFT OUTER JOIN model ON (metric_boundary.model_id = model.id)) LEFT OUTER JOIN alert ON (alert.boundary_id = metric_boundary.metric_id)) WHERE ((((((branch.uuid = 'a7d8366a-4f9b-452e-987e-2ae56e4bf4a3') AND (testbed.uuid = '5b4a6f3e-a27d-4cc3-a2ce-851dc6421e6e')) AND (benchmark.uuid = '88375e7c-f1e0-4cbb-bde1-bdb7773022ae')) AND (measure.uuid = 'b2275bbc-2044-4f8e-aecd-3c739bd861b9')) AND (report.start_time >= 0)) AND (report.end_time <= 1712838648197)) ORDER BY version.number, report.start_time, report_benchmark.iteration;문제를 보시겠나요? 아니요. 저도 못 봤습니다!
문제는 바로 여기에 있습니다:
LEFT OUTER JOIN alert ON (alert.boundary_id = metric_boundary.metric_id)실제로는 이렇게 되어야 하죠:
LEFT OUTER JOIN alert ON (alert.boundary_id = metric_boundary.boundary_id)저는 너무 영리하려고 했는데, 제 Diesel 머티리얼라이즈드 뷰 스키마에서 이 조인을 허용했습니다:
diesel::joinable!(alert -> metric_boundary (boundary_id));저는 이 매크로가 어떻게든 alert.boundary_id를 metric_boundary.boundary_id와 연관짓는지 알아낼 수 있을 거라고 생각했습니다.
하지만 그렇지 않았습니다.
그것은 단지 metric_boundary의 첫 번째 열(metric_id)을 alert과 관련시키는 것처럼 보였습니다.
버그를 발견한 후에는 수정하기 쉬웠습니다. Perf 쿼리에서 명시적 조인을 사용하기만 하면 됐습니다:
.left_join(schema::alert::table.on(view::metric_boundary::boundary_id.eq(schema::alert::boundary_id.nullable())))🐰 여러분, 이게 전부입니다!