Por qué el ajuste de rendimiento de SQLite hizo a Bencher 1200 veces más rápido

Everett Pompeii
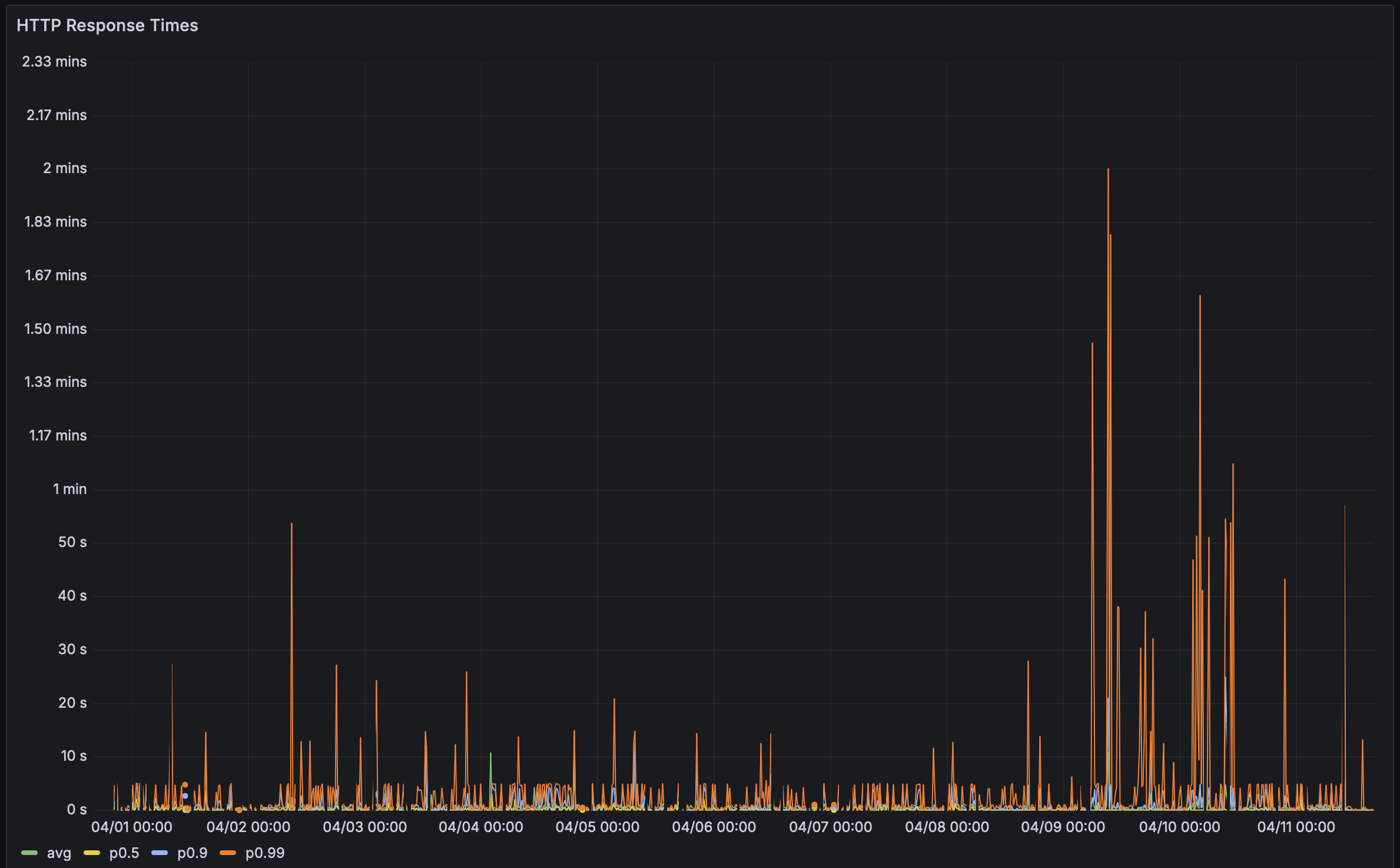
La semana pasada, recibí comentarios de un usuario que decían que su página de rendimiento Bencher tardaba mucho en cargar. Así que decidí comprobarlo, y vaya que estaban siendo amables. ¡Tomó muchísimo tiempo en cargar! Vergonzosamente largo. Especialmente para la herramienta líder de Evaluación Continua de Rendimiento.
En el pasado, he usado la página de rendimiento de Rustls como mi prueba de ácido. Tienen 112 puntos de referencia y una de las configuraciones de Evaluación Continua de Rendimiento más impresionantes que existen. Solía tomar unos 5 segundos en cargar. Esta vez tomó… ⏳👀 … ¡38.8 segundos! Con ese tipo de latencia, tuve que investigar a fondo. ¡Los problemas de rendimiento son fallos, después de todo!
Antecedentes
Desde el principio, sabía que la API Bencher Perf iba a ser uno de los puntos finales más exigentes en términos de rendimiento. Creo que la razón principal por la que muchas personas han tenido que reinventar la rueda del seguimiento de benchmarks es que las herramientas existentes no manejan la alta dimensionalidad requerida. Por “alta dimensionalidad”, me refiero a la capacidad de rastrear el rendimiento a lo largo del tiempo y a través de múltiples dimensiones: Branches, Testbeds, Benchmarks y Medidas. Esta capacidad para cortar y dividir en cinco dimensiones diferentes conduce a un modelo muy complejo.
Debido a esta complejidad inherente y la naturaleza de los datos, consideré usar una base de datos de series temporales para Bencher. Al final, sin embargo, opté por usar SQLite en su lugar. Pensé que era mejor hacer cosas que no escalan en vez de pasar el tiempo extra aprendiendo una arquitectura de base de datos completamente nueva que podría o no ser de ayuda.
Con el tiempo, las demandas en la API de Bencher Perf también han aumentado. Originalmente, tenías que seleccionar todas las dimensiones que querías trazar manualmente. Esto creó mucha fricción para los usuarios para llegar a una trama útil. Para resolver esto, añadí una lista de los Informes más recientes a las Páginas de Perf, y por defecto, se seleccionaba y trazaba el Informe más reciente. Esto significa que si había 112 benchmarks en el Informe más reciente, entonces todos los 112 serían trazados. El modelo también se volvió aún más complicado con la capacidad de rastrear y visualizar Límites de Umbrales.
Con esto en mente, hice algunas mejoras relacionadas con el rendimiento. Dado que el Gráfico de Perf necesita el Informe más reciente para comenzar a trazar, refactoricé la API de Informes para obtener los datos de resultados de un Informe en una sola llamada a la base de datos en lugar de iterar. El intervalo de tiempo para la consulta del Informe predeterminado se estableció en cuatro semanas, en lugar de ser ilimitado. También limité drásticamente el alcance de todos los manejadores de base de datos, reduciendo la contención de bloqueos. Para ayudar a comunicar a los usuarios, añadí un indicador de estado cargando tanto para el Gráfico de Perf como para las pestañas de dimensión.
También tuve un intento fallido el otoño pasado de usar una consulta compuesta para obtener todos los resultados de Perf en una sola consulta, en lugar de usar un bucle anidado cuádruple. Esto me llevó a chocar con el límite de recursión del sistema de tipos de Rust, desbordando repetidamente la pila, sufriendo tiempos de compilación locos (mucho más largos de 38 segundos), y finalmente en un callejón sin salida en el número máximo de términos de SQLite en una declaración select compuesta.
Con todo eso bajo mi cinturón, sabía que realmente necesitaba profundizar aquí y ponerme mis pantalones de ingeniero de rendimiento. Nunca había perfilado una base de datos SQLite antes, y honestamente, realmente nunca había perfilado ninguna base de datos antes. Ahora espera un minuto, podrías estar pensando. Mi perfil de LinkedIn dice que fui “Administrador de Bases de Datos” por casi dos años. ¿Y nunca perfilé una base de datos‽ Sí. Supongo que esa es una historia para otro momento.
De ORM a Consulta SQL
El primer obstáculo con el que me encontré fue obtener la consulta SQL de mi código Rust. Utilizo Diesel como el mapeador objeto-relacional (ORM) para Bencher.
🐰 Dato Curioso: Diesel utiliza Bencher para su Benchmarking Continuo Relativo. ¡Echa un vistazo a la página de rendimiento de Diesel!
Diesel crea consultas parametrizadas.
Envía la consulta SQL y sus parámetros vinculados por separado a la base de datos.
Es decir, la sustitución la realiza la base de datos.
Por lo tanto, Diesel no puede proporcionar una consulta completa al usuario.
El mejor método que encontré fue usar la función diesel::debug_query para obtener la consulta parametrizada:
Query { sql: "SELECT `branch`.`id`, `branch`.`uuid`, `branch`.`project_id`, `branch`.`name`, `branch`.`slug`, `branch`.`start_point_id`, `branch`.`created`, `branch`.`modified`, `testbed`.`id`, `testbed`.`uuid`, `testbed`.`project_id`, `testbed`.`name`, `testbed`.`slug`, `testbed`.`created`, `testbed`.`modified`, `benchmark`.`id`, `benchmark`.`uuid`, `benchmark`.`project_id`, `benchmark`.`name`, `benchmark`.`slug`, `benchmark`.`created`, `benchmark`.`modified`, `measure`.`id`, `measure`.`uuid`, `measure`.`project_id`, `measure`.`name`, `measure`.`slug`, `measure`.`units`, `measure`.`created`, `measure`.`modified`, `report`.`uuid`, `report_benchmark`.`iteration`, `report`.`start_time`, `report`.`end_time`, `version`.`number`, `version`.`hash`, `threshold`.`id`, `threshold`.`uuid`, `threshold`.`project_id`, `threshold`.`measure_id`, `threshold`.`branch_id`, `threshold`.`testbed_id`, `threshold`.`model_id`, `threshold`.`created`, `threshold`.`modified`, `model`.`id`, `model`.`uuid`, `model`.`threshold_id`, `model`.`test`, `model`.`min_sample_size`, `model`.`max_sample_size`, `model`.`window`, `model`.`lower_boundary`, `model`.`upper_boundary`, `model`.`created`, `model`.`replaced`, `boundary`.`id`, `boundary`.`uuid`, `boundary`.`threshold_id`, `boundary`.`model_id`, `boundary`.`metric_id`, `boundary`.`baseline`, `boundary`.`lower_limit`, `boundary`.`upper_limit`, `alert`.`id`, `alert`.`uuid`, `alert`.`boundary_id`, `alert`.`boundary_limit`, `alert`.`status`, `alert`.`modified`, `metric`.`id`, `metric`.`uuid`, `metric`.`report_benchmark_id`, `metric`.`measure_id`, `metric`.`value`, `metric`.`lower_value`, `metric`.`upper_value` FROM (((`metric` INNER JOIN ((`report_benchmark` INNER JOIN ((`report` INNER JOIN (`version` INNER JOIN (`branch_version` INNER JOIN `branch` ON (`branch_version`.`branch_id` = `branch`.`id`)) ON (`branch_version`.`version_id` = `version`.`id`)) ON (`report`.`version_id` = `version`.`id`)) INNER JOIN `testbed` ON (`report`.`testbed_id` = `testbed`.`id`)) ON (`report_benchmark`.`report_id` = `report`.`id`)) INNER JOIN `benchmark` ON (`report_benchmark`.`benchmark_id` = `benchmark`.`id`)) ON (`metric`.`report_benchmark_id` = `report_benchmark`.`id`)) INNER JOIN `measure` ON (`metric`.`measure_id` = `measure`.`id`)) LEFT OUTER JOIN (((`boundary` INNER JOIN `threshold` ON (`boundary`.`threshold_id` = `threshold`.`id`)) INNER JOIN `model` ON (`boundary`.`model_id` = `model`.`id`)) LEFT OUTER JOIN `alert` ON (`alert`.`boundary_id` = `boundary`.`id`)) ON (`boundary`.`metric_id` = `metric`.`id`)) WHERE ((((((`branch`.`uuid` = ?) AND (`testbed`.`uuid` = ?)) AND (`benchmark`.`uuid` = ?)) AND (`measure`.`uuid` = ?)) AND (`report`.`start_time` >= ?)) AND (`report`.`end_time` <= ?)) ORDER BY `version`.`number`, `report`.`start_time`, `report_benchmark`.`iteration`", binds: [BranchUuid(a7d8366a-4f9b-452e-987e-2ae56e4bf4a3), TestbedUuid(5b4a6f3e-a27d-4cc3-a2ce-851dc6421e6e), BenchmarkUuid(88375e7c-f1e0-4cbb-bde1-bdb7773022ae), MeasureUuid(b2275bbc-2044-4f8e-aecd-3c739bd861b9), DateTime(2024-03-12T12:23:38Z), DateTime(2024-04-11T12:23:38Z)] }Y luego limpiar y parametrizar manualmente la consulta en SQL válido:
SELECT branch.id, branch.uuid, branch.project_id, branch.name, branch.slug, branch.start_point_id, branch.created, branch.modified, testbed.id, testbed.uuid, testbed.project_id, testbed.name, testbed.slug, testbed.created, testbed.modified, benchmark.id, benchmark.uuid, benchmark.project_id, benchmark.name, benchmark.slug, benchmark.created, benchmark.modified, measure.id, measure.uuid, measure.project_id, measure.name, measure.slug, measure.units, measure.created, measure.modified, report.uuid, report_benchmark.iteration, report.start_time, report.end_time, version.number, version.hash, threshold.id, threshold.uuid, threshold.project_id, threshold.measure_id, threshold.branch_id, threshold.testbed_id, threshold.model_id, threshold.created, threshold.modified, model.id, model.uuid, model.threshold_id, model.test, model.min_sample_size, model.max_sample_size, model.window, model.lower_boundary, model.upper_boundary, model.created, model.replaced, boundary.id, boundary.uuid, boundary.threshold_id, boundary.model_id, boundary.metric_id, boundary.baseline, boundary.lower_limit, boundary.upper_limit, alert.id, alert.uuid, alert.boundary_id, alert.boundary_limit, alert.status, alert.modified, metric.id, metric.uuid, metric.report_benchmark_id, metric.measure_id, metric.value, metric.lower_value, metric.upper_value FROM (((metric INNER JOIN ((report_benchmark INNER JOIN ((report INNER JOIN (version INNER JOIN (branch_version INNER JOIN branch ON (branch_version.branch_id = branch.id)) ON (branch_version.version_id = version.id)) ON (report.version_id = version.id)) INNER JOIN testbed ON (report.testbed_id = testbed.id)) ON (report_benchmark.report_id = report.id)) INNER JOIN benchmark ON (report_benchmark.benchmark_id = benchmark.id)) ON (metric.report_benchmark_id = report_benchmark.id)) INNER JOIN measure ON (metric.measure_id = measure.id)) LEFT OUTER JOIN (((boundary INNER JOIN threshold ON (boundary.threshold_id = threshold.id)) INNER JOIN model ON (boundary.model_id = model.id)) LEFT OUTER JOIN alert ON (alert.boundary_id = boundary.id)) ON (boundary.metric_id = metric.id)) WHERE ((((((branch.uuid = 'a7d8366a-4f9b-452e-987e-2ae56e4bf4a3') AND (testbed.uuid = '5b4a6f3e-a27d-4cc3-a2ce-851dc6421e6e')) AND (benchmark.uuid = '88375e7c-f1e0-4cbb-bde1-bdb7773022ae')) AND (measure.uuid = 'b2275bbc-2044-4f8e-aecd-3c739bd861b9')) AND (report.start_time >= 0)) AND (report.end_time <= 1712838648197)) ORDER BY version.number, report.start_time, report_benchmark.iteration;Si conoces una mejor manera, ¡por favor házmelo saber! Esta es la forma que el mantenedor del proyecto sugirió sin embargo, así que simplemente seguí con ello. Ahora que tenía una consulta SQL, finalmente estaba listo para… leer muchísima documentación.
Planificador de Consultas SQLite
El sitio web de SQLite tiene una excelente documentación para su Planificador de Consultas. Explica exactamente cómo SQLite ejecuta tu consulta SQL, y te enseña qué índices son útiles y en qué operaciones debes prestar atención, como los escaneos completos de tablas.
Para ver cómo el Planificador de Consultas ejecutaría mi consulta Perf,
necesitaba agregar una nueva herramienta a mi cinturón de herramientas: EXPLAIN QUERY PLAN
Puedes prefijar tu consulta SQL con EXPLAIN QUERY PLAN
o ejecutar el comando de punto .eqp on antes de tu consulta.
De cualquier manera, obtuve un resultado que se ve así:
QUERY PLAN|--MATERIALIZE (join-5)| |--SCAN boundary| |--SEARCH threshold USING INTEGER PRIMARY KEY (rowid=?)| |--SEARCH model USING INTEGER PRIMARY KEY (rowid=?)| |--BLOOM FILTER ON alert (boundary_id=?)| `--SEARCH alert USING AUTOMATIC COVERING INDEX (boundary_id=?) LEFT-JOIN|--SEARCH branch USING INDEX sqlite_autoindex_branch_1 (uuid=?)|--SEARCH measure USING INDEX sqlite_autoindex_measure_1 (uuid=?)|--SEARCH benchmark USING INDEX sqlite_autoindex_benchmark_1 (uuid=?)|--SEARCH testbed USING INDEX sqlite_autoindex_testbed_1 (uuid=?)|--SCAN metric|--SEARCH report_benchmark USING INTEGER PRIMARY KEY (rowid=?)|--SEARCH report USING INTEGER PRIMARY KEY (rowid=?)|--SEARCH version USING INTEGER PRIMARY KEY (rowid=?)|--SEARCH branch_version USING COVERING INDEX sqlite_autoindex_branch_version_1 (branch_id=? AND version_id=?)|--BLOOM FILTER ON (join-5) (metric_id=?)|--SEARCH (join-5) USING AUTOMATIC COVERING INDEX (metric_id=?) LEFT-JOIN`--USE TEMP B-TREE FOR ORDER BY¡Vaya! Hay mucho aquí. Pero las tres grandes cosas que me llamaron la atención fueron:
- SQLite está creando una vista materializada al vuelo que escanea la tabla
boundarycompleta - Luego, SQLite está escaneando la tabla
metriccompleta - SQLite está creando dos índices al vuelo
¿Y qué tan grandes son las tablas metric y boundary?
Bueno, resulta que son las dos tablas más grandes,
ya que es donde se almacenan todos los Métricos y Límites.
Dado que este era mi primer rodeo de ajuste de rendimiento de SQLite, quería consultar a un experto antes de hacer cualquier cambio.
Experto en SQLite
SQLite tiene un modo “experto” experimental que puede habilitarse con el comando .expert.
Sugiere índices para consultas, así que decidí probarlo.
Esto es lo que sugirió:
CREATE INDEX report_benchmark_idx_fc6f3e5b ON report_benchmark(report_id, benchmark_id);CREATE INDEX report_idx_55aae6d8 ON report(testbed_id, end_time);CREATE INDEX alert_idx_e1882f70 ON alert(boundary_id);
MATERIALIZE (join-5)SCAN boundarySEARCH threshold USING INTEGER PRIMARY KEY (rowid=?)SEARCH model USING INTEGER PRIMARY KEY (rowid=?)SEARCH alert USING INDEX alert_idx_e1882f70 (boundary_id=?) LEFT-JOINSEARCH branch USING INDEX sqlite_autoindex_branch_1 (uuid=?)SEARCH benchmark USING INDEX sqlite_autoindex_benchmark_1 (uuid=?)SEARCH testbed USING INDEX sqlite_autoindex_testbed_1 (uuid=?)SEARCH measure USING INDEX sqlite_autoindex_measure_1 (uuid=?)SEARCH report USING INDEX report_idx_55aae6d8 (testbed_id=? AND end_time<?)SEARCH version USING INTEGER PRIMARY KEY (rowid=?)SEARCH branch_version USING COVERING INDEX sqlite_autoindex_branch_version_1 (branch_id=? AND version_id=?)SEARCH report_benchmark USING INDEX report_benchmark_idx_fc6f3e5b (report_id=? AND benchmark_id=?)SEARCH metric USING INDEX sqlite_autoindex_metric_2 (report_benchmark_id=? AND measure_id=?)BLOOM FILTER ON (join-5) (metric_id=?)SEARCH (join-5) USING AUTOMATIC COVERING INDEX (metric_id=?) LEFT-JOINUSE TEMP B-TREE FOR ORDER BY¡Definitivamente es una mejora!
Eliminó el escaneo de la tabla metric y ambos índices creados al vuelo.
Honestamente, yo no habría logrado obtener los primeros dos índices por mi cuenta.
¡Gracias, Experto en SQLite!
CREATE INDEX index_report_testbed_end_time ON report(testbed_id, end_time);CREATE INDEX index_report_benchmark ON report_benchmark(report_id, benchmark_id);CREATE INDEX index_alert_boundary ON alert(boundary_id);Ahora lo único que queda por eliminar es esa maldita vista materializada creada al vuelo.
Vista Materializada
Cuando agregué la capacidad de rastrear y visualizar los Límites de Umbral el año pasado,
tuve que tomar una decisión en el modelo de la base de datos.
Existe una relación de 1-a-0/1 entre una Métrica y su Límite correspondiente.
Es decir, una Métrica puede relacionarse con cero o un Límite, y un Límite solo puede relacionarse con una Métrica.
Por lo tanto, podría haber simplemente expandido la tabla metric para incluir todos los datos de boundary con cada campo relacionado a boundary siendo nulable.
O podría crear una tabla boundary separada con una clave foránea UNIQUE a la tabla metric.
Para mí, la última opción se sintió mucho más limpia, y pensé que siempre podría ocuparme de cualquier implicación de rendimiento más tarde.
Estas fueron las consultas efectivas usadas para crear las tablas metric y boundary:
CREATE TABLE metric ( id INTEGER PRIMARY KEY NOT NULL, uuid TEXT NOT NULL UNIQUE, report_benchmark_id INTEGER NOT NULL, measure_id INTEGER NOT NULL, value DOUBLE NOT NULL, lower_value DOUBLE, upper_value DOUBLE, FOREIGN KEY (report_benchmark_id) REFERENCES report_benchmark (id) ON DELETE CASCADE, FOREIGN KEY (measure_id) REFERENCES measure (id), UNIQUE(report_benchmark_id, measure_id));CREATE TABLE boundary ( id INTEGER PRIMARY KEY NOT NULL, uuid TEXT NOT NULL UNIQUE, threshold_id INTEGER NOT NULL, statistic_id INTEGER NOT NULL, metric_id INTEGER NOT NULL UNIQUE, baseline DOUBLE NOT NULL, lower_limit DOUBLE, upper_limit DOUBLE, FOREIGN KEY (threshold_id) REFERENCES threshold (id), FOREIGN KEY (statistic_id) REFERENCES statistic (id), FOREIGN KEY (metric_id) REFERENCES metric (id) ON DELETE CASCADE);Y resulta que “más tarde” había llegado.
Intenté simplemente agregar un índice para boundary(metric_id) pero eso no ayudó.
Creo que la razón tiene que ver con el hecho de que la consulta Perf se origina en la tabla metric
y porque esa relación es 0/1 o dicho de otro modo, nulable, tiene que ser escaneada (O(n))
y no puede ser buscada (O(log(n))).
Esto me dejó con una opción clara.
Necesitaba crear una vista materializada que aplanara la relación metric y boundary
para evitar que SQLite tenga que crear una vista materializada al vuelo.
Esta es la consulta que usé para crear la nueva vista materializada metric_boundary:
CREATE VIEW metric_boundary ASSELECT metric.id AS metric_id, metric.uuid AS metric_uuid, metric.report_benchmark_id, metric.measure_id, metric.value, metric.lower_value, metric.upper_value, boundary.id, boundary.uuid AS boundary_uuid, boundary.threshold_id AS threshold_id, boundary.model_id, boundary.baseline, boundary.lower_limit, boundary.upper_limitFROM metric LEFT OUTER JOIN boundary ON (boundary.metric_id = metric.id);Con esta solución, estoy intercambiando espacio por rendimiento en tiempo de ejecución. ¿Cuánto espacio? Sorprendentemente, solo alrededor de un 4% de aumento, a pesar de que esta vista es para las dos tablas más grandes en la base de datos. Lo mejor de todo, es que me permite tener todo lo que quiero en mi código fuente.
Crear una vista materializada con Diesel fue sorprendentemente fácil. Solo tuve que usar las mismas macros que Diesel utiliza cuando genero mi esquema normal. Dicho esto, aprendí a apreciar mucho más a Diesel a lo largo de esta experiencia. Consulta Error Adicional para todos los detalles jugosos.
Conclusión
Con los tres nuevos índices y una vista materializada añadidos, esto es lo que ahora muestra el Planificador de Consultas:
QUERY PLAN|--SEARCH branch USING INDEX sqlite_autoindex_branch_1 (uuid=?)|--SEARCH testbed USING INDEX sqlite_autoindex_testbed_1 (uuid=?)|--SEARCH benchmark USING INDEX sqlite_autoindex_benchmark_1 (uuid=?)|--SEARCH measure USING INDEX sqlite_autoindex_measure_1 (uuid=?)|--SEARCH report USING INDEX index_report_testbed_end_time (testbed_id=? AND end_time<?)|--SEARCH version USING INTEGER PRIMARY KEY (rowid=?)|--SEARCH branch_version USING COVERING INDEX sqlite_autoindex_branch_version_1 (branch_id=? AND version_id=?)|--SEARCH report_benchmark USING INDEX index_report_benchmark (report_id=? AND benchmark_id=?)|--SEARCH metric USING INDEX sqlite_autoindex_metric_2 (report_benchmark_id=? AND measure_id=?)|--SEARCH boundary USING INDEX sqlite_autoindex_boundary_2 (metric_id=?) LEFT-JOIN|--SEARCH threshold USING INTEGER PRIMARY KEY (rowid=?) LEFT-JOIN|--SEARCH model USING INTEGER PRIMARY KEY (rowid=?) LEFT-JOIN|--SEARCH alert USING INDEX index_alert_boundary (boundary_id=?) LEFT-JOIN`--USE TEMP B-TREE FOR ORDER BY¡Mira todas esas búsquedas SEARCH hermosas, todas con índices existentes! 🥲
Y después de desplegar mis cambios en producción:
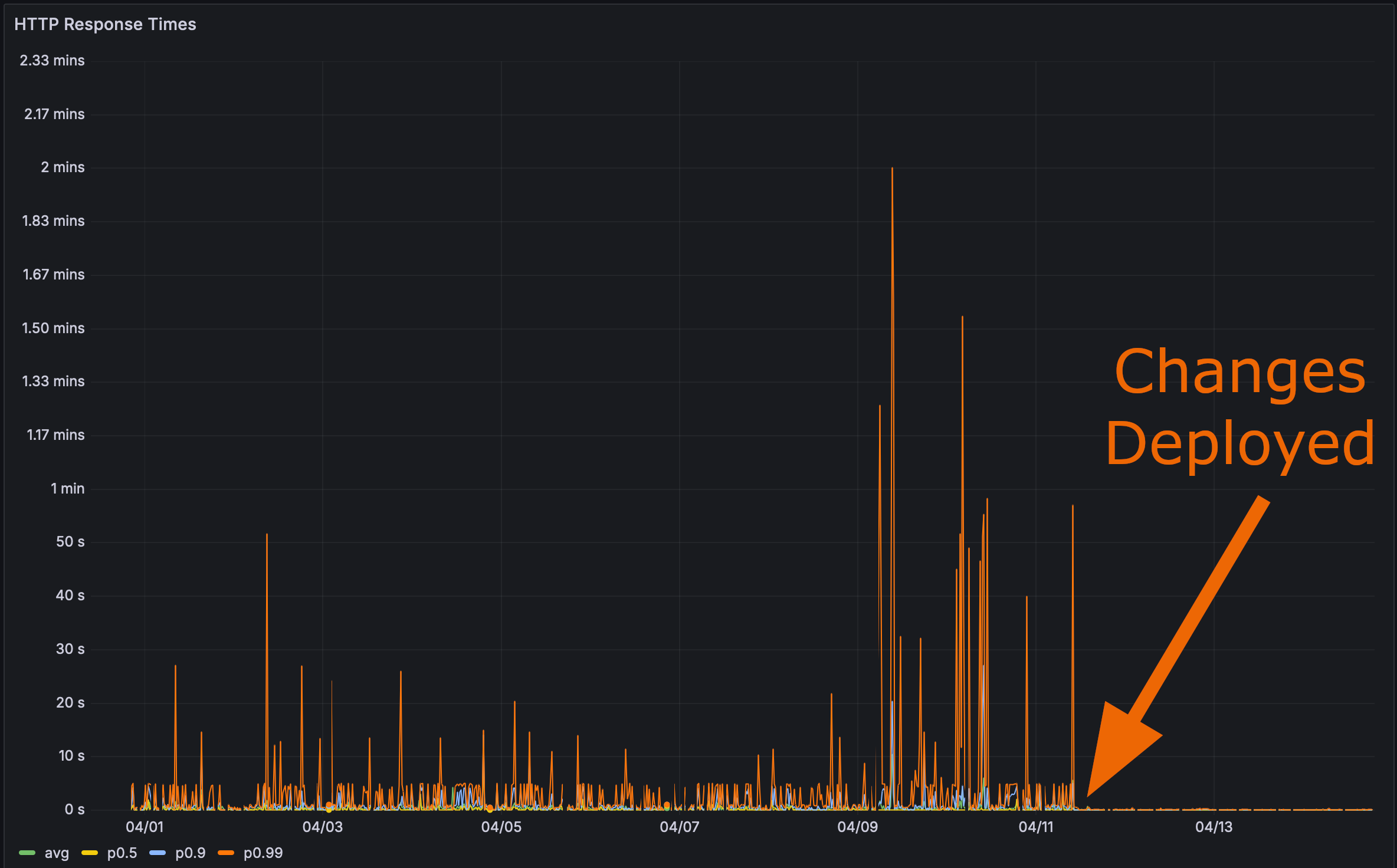
Ahora era el momento de la prueba final. ¿Qué tan rápido carga esa página de Perf de Rustls?
Aquí incluso te daré una etiqueta de anclaje. Haz clic en ella y luego actualiza la página.
El Rendimiento Importa
Bencher: Benchmarking continuo

Bencher es un conjunto de herramientas de benchmarking continuo. ¿Alguna vez has tenido un impacto de regresión de rendimiento en tus usuarios? Bencher podría haber evitado que eso sucediera. Bencher te permite detectar y prevenir las regresiones de rendimiento antes de que lleguen a producción.
- Ejecutar: Ejecute sus benchmarks localmente o en CI usando sus herramientas de benchmarking favoritas. La CLI
benchersimplemente envuelve su arnés de benchmarks existente y almacena sus resultados. - Seguir: Sigue los resultados de tus benchmarks con el tiempo. Monitoriza, realiza consultas y representa gráficamente los resultados utilizando la consola web de Bencher basándose en la rama de origen, el banco de pruebas y la medida.
- Capturar: Captura las regresiones de rendimiento en CI. Bencher utiliza analíticas de vanguardia y personalizables para detectar regresiones de rendimiento antes de que lleguen a producción.
Por las mismas razones que las pruebas unitarias se ejecutan en CI para prevenir regresiones funcionales, los benchmarks deberían ejecutarse en CI con Bencher para prevenir regresiones de rendimiento. ¡Los errores de rendimiento son errores!
Empiece a capturar regresiones de rendimiento en CI — prueba Bencher Cloud gratis.
Addendum sobre Dogfooding
Ya estoy utilizando Bencher con Bencher, pero todos los adaptadores de arneses de referencia existentes son para arneses de micro-referencia. La mayoría de los arneses HTTP son realmente arneses de pruebas de carga, y las pruebas de carga son diferentes de las pruebas de rendimiento. Además, no estoy buscando expandir Bencher a pruebas de carga en el corto plazo. Ese es un caso de uso muy diferente que requeriría consideraciones de diseño muy distintas, como esa base de datos de series temporales, por ejemplo. Incluso si tuviera pruebas de carga en lugar, realmente necesitaría estar ejecutándolas contra una extracción reciente de datos de producción para que esto se hubiera detectado. Las diferencias de rendimiento para estos cambios fueron insignificantes con mi base de datos de prueba.
Haz clic para ver los resultados de la referencia de la base de datos de prueba
Antes:
Run Time: real 0.081 user 0.019532 sys 0.005618Run Time: real 0.193 user 0.022192 sys 0.003368Run Time: real 0.070 user 0.021390 sys 0.003369Run Time: real 0.062 user 0.022676 sys 0.002290Run Time: real 0.057 user 0.012053 sys 0.006638Run Time: real 0.052 user 0.018797 sys 0.002016Run Time: real 0.059 user 0.022806 sys 0.002437Run Time: real 0.066 user 0.021869 sys 0.004525Run Time: real 0.060 user 0.021037 sys 0.002864Run Time: real 0.059 user 0.018397 sys 0.003668Después de índices y vista materializada:
Run Time: real 0.063 user 0.008671 sys 0.004898Run Time: real 0.053 user 0.010671 sys 0.003334Run Time: real 0.053 user 0.010337 sys 0.002884Run Time: real 0.052 user 0.008087 sys 0.002165Run Time: real 0.045 user 0.007265 sys 0.002123Run Time: real 0.038 user 0.008793 sys 0.002240Run Time: real 0.040 user 0.011022 sys 0.002420Run Time: real 0.049 user 0.010004 sys 0.002831Run Time: real 0.059 user 0.010472 sys 0.003661Run Time: real 0.046 user 0.009968 sys 0.002628Todo esto me lleva a creer que debería crear un micro-referencia que se ejecute contra el punto final de la API de Perf y utilizar los resultados con Bencher. Esto requerirá una base de datos de prueba considerable para asegurarse de que este tipo de regresiones de rendimiento se detecten en CI. He creado un problema de seguimiento para este trabajo, si te gustaría seguir el progreso.
Todo esto me ha hecho pensar: ¿Y si pudieras hacer [pruebas de instantáneas][snapshot testing] del plan de consulta de tu base de datos SQL? Es decir, podrías comparar tus planes de consulta de base de datos SQL actuales versus candidatos. Las pruebas de plan de consulta SQL serían algo así como referencias basadas en el conteo de instrucciones para bases de datos. El plan de consulta ayuda a indicar que puede haber un problema con el rendimiento en tiempo de ejecución, sin tener que referenciar realmente la consulta de la base de datos. También he creado un problema de seguimiento para esto. ¡Por favor, siéntete libre de agregar un comentario con tus pensamientos o cualquier trabajo previo que conozcas!
Bono por Error
Originalmente tenía un error en mi código de vista materializada. Así se veía la consulta SQL:
SELECT branch.id, branch.uuid, branch.project_id, branch.name, branch.slug, branch.start_point_id, branch.created, branch.modified, testbed.id, testbed.uuid, testbed.project_id, testbed.name, testbed.slug, testbed.created, testbed.modified, benchmark.id, benchmark.uuid, benchmark.project_id, benchmark.name, benchmark.slug, benchmark.created, benchmark.modified, measure.id, measure.uuid, measure.project_id, measure.name, measure.slug, measure.units, measure.created, measure.modified, report.uuid, report_benchmark.iteration, report.start_time, report.end_time, version.number, version.hash, threshold.id, threshold.uuid, threshold.project_id, threshold.measure_id, threshold.branch_id, threshold.testbed_id, threshold.model_id, threshold.created, threshold.modified, model.id, model.uuid, model.threshold_id, model.test, model.min_sample_size, model.max_sample_size, model.window, model.lower_boundary, model.upper_boundary, model.created, model.replaced, alert.id, alert.uuid, alert.boundary_id, alert.boundary_limit, alert.status, alert.modified, metric_boundary.metric_id, metric_boundary.metric_uuid, metric_boundary.report_benchmark_id, metric_boundary.measure_id, metric_boundary.value, metric_boundary.lower_value, metric_boundary.upper_value, metric_boundary.boundary_id, metric_boundary.boundary_uuid, metric_boundary.threshold_id, metric_boundary.model_id, metric_boundary.baseline, metric_boundary.lower_limit, metric_boundary.upper_limit FROM (((((metric_boundary INNER JOIN ((report_benchmark INNER JOIN ((report INNER JOIN (version INNER JOIN (branch_version INNER JOIN branch ON (branch_version.branch_id = branch.id)) ON (branch_version.version_id = version.id)) ON (report.version_id = version.id)) INNER JOIN testbed ON (report.testbed_id = testbed.id)) ON (report_benchmark.report_id = report.id)) INNER JOIN benchmark ON (report_benchmark.benchmark_id = benchmark.id)) ON (metric_boundary.report_benchmark_id = report_benchmark.id)) INNER JOIN measure ON (metric_boundary.measure_id = measure.id)) LEFT OUTER JOIN threshold ON (metric_boundary.threshold_id = threshold.id)) LEFT OUTER JOIN model ON (metric_boundary.model_id = model.id)) LEFT OUTER JOIN alert ON (alert.boundary_id = metric_boundary.metric_id)) WHERE ((((((branch.uuid = 'a7d8366a-4f9b-452e-987e-2ae56e4bf4a3') AND (testbed.uuid = '5b4a6f3e-a27d-4cc3-a2ce-851dc6421e6e')) AND (benchmark.uuid = '88375e7c-f1e0-4cbb-bde1-bdb7773022ae')) AND (measure.uuid = 'b2275bbc-2044-4f8e-aecd-3c739bd861b9')) AND (report.start_time >= 0)) AND (report.end_time <= 1712838648197)) ORDER BY version.number, report.start_time, report_benchmark.iteration;¿Ves el problema? No. ¡Yo tampoco!
El problema está justo aquí:
LEFT OUTER JOIN alert ON (alert.boundary_id = metric_boundary.metric_id)De hecho, debería ser:
LEFT OUTER JOIN alert ON (alert.boundary_id = metric_boundary.boundary_id)Estaba intentando ser demasiado inteligente, y en mi esquema de vista materializada de Diesel había permitido esta unión:
diesel::joinable!(alert -> metric_boundary (boundary_id));Asumí que esta macro de alguna manera era lo suficientemente inteligente
para relacionar el alert.boundary_id con el metric_boundary.boundary_id.
Pero lamentablemente, no fue así.
Parece que simplemente eligió la primera columna de metric_boundary (metric_id) para relacionarla con alert.
Una vez que descubrí el error, fue fácil de arreglar. Solo tuve que usar una unión explícita en la consulta de Perf:
.left_join(schema::alert::table.on(view::metric_boundary::boundary_id.eq(schema::alert::boundary_id.nullable())))🐰 ¡Eso es todo, amigos!